 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogniMap3D: Cognitive 3D Mapping and Rapid Retrieval
Jan 13, 2026We present CogniMap3D, a bioinspired framework for dynamic 3D scene understanding and reconstruction that emulates human cognitive processes. Our approach maintains a persistent memory bank of static scenes, enabling efficient spatial knowledge storage and rapid retrieval. CogniMap3D integrates three core capabilities: a multi-stage motion cue framework for identifying dynamic objects, a cognitive mapping system for storing, recalling, and updating static scenes across multiple visits, and a factor graph optimization strategy for refining camera poses. Given an image stream, our model identifies dynamic regions through motion cues with depth and camera pose priors, then matches static elements against its memory bank. When revisiting familiar locations, CogniMap3D retrieves stored scenes, relocates cameras, and updates memory with new observations. Evaluations on video depth estimation, camera pose reconstruction, and 3D mapping tasks demonstrate its state-of-the-art performance, while effectively supporting continuous scene understanding across extended sequences and multiple visits.
TraceFlow: Dynamic 3D Reconstruction of Specular Scenes Driven by Ray Tracing
Dec 10, 2025We present TraceFlow, a novel framework for high-fidelity rendering of dynamic specular scenes by addressing two key challenges: precise reflection direction estimation and physically accurate reflection modeling. To achieve this, we propose a Residual Material-Augmented 2D Gaussian Splatting representation that models dynamic geometry and material properties, allowing accurate reflection ray computation. Furthermore, we introduce a Dynamic Environment Gaussian and a hybrid rendering pipeline that decomposes rendering into diffuse and specular components, enabling physically grounded specular synthesis via rasterization and ray tracing. Finally, we devise a coarse-to-fine training strategy to improve optimization stability and promote physically meaningful decomposition. Extensive experiments on dynamic scene benchmarks demonstrate that TraceFlow outperforms prior methods both quantitatively and qualitatively, producing sharper and more realistic specular reflections in complex dynamic environments.
MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation
Mar 21, 2024Segment Anything Model~(SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM does not work when directly applied to medical image segmentation tasks, since SAM lacks the functionality to predict semantic labels for predicted masks and needs to provide extra prompts, such as points or boxes, to segment target regions. Meanwhile, there is a huge gap between 2D natural images and 3D medical images, so the performance of SAM is imperfect for medical image segmentation tasks. Following the above issues, we propose MaskSAM, a novel mask classification prompt-free SAM adaptation framework for medical image segmentation. We design a prompt generator combined with the image encoder in SAM to generate a set of auxiliary classifier tokens, auxiliary binary masks, and auxiliary bounding boxes. Each pair of auxiliary mask and box prompts, which can solve the requirements of extra prompts, is associated with class label predictions by the sum of the auxiliary classifier token and the learnable global classifier tokens in the mask decoder of SAM to solve the predictions of semantic labels. Meanwhile, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings. We inject one of them into each transformer block in the image encoder and mask decoder to enable pre-trained 2D SAM models to extract 3D information and adapt to 3D medical images. Our method achieves state-of-the-art performance on AMOS2022, 90.52% Dice, which improved by 2.7% compared to nnUNet. Our method surpasses nnUNet by 1.7% on ACDC and 1.0% on Synapse datasets.
Online Multi-spectral Neuron Tracing
Mar 10, 2024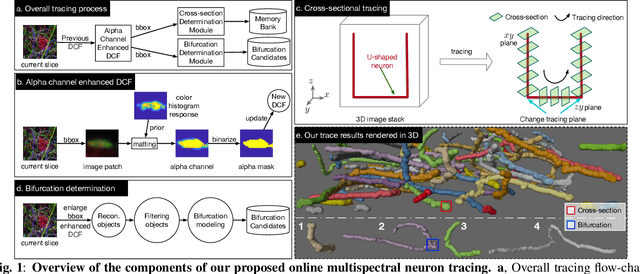


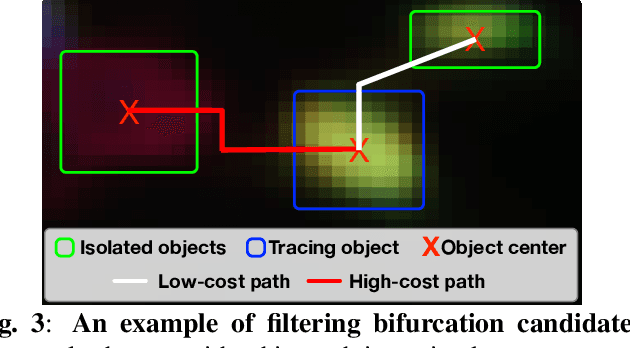
In this paper, we propose an online multi-spectral neuron tracing method with uniquely designed modules, where no offline training are required. Our method is trained online to update our enhanced discriminative correlation filter to conglutinate the tracing process. This distinctive offline-training-free schema differentiates us from other training-dependent tracing approaches like deep learning methods since no annotation is needed for our method. Besides, compared to other tracing methods requiring complicated set-up such as for clustering and graph multi-cut, our approach is much easier to be applied to new images. In fact, it only needs a starting bounding box of the tracing neuron, significantly reducing users' configuration effort. Our extensive experiments show that our training-free and easy-configured methodology allows fast and accurate neuron reconstructions in multi-spectral images.
Few-shot Medical Image Segmentation with Cycle-resemblance Attention
Dec 07, 2022



Recently, due to the increasing requirements of medical imaging applications and the professional requirements of annotating medical images, few-shot learning has gained increasing attention in the medical image semantic segmentation field. To perform segmentation with limited number of labeled medical images, most existing studies use Proto-typical Networks (PN) and have obtained compelling success. However, these approaches overlook the query image features extracted from the proposed representation network, failing to preserving the spatial connection between query and support images. In this paper, we propose a novel self-supervised few-shot medical image segmentation network and introduce a novel Cycle-Resemblance Attention (CRA) module to fully leverage the pixel-wise relation between query and support medical images. Notably, we first line up multiple attention blocks to refine more abundant relation information. Then, we present CRAPNet by integrating the CRA module with a classic prototype network, where pixel-wise relations between query and support features are well recaptured for segmentation. Extensive experiments on two different medical image datasets, e.g., abdomen MRI and abdomen CT, demonstrate the superiority of our model over existing state-of-the-art methods.
MLP-GAN for Brain Vessel Image Segmentation
Jul 17, 2022
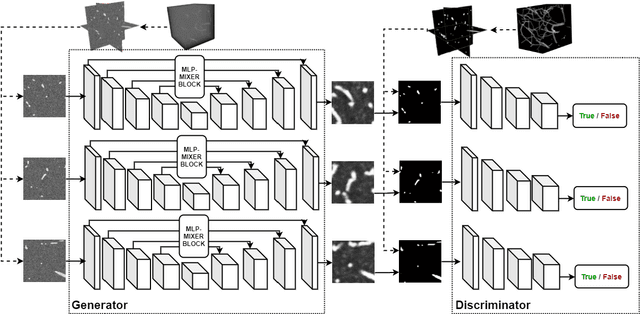
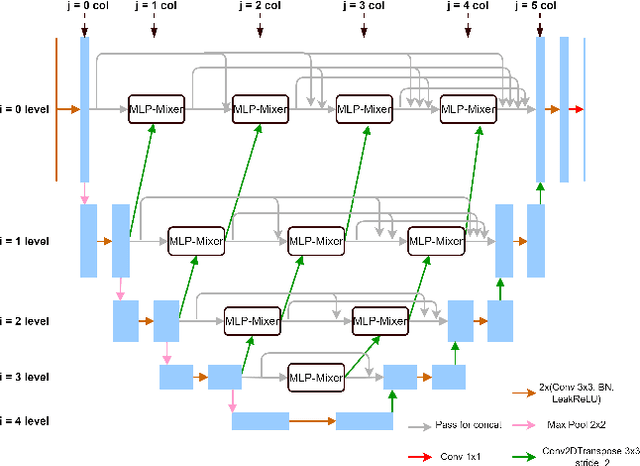
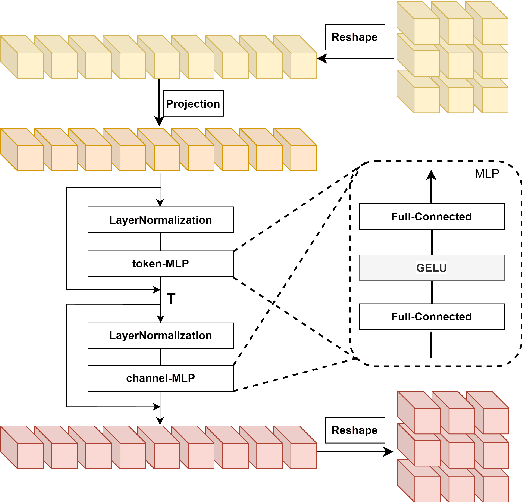
Brain vessel image segmentation can be used as a promising biomarker for better prevention and treatment of different diseases. One successful approach is to consider the segmentation as an image-to-image translation task and perform a conditional Generative Adversarial Network (cGAN) to learn a transformation between two distributions. In this paper, we present a novel multi-view approach, MLP-GAN, which splits a 3D volumetric brain vessel image into three different dimensional 2D images (i.e., sagittal, coronal, axial) and then feed them into three different 2D cGANs. The proposed MLP-GAN not only alleviates the memory issue which exists in the original 3D neural networks but also retains 3D spatial information. Specifically, we utilize U-Net as the backbone for our generator and redesign the pattern of skip connection integrated with the MLP-Mixer which has attracted lots of attention recently. Our model obtains the ability to capture cross-patch information to learn global information with the MLP-Mixer. Extensive experiments are performed on the public brain vessel dataset that show our MLP-GAN outperforms other state-of-the-art methods. We release our code at https://github.com/bxie9/MLP-GAN