 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUMAA: Repeat-Aware Unified Music Audio Analysis for Score-Performance Alignment, Transcription, and Mistake Detection
Jul 16, 2025This study introduces RUMAA, a transformer-based framework for music performance analysis that unifies score-to-performance alignment, score-informed transcription, and mistake detection in a near end-to-end manner. Unlike prior methods addressing these tasks separately, RUMAA integrates them using pre-trained score and audio encoders and a novel tri-stream decoder capturing task interdependencies through proxy tasks. It aligns human-readable MusicXML scores with repeat symbols to full-length performance audio, overcoming traditional MIDI-based methods that rely on manually unfolded score-MIDI data with pre-specified repeat structures. RUMAA matches state-of-the-art alignment methods on non-repeated scores and outperforms them on scores with repeats in a public piano music dataset, while also delivering promising transcription and mistake detection results.
ImprovNet: Generating Controllable Musical Improvisations with Iterative Corruption Refinement
Feb 06, 2025



Deep learning has enabled remarkable advances in style transfer across various domains, offering new possibilities for creative content generation. However, in the realm of symbolic music, generating controllable and expressive performance-level style transfers for complete musical works remains challenging due to limited datasets, especially for genres such as jazz, and the lack of unified models that can handle multiple music generation tasks. This paper presents ImprovNet, a transformer-based architecture that generates expressive and controllable musical improvisations through a self-supervised corruption-refinement training strategy. ImprovNet unifies multiple capabilities within a single model: it can perform cross-genre and intra-genre improvisations, harmonize melodies with genre-specific styles, and execute short prompt continuation and infilling tasks. The model's iterative generation framework allows users to control the degree of style transfer and structural similarity to the original composition. Objective and subjective evaluations demonstrate ImprovNet's effectiveness in generating musically coherent improvisations while maintaining structural relationships with the original pieces. The model outperforms Anticipatory Music Transformer in short continuation and infilling tasks and successfully achieves recognizable genre conversion, with 79\% of participants correctly identifying jazz-style improvisations. Our code and demo page can be found at https://github.com/keshavbhandari/improvnet.
YourMT3+: Multi-instrument Music Transcription with Enhanced Transformer Architectures and Cross-dataset Stem Augmentation
Jul 05, 2024


Multi-instrument music transcription aims to convert polyphonic music recordings into musical scores assigned to each instrument. This task is challenging for modeling as it requires simultaneously identifying multiple instruments and transcribing their pitch and precise timing, and the lack of fully annotated data adds to the training difficulties. This paper introduces YourMT3+, a suite of models for enhanced multi-instrument music transcription based on the recent language token decoding approach of MT3. We strengthen its encoder by adopting a hierarchical attention transformer in the time-frequency domain and integrating a mixture of experts (MoE). To address data limitations, we introduce a new multi-channel decoding method for training with incomplete annotations and propose intra- and cross-stem augmentation for dataset mixing. Our experiments demonstrate direct vocal transcription capabilities, eliminating the need for voice separation pre-processors. Benchmarks across ten public datasets show our models' competitiveness with, or superiority to, existing transcription models. Further testing on pop music recordings highlights the limitations of current models. Fully reproducible code and datasets are available at \url{https://github.com/mimbres/YourMT3}
Offline Clustering Approach to Self-supervised Learning for Class-imbalanced Image Data
Dec 22, 2022



Class-imbalanced datasets are known to cause the problem of model being biased towards the majority classes. In this project, we set up two research questions: 1) when is the class-imbalance problem more prevalent in self-supervised pre-training? and 2) can offline clustering of feature representations help pre-training on class-imbalanced data? Our experiments investigate the former question by adjusting the degree of {\it class-imbalance} when training the baseline models, namely SimCLR and SimSiam on CIFAR-10 database. To answer the latter question, we train each expert model on each subset of the feature clusters. We then distill the knowledge of expert models into a single model, so that we will be able to compare the performance of this model to our baselines.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 28, 2020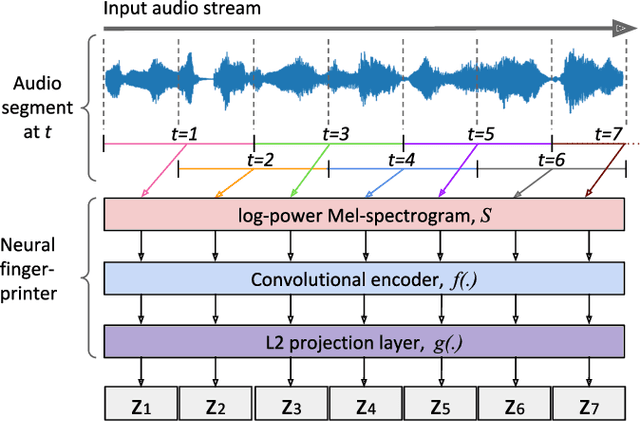

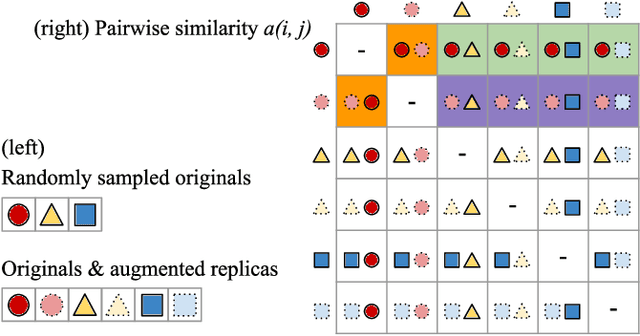
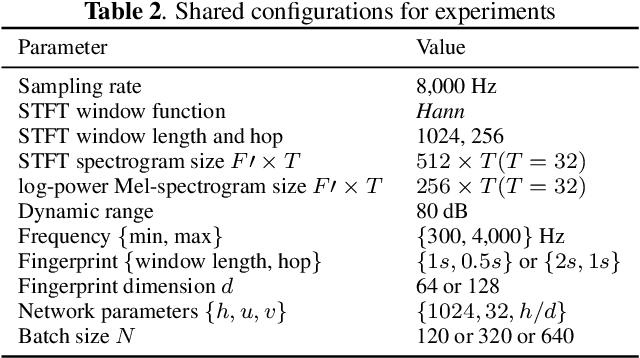
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.
Sequential Skip Prediction with Few-shot in Streamed Music Contents
Jan 24, 2019
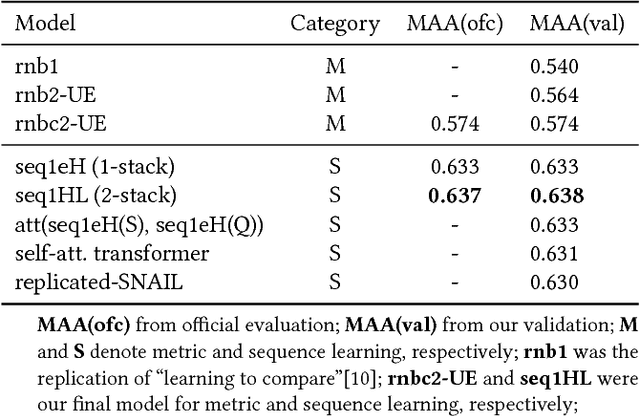

This paper provides an outline of the algorithms submitted for the WSDM Cup 2019 Spotify Sequential Skip Prediction Challenge (team name: mimbres). In the challenge, complete information including acoustic features and user interaction logs for the first half of a listening session is provided. Our goal is to predict whether the individual tracks in the second half of the session will be skipped or not, only given acoustic features. We proposed two different kinds of algorithms that were based on metric learning and sequence learning. The experimental results showed that the sequence learning approach performed significantly better than the metric learning approach. Moreover, we conducted additional experiments to find that significant performance gain can be achieved using complete user log information.
Audio Cover Song Identification using Convolutional Neural Network
Dec 01, 2017



In this paper, we propose a new approach to cover song identification using a CNN (convolutional neural network). Most previous studies extract the feature vectors that characterize the cover song relation from a pair of songs and used it to compute the (dis)similarity between the two songs. Based on the observation that there is a meaningful pattern between cover songs and that this can be learned, we have reformulated the cover song identification problem in a machine learning framework. To do this, we first build the CNN using as an input a cross-similarity matrix generated from a pair of songs. We then construct the data set composed of cover song pairs and non-cover song pairs, which are used as positive and negative training samples, respectively. The trained CNN outputs the probability of being in the cover song relation given a cross-similarity matrix generated from any two pieces of music and identifies the cover song by ranking on the probability. Experimental results show that the proposed algorithm achieves performance better than or comparable to the state-of-the-art.
Lyrics-to-Audio Alignment by Unsupervised Discovery of Repetitive Patterns in Vowel Acoustics
Jan 24, 2017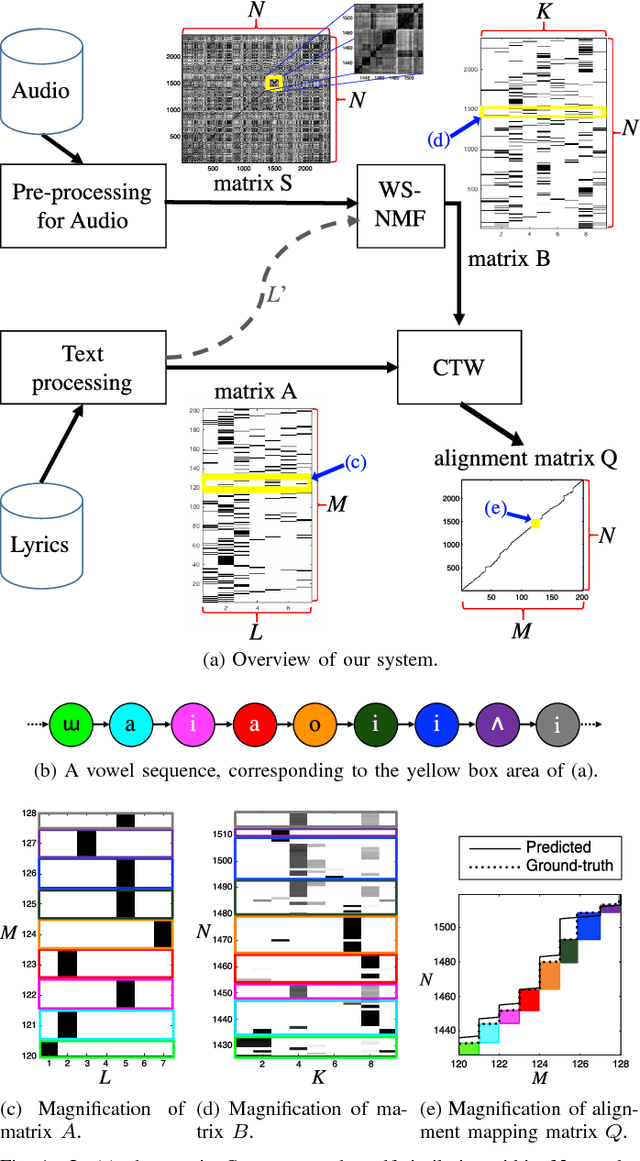
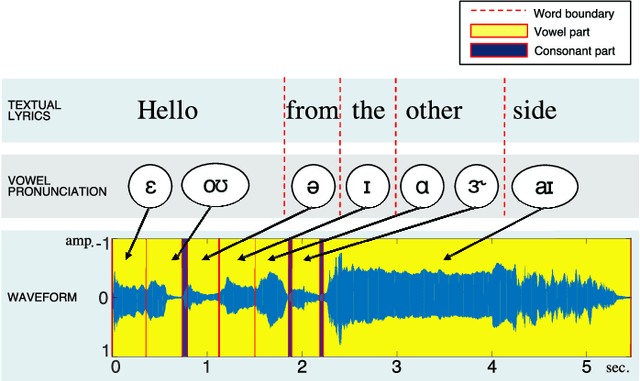
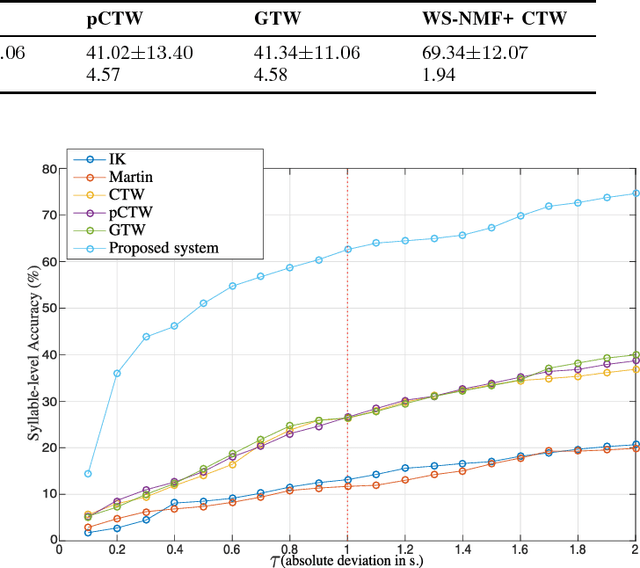
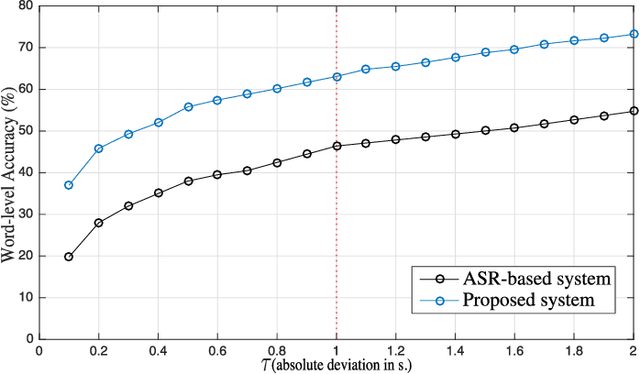
Most of the previous approaches to lyrics-to-audio alignment used a pre-developed automatic speech recognition (ASR) system that innately suffered from several difficulties to adapt the speech model to individual singers. A significant aspect missing in previous works is the self-learnability of repetitive vowel patterns in the singing voice, where the vowel part used is more consistent than the consonant part. Based on this, our system first learns a discriminative subspace of vowel sequences, based on weighted symmetric non-negative matrix factorization (WS-NMF), by taking the self-similarity of a standard acoustic feature as an input. Then, we make use of canonical time warping (CTW), derived from a recent computer vision technique, to find an optimal spatiotemporal transformation between the text and the acoustic sequences. Experiments with Korean and English data sets showed that deploying this method after a pre-developed, unsupervised, singing source separation achieved more promising results than other state-of-the-art unsupervised approaches and an existing ASR-based system.
* 13 pages