 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Music Emotion Recognition across Dimensional and Categorical Models
Feb 06, 2025



One of the most significant challenges in Music Emotion Recognition (MER) comes from the fact that emotion labels can be heterogeneous across datasets with regard to the emotion representation, including categorical (e.g., happy, sad) versus dimensional labels (e.g., valence-arousal). In this paper, we present a unified multitask learning framework that combines these two types of labels and is thus able to be trained on multiple datasets. This framework uses an effective input representation that combines musical features (i.e., key and chords) and MERT embeddings. Moreover, knowledge distillation is employed to transfer the knowledge of teacher models trained on individual datasets to a student model, enhancing its ability to generalize across multiple tasks. To validate our proposed framework, we conducted extensive experiments on a variety of datasets, including MTG-Jamendo, DEAM, PMEmo, and EmoMusic. According to our experimental results, the inclusion of musical features, multitask learning, and knowledge distillation significantly enhances performance. In particular, our model outperforms the state-of-the-art models, including the best-performing model from the MediaEval 2021 competition on the MTG-Jamendo dataset. Our work makes a significant contribution to MER by allowing the combination of categorical and dimensional emotion labels in one unified framework, thus enabling training across datasets.
Are we there yet? A brief survey of Music Emotion Prediction Datasets, Models and Outstanding Challenges
Jun 13, 2024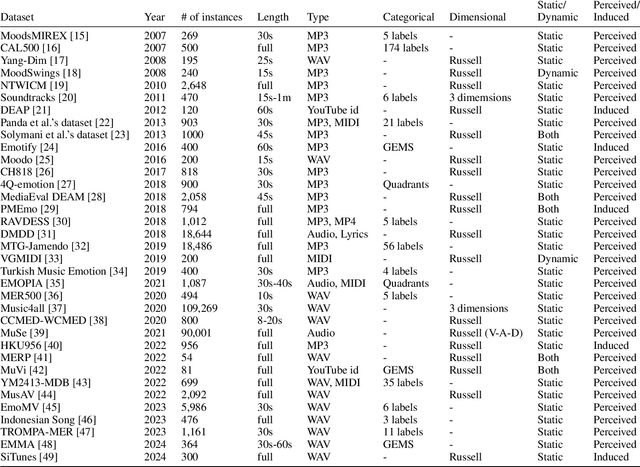
Deep learning models for music have advanced drastically in the last few years. But how good are machine learning models at capturing emotion these days and what challenges are researchers facing? In this paper, we provide a comprehensive overview of the available music-emotion datasets and discuss evaluation standards as well as competitions in the field. We also provide a brief overview of various types of music emotion prediction models that have been built over the years, offering insights into the diverse approaches within the field. Through this examination, we highlight the challenges that persist in accurately capturing emotion in music. Recognizing the dynamic nature of this field, we have complemented our findings with an accompanying GitHub repository. This repository contains a comprehensive list of music emotion datasets and recent predictive models.
Video2Music: Suitable Music Generation from Videos using an Affective Multimodal Transformer model
Nov 02, 2023



Numerous studies in the field of music generation have demonstrated impressive performance, yet virtually no models are able to directly generate music to match accompanying videos. In this work, we develop a generative music AI framework, Video2Music, that can match a provided video. We first curated a unique collection of music videos. Then, we analysed the music videos to obtain semantic, scene offset, motion, and emotion features. These distinct features are then employed as guiding input to our music generation model. We transcribe the audio files into MIDI and chords, and extract features such as note density and loudness. This results in a rich multimodal dataset, called MuVi-Sync, on which we train a novel Affective Multimodal Transformer (AMT) model to generate music given a video. This model includes a novel mechanism to enforce affective similarity between video and music. Finally, post-processing is performed based on a biGRU-based regression model to estimate note density and loudness based on the video features. This ensures a dynamic rendering of the generated chords with varying rhythm and volume. In a thorough experiment, we show that our proposed framework can generate music that matches the video content in terms of emotion. The musical quality, along with the quality of music-video matching is confirmed in a user study. The proposed AMT model, along with the new MuVi-Sync dataset, presents a promising step for the new task of music generation for videos.