 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Anchor-Driven Test Generation for Deep Neural Networks
Jun 03, 2026Deep Neural Networks (DNNs) are increasingly being deployed in security-critical and safety-sensitive applications, which makes rigorous testing essential to identify and mitigate model weaknesses. Existing DNN testing approaches explore either the input space or a learned latent space. While latent-space generation can better maintain plausibility than direct input-space mutation, current methods still face a trade-off among exploration controllability, failure diversity, and seed-relative semantic drift. To overcome these limitations, we propose Latte, a black-box testing framework that generates semantically proximate, diverse, and fault-revealing test cases by leveraging the latent space. Specifically, Latte encodes each input seed with a pre-trained VQ-VAE and performs a seed-centered, one-step latent mutation along directions defined by anchors sampled from alternative classes, followed by quantization and decoding back to the input space. This explores local neighborhoods around each seed within the learned latent manifold, resulting in a larger number and broader diversity of oracle-triggering prediction discrepancies under the same budget. We evaluated Latte on 5 datasets and 10 DNN models in single-model and multi-model testing scenarios. Across the evaluated datasets and models, Latte improves fault exposure and behavioral diversity under matched testing budgets. Under the single-model setting, it also maintains low seed-relative semantic drift with respect to the source seeds.
Toward a Generalized Defense Across Sparse, Continuous, and Structured Parameter Attacks
Jun 03, 2026Deep neural networks are increasingly deployed across heterogeneous and partially untrusted environments, where models are distributed through cloud storage, CI/CD pipelines, containerized services, and edge execution platforms. This broad deployment landscape exposes model parameters to various integrity risks. Unlike input-space adversarial attacks, parameter attacks directly tamper with the model's internal parameters and persist across all subsequent inferences. Existing defenses either require retraining, incur significant accuracy degradation, or are limited to specific attack classes. However, in real-world deployment scenarios, the forms of parameter attacks are often unpredictable. To address this challenge, we present ParDef, a generalized defense for deep neural networks against diverse types of parameter attacks. ParDef integrates keyed channel reparameterization, which obscures sensitive parameter directions, QC-LDPC quantization, which embeds redundancy and supports error correction, and adaptive robust inference, which stabilizes predictions under uncertainty. Our evaluation on CIFAR-10, CIFAR-100, and Tiny-ImageNet using ResNet and VGG models demonstrates that ParDef consistently reduces attack success rates across different parameter attacks while maintaining high model performance and incurring only moderate deployment overhead. These results highlight that ParDef is a practical and generalized defense for DNN deployments.
Testing Neural Networks via Bayesian-Guided Exploration of Decision Landscapes
Jun 03, 2026As neural networks are increasingly deployed in safety-critical domains, testing is essential to evaluate and improve their reliability. Existing testing methods, whether black-box or white-box, primarily use global mutation or coverage-guided strategies, both of which struggle to efficiently uncover diverse model failures while remaining proximate to the original data distribution and semantics. We propose BayesWarp, a testing framework that addresses this limitation by mutating decision-critical input regions identified via interpretable saliency techniques and adaptively guiding the testing process using an uncertainty-aware Bayesian Optimization strategy, enabling the discovery of diverse failures while preserving distributional and semantic proximity to the original data. Evaluation on MNIST, CIFAR-10, and ImageNet across six neural network models shows that BayesWarp improves failure discovery, failure diversity, test case quality, and critical neuron coverage under a fixed mutation budget. These results demonstrate that BayesWarp improves testing effectiveness. Moreover, fine-tuning with the generated failure cases leads to improvements in model performance.
X-Field: A Physically Grounded Representation for 3D X-ray Reconstruction
Mar 11, 2025X-ray imaging is indispensable in medical diagnostics, yet its use is tightly regulated due to potential health risks. To mitigate radiation exposure, recent research focuses on generating novel views from sparse inputs and reconstructing Computed Tomography (CT) volumes, borrowing representations from the 3D reconstruction area. However, these representations originally target visible light imaging that emphasizes reflection and scattering effects, while neglecting penetration and attenuation properties of X-ray imaging. In this paper, we introduce X-Field, the first 3D representation specifically designed for X-ray imaging, rooted in the energy absorption rates across different materials. To accurately model diverse materials within internal structures, we employ 3D ellipsoids with distinct attenuation coefficients. To estimate each material's energy absorption of X-rays, we devise an efficient path partitioning algorithm accounting for complex ellipsoid intersections. We further propose hybrid progressive initialization to refine the geometric accuracy of X-Filed and incorporate material-based optimization to enhance model fitting along material boundaries. Experiments show that X-Field achieves superior visual fidelity on both real-world human organ and synthetic object datasets, outperforming state-of-the-art methods in X-ray Novel View Synthesis and CT Reconstruction.
MambaReg: Mamba-Based Disentangled Convolutional Sparse Coding for Unsupervised Deformable Multi-Modal Image Registration
Nov 03, 2024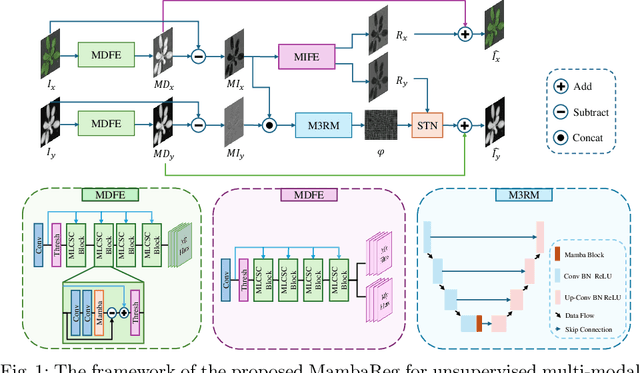
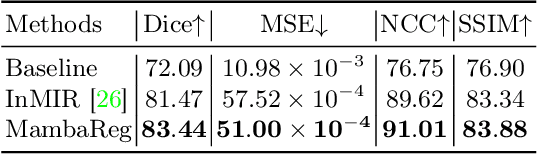
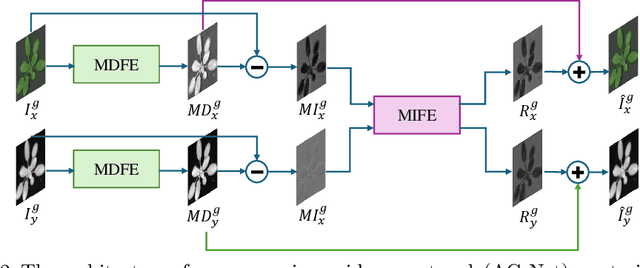

Precise alignment of multi-modal images with inherent feature discrepancies poses a pivotal challenge in deformable image registration. Traditional learning-based approaches often consider registration networks as black boxes without interpretability. One core insight is that disentangling alignment features and non-alignment features across modalities bring benefits. Meanwhile, it is challenging for the prominent methods for image registration tasks, such as convolutional neural networks, to capture long-range dependencies by their local receptive fields. The methods often fail when the given image pair has a large misalignment due to the lack of effectively learning long-range dependencies and correspondence. In this paper, we propose MambaReg, a novel Mamba-based architecture that integrates Mamba's strong capability in capturing long sequences to address these challenges. With our proposed several sub-modules, MambaReg can effectively disentangle modality-independent features responsible for registration from modality-dependent, non-aligning features. By selectively attending to the relevant features, our network adeptly captures the correlation between multi-modal images, enabling focused deformation field prediction and precise image alignment. The Mamba-based architecture seamlessly integrates the local feature extraction power of convolutional layers with the long-range dependency modeling capabilities of Mamba. Experiments on public non-rigid RGB-IR image datasets demonstrate the superiority of our method, outperforming existing approaches in terms of registration accuracy and deformation field smoothness.
Token Transformation Matters: Towards Faithful Post-hoc Explanation for Vision Transformer
Mar 21, 2024



While Transformers have rapidly gained popularity in various computer vision applications, post-hoc explanations of their internal mechanisms remain largely unexplored. Vision Transformers extract visual information by representing image regions as transformed tokens and integrating them via attention weights. However, existing post-hoc explanation methods merely consider these attention weights, neglecting crucial information from the transformed tokens, which fails to accurately illustrate the rationales behind the models' predictions. To incorporate the influence of token transformation into interpretation, we propose TokenTM, a novel post-hoc explanation method that utilizes our introduced measurement of token transformation effects. Specifically, we quantify token transformation effects by measuring changes in token lengths and correlations in their directions pre- and post-transformation. Moreover, we develop initialization and aggregation rules to integrate both attention weights and token transformation effects across all layers, capturing holistic token contributions throughout the model. Experimental results on segmentation and perturbation tests demonstrate the superiority of our proposed TokenTM compared to state-of-the-art Vision Transformer explanation methods.
MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation
Mar 21, 2024



Segment Anything Model~(SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM does not work when directly applied to medical image segmentation tasks, since SAM lacks the functionality to predict semantic labels for predicted masks and needs to provide extra prompts, such as points or boxes, to segment target regions. Meanwhile, there is a huge gap between 2D natural images and 3D medical images, so the performance of SAM is imperfect for medical image segmentation tasks. Following the above issues, we propose MaskSAM, a novel mask classification prompt-free SAM adaptation framework for medical image segmentation. We design a prompt generator combined with the image encoder in SAM to generate a set of auxiliary classifier tokens, auxiliary binary masks, and auxiliary bounding boxes. Each pair of auxiliary mask and box prompts, which can solve the requirements of extra prompts, is associated with class label predictions by the sum of the auxiliary classifier token and the learnable global classifier tokens in the mask decoder of SAM to solve the predictions of semantic labels. Meanwhile, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings. We inject one of them into each transformer block in the image encoder and mask decoder to enable pre-trained 2D SAM models to extract 3D information and adapt to 3D medical images. Our method achieves state-of-the-art performance on AMOS2022, 90.52% Dice, which improved by 2.7% compared to nnUNet. Our method surpasses nnUNet by 1.7% on ACDC and 1.0% on Synapse datasets.
Online Multi-spectral Neuron Tracing
Mar 10, 2024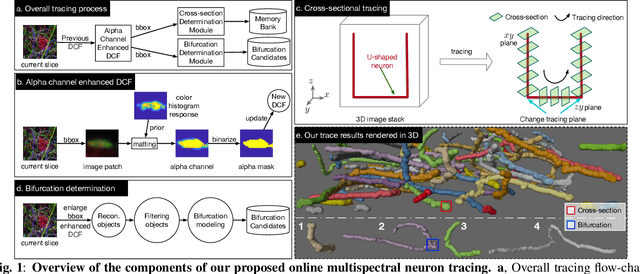


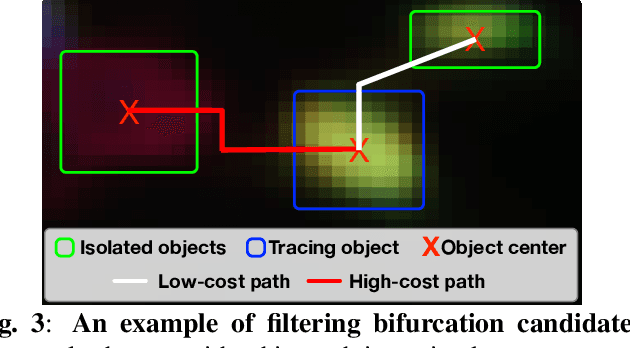
In this paper, we propose an online multi-spectral neuron tracing method with uniquely designed modules, where no offline training are required. Our method is trained online to update our enhanced discriminative correlation filter to conglutinate the tracing process. This distinctive offline-training-free schema differentiates us from other training-dependent tracing approaches like deep learning methods since no annotation is needed for our method. Besides, compared to other tracing methods requiring complicated set-up such as for clustering and graph multi-cut, our approach is much easier to be applied to new images. In fact, it only needs a starting bounding box of the tracing neuron, significantly reducing users' configuration effort. Our extensive experiments show that our training-free and easy-configured methodology allows fast and accurate neuron reconstructions in multi-spectral images.
Towards Saner Deep Image Registration
Jul 24, 2023


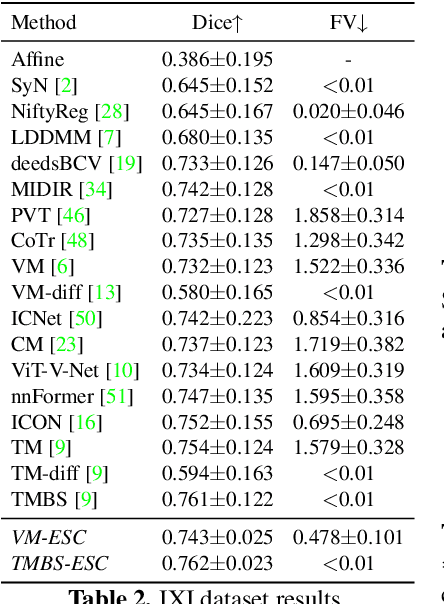
With recent advances in computing hardware and surges of deep-learning architectures, learning-based deep image registration methods have surpassed their traditional counterparts, in terms of metric performance and inference time. However, these methods focus on improving performance measurements such as Dice, resulting in less attention given to model behaviors that are equally desirable for registrations, especially for medical imaging. This paper investigates these behaviors for popular learning-based deep registrations under a sanity-checking microscope. We find that most existing registrations suffer from low inverse consistency and nondiscrimination of identical pairs due to overly optimized image similarities. To rectify these behaviors, we propose a novel regularization-based sanity-enforcer method that imposes two sanity checks on the deep model to reduce its inverse consistency errors and increase its discriminative power simultaneously. Moreover, we derive a set of theoretical guarantees for our sanity-checked image registration method, with experimental results supporting our theoretical findings and their effectiveness in increasing the sanity of models without sacrificing any performance. Our code and models are available at https://github.com/tuffr5/Saner-deep-registration.
Query-Utterance Attention with Joint modeling for Query-Focused Meeting Summarization
Mar 08, 2023



Query-focused meeting summarization (QFMS) aims to generate summaries from meeting transcripts in response to a given query. Previous works typically concatenate the query with meeting transcripts and implicitly model the query relevance only at the token level with attention mechanism. However, due to the dilution of key query-relevant information caused by long meeting transcripts, the original transformer-based model is insufficient to highlight the key parts related to the query. In this paper, we propose a query-aware framework with joint modeling token and utterance based on Query-Utterance Attention. It calculates the utterance-level relevance to the query with a dense retrieval module. Then both token-level query relevance and utterance-level query relevance are combined and incorporated into the generation process with attention mechanism explicitly. We show that the query relevance of different granularities contributes to generating a summary more related to the query. Experimental results on the QMSum dataset show that the proposed model achieves new state-of-the-art performance.