 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovNet: Generating Controllable Musical Improvisations with Iterative Corruption Refinement
Feb 06, 2025



Deep learning has enabled remarkable advances in style transfer across various domains, offering new possibilities for creative content generation. However, in the realm of symbolic music, generating controllable and expressive performance-level style transfers for complete musical works remains challenging due to limited datasets, especially for genres such as jazz, and the lack of unified models that can handle multiple music generation tasks. This paper presents ImprovNet, a transformer-based architecture that generates expressive and controllable musical improvisations through a self-supervised corruption-refinement training strategy. ImprovNet unifies multiple capabilities within a single model: it can perform cross-genre and intra-genre improvisations, harmonize melodies with genre-specific styles, and execute short prompt continuation and infilling tasks. The model's iterative generation framework allows users to control the degree of style transfer and structural similarity to the original composition. Objective and subjective evaluations demonstrate ImprovNet's effectiveness in generating musically coherent improvisations while maintaining structural relationships with the original pieces. The model outperforms Anticipatory Music Transformer in short continuation and infilling tasks and successfully achieves recognizable genre conversion, with 79\% of participants correctly identifying jazz-style improvisations. Our code and demo page can be found at https://github.com/keshavbhandari/improvnet.
Yin-Yang: Developing Motifs With Long-Term Structure And Controllability
Jan 29, 2025



Transformer models have made great strides in generating symbolically represented music with local coherence. However, controlling the development of motifs in a structured way with global form remains an open research area. One of the reasons for this challenge is due to the note-by-note autoregressive generation of such models, which lack the ability to correct themselves after deviations from the motif. In addition, their structural performance on datasets with shorter durations has not been studied in the literature. In this study, we propose Yin-Yang, a framework consisting of a phrase generator, phrase refiner, and phrase selector models for the development of motifs into melodies with long-term structure and controllability. The phrase refiner is trained on a novel corruption-refinement strategy which allows it to produce melodic and rhythmic variations of an original motif at generation time, thereby rectifying deviations of the phrase generator. We also introduce a new objective evaluation metric for quantifying how smoothly the motif manifests itself within the piece. Evaluation results show that our model achieves better performance compared to state-of-the-art transformer models while having the advantage of being controllable and making the generated musical structure semi-interpretable, paving the way for musical analysis. Our code and demo page can be found at https://github.com/keshavbhandari/yinyang.
Text2midi: Generating Symbolic Music from Captions
Dec 21, 2024This paper introduces text2midi, an end-to-end model to generate MIDI files from textual descriptions. Leveraging the growing popularity of multimodal generative approaches, text2midi capitalizes on the extensive availability of textual data and the success of large language models (LLMs). Our end-to-end system harnesses the power of LLMs to generate symbolic music in the form of MIDI files. Specifically, we utilize a pretrained LLM encoder to process captions, which then condition an autoregressive transformer decoder to produce MIDI sequences that accurately reflect the provided descriptions. This intuitive and user-friendly method significantly streamlines the music creation process by allowing users to generate music pieces using text prompts. We conduct comprehensive empirical evaluations, incorporating both automated and human studies, that show our model generates MIDI files of high quality that are indeed controllable by text captions that may include music theory terms such as chords, keys, and tempo. We release the code and music samples on our demo page (https://github.com/AMAAI-Lab/Text2midi) for users to interact with text2midi.
Motifs, Phrases, and Beyond: The Modelling of Structure in Symbolic Music Generation
Mar 12, 2024Modelling musical structure is vital yet challenging for artificial intelligence systems that generate symbolic music compositions. This literature review dissects the evolution of techniques for incorporating coherent structure, from symbolic approaches to foundational and transformative deep learning methods that harness the power of computation and data across a wide variety of training paradigms. In the later stages, we review an emerging technique which we refer to as "sub-task decomposition" that involves decomposing music generation into separate high-level structural planning and content creation stages. Such systems incorporate some form of musical knowledge or neuro-symbolic methods by extracting melodic skeletons or structural templates to guide the generation. Progress is evident in capturing motifs and repetitions across all three eras reviewed, yet modelling the nuanced development of themes across extended compositions in the style of human composers remains difficult. We outline several key future directions to realize the synergistic benefits of combining approaches from all eras examined.
Optical Flow Estimation in 360$^\circ$ Videos: Dataset, Model and Application
Jan 27, 2023
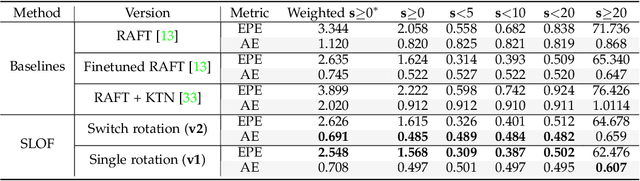

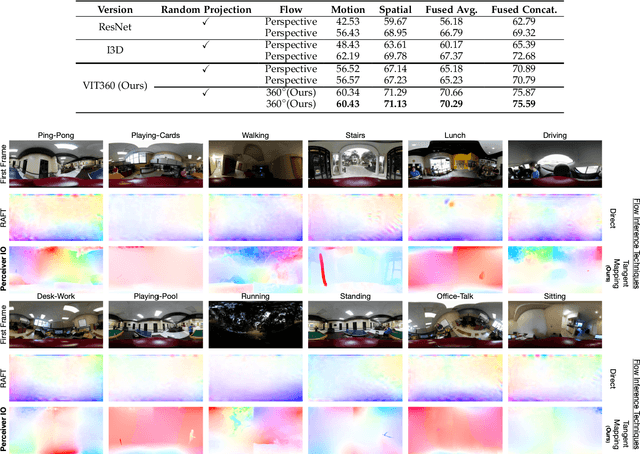
Optical flow estimation has been a long-lasting and fundamental problem in the computer vision community. However, despite the advances of optical flow estimation in perspective videos, the 360$^\circ$ videos counterpart remains in its infancy, primarily due to the shortage of benchmark datasets and the failure to accommodate the omnidirectional nature of 360$^\circ$ videos. We propose the first perceptually realistic 360$^\circ$ filed-of-view video benchmark dataset, namely FLOW360, with 40 different videos and 4,000 video frames. We then conduct comprehensive characteristic analysis and extensive comparisons with existing datasets, manifesting FLOW360's perceptual realism, uniqueness, and diversity. Moreover, we present a novel Siamese representation Learning framework for Omnidirectional Flow (SLOF) estimation, which is trained in a contrastive manner via a hybrid loss that combines siamese contrastive and optical flow losses. By training the model on random rotations of the input omnidirectional frames, our proposed contrastive scheme accommodates the omnidirectional nature of optical flow estimation in 360$^\circ$ videos, resulting in significantly reduced prediction errors. The learning scheme is further proven to be efficient by expanding our siamese learning scheme and omnidirectional optical flow estimation to the egocentric activity recognition task, where the classification accuracy is boosted up to $\sim$26%. To summarize, we study the optical flow estimation in 360$^\circ$ videos problem from perspectives of the benchmark dataset, learning model, and also practical application. The FLOW360 dataset and code are available at https://siamlof.github.io.
Learning Omnidirectional Flow in 360-degree Video via Siamese Representation
Aug 07, 2022Optical flow estimation in omnidirectional videos faces two significant issues: the lack of benchmark datasets and the challenge of adapting perspective video-based methods to accommodate the omnidirectional nature. This paper proposes the first perceptually natural-synthetic omnidirectional benchmark dataset with a 360-degree field of view, FLOW360, with 40 different videos and 4,000 video frames. We conduct comprehensive characteristic analysis and comparisons between our dataset and existing optical flow datasets, which manifest perceptual realism, uniqueness, and diversity. To accommodate the omnidirectional nature, we present a novel Siamese representation Learning framework for Omnidirectional Flow (SLOF). We train our network in a contrastive manner with a hybrid loss function that combines contrastive loss and optical flow loss. Extensive experiments verify the proposed framework's effectiveness and show up to 40% performance improvement over the state-of-the-art approaches. Our FLOW360 dataset and code are available at https://siamlof.github.io/.
Egok360: A 360 Egocentric Kinetic Human Activity Video Dataset
Oct 15, 2020

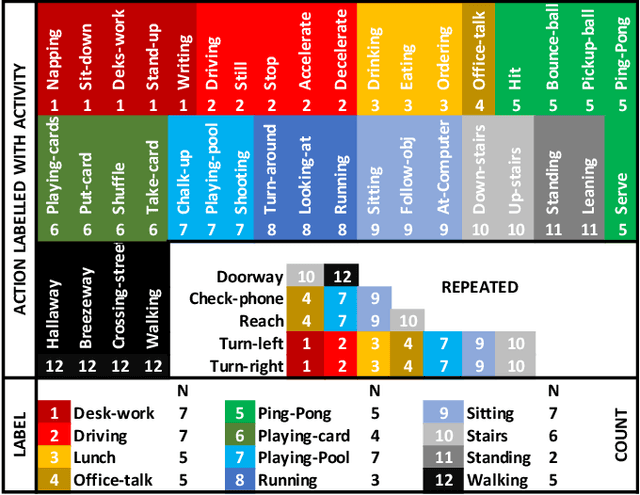
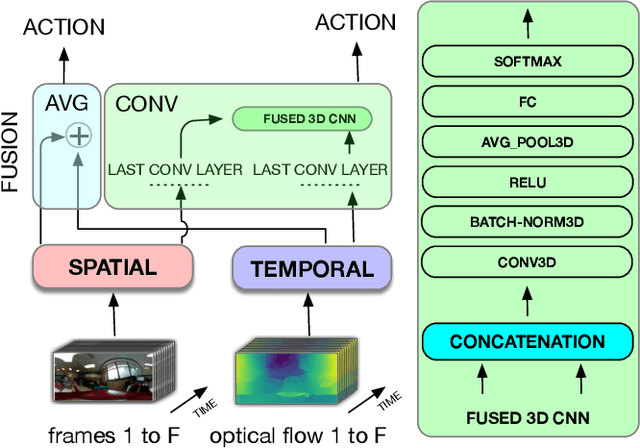
Recently, there has been a growing interest in wearable sensors which provides new research perspectives for 360 {\deg} video analysis. However, the lack of 360 {\deg} datasets in literature hinders the research in this field. To bridge this gap, in this paper we propose a novel Egocentric (first-person) 360{\deg} Kinetic human activity video dataset (EgoK360). The EgoK360 dataset contains annotations of human activity with different sub-actions, e.g., activity Ping-Pong with four sub-actions which are pickup-ball, hit, bounce-ball and serve. To the best of our knowledge, EgoK360 is the first dataset in the domain of first-person activity recognition with a 360{\deg} environmental setup, which will facilitate the egocentric 360 {\deg} video understanding. We provide experimental results and comprehensive analysis of variants of the two-stream network for 360 egocentric activity recognition. The EgoK360 dataset can be downloaded from https://egok360.github.io/.
Revisiting Optical Flow Estimation in 360 Videos
Oct 15, 2020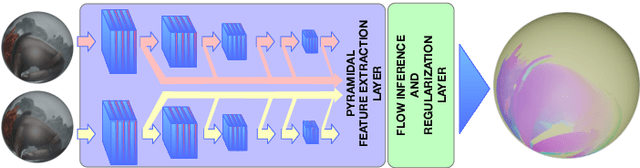

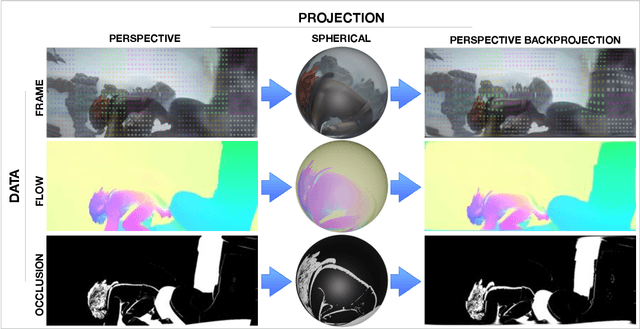

Nowadays 360 video analysis has become a significant research topic in the field since the appearance of high-quality and low-cost 360 wearable devices. In this paper, we propose a novel LiteFlowNet360 architecture for 360 videos optical flow estimation. We design LiteFlowNet360 as a domain adaptation framework from perspective video domain to 360 video domain. We adapt it from simple kernel transformation techniques inspired by Kernel Transformer Network (KTN) to cope with inherent distortion in 360 videos caused by the sphere-to-plane projection. First, we apply an incremental transformation of convolution layers in feature pyramid network and show that further transformation in inference and regularization layers are not important, hence reducing the network growth in terms of size and computation cost. Second, we refine the network by training with augmented data in a supervised manner. We perform data augmentation by projecting the images in a sphere and re-projecting to a plane. Third, we train LiteFlowNet360 in a self-supervised manner using target domain 360 videos. Experimental results show the promising results of 360 video optical flow estimation using the proposed novel architecture.