 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryVLA++: Temporal Modeling via Memory and Imagination in Vision-Language-Action Models
Jun 08, 2026Temporal modeling is essential for robotic manipulation, as effective control requires both memory of past interactions and imagination of future states. However, most VLA models rely primarily on the current observation and therefore struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived context, the hippocampal system to preserve episodic memory of past experience, and internal models to imagine possible future state evolution. Inspired by these mechanisms, we propose MemoryVLA++, a full temporal modeling framework that equips VLA models with memory and imagination for robotic manipulation. A pretrained VLM encodes the current observation into perceptual and cognitive tokens, forming working memory. These tokens query a Perceptual-Cognitive Memory Bank to retrieve relevant historical context. This bank stores low-level details and high-level semantics from past interactions, and is updated through redundancy-aware consolidation. A world model imagines future states in a denoising latent space, and the imagined latents are integrated under memory guidance to form full temporal-aware tokens. The resulting tokens condition a diffusion action expert to predict temporally consistent action sequences. We conduct extensive experiments on 5 simulation benchmarks and 3 categories of real-robot tasks across 3 robots, covering general manipulation, long-horizon temporal tasks, robustness, and generalization. Our method achieves strong performance across Libero, SimplerEnv, Mikasa-Robo, Calvin, Libero-Plus, and diverse real-robot tasks, validating the effectiveness of full temporal modeling with memory and imagination. For example, on real robots, it achieves +9%, +26%, +28% gains on general, memory-dependent, and imagination-dependent tasks. Project Page: https://shihao1895.github.io/MemoryVLA-PP-Web
PriorVLA: Prior-Preserving Adaptation for Vision-Language-Action Models
May 11, 2026Large-scale pretraining has made Vision-Language-Action (VLA) models promising foundations for generalist robot manipulation, yet adapting them to downstream tasks remains necessary. However, the common practice of full fine-tuning treats pretraining as initialization and can shift broad priors toward narrow training-distribution patterns. We propose PriorVLA, a novel framework that preserves pretrained priors and learns to leverage them for effective adaptation. PriorVLA keeps a frozen Prior Expert as a read-only prior source and trains an Adaptation Expert for downstream specialization. Expert Queries capture scene priors from the pretrained VLM and motor priors from the Prior Expert, integrating both into the Adaptation Expert to guide adaptation. Together, PriorVLA updates only 25% of the parameters updated by full fine-tuning. Across RoboTwin 2.0, LIBERO, and real-world tasks, PriorVLA achieves stronger overall performance than full fine-tuning and state-of-the-art VLA baselines, with the largest gains under out-of-distribution (OOD) and few-shot settings. PriorVLA improves over pi0.5 by 11 points on RoboTwin 2.0-Hard and achieves 99.1% average success on LIBERO. Across eight real-world tasks and two embodiments, PriorVLA reaches 81% in-distribution (ID) and 57% OOD success with standard data. With only 10 demonstrations per task, PriorVLA reaches 48% ID and 32% OOD success, surpassing pi0.5 by 24 and 22 points, respectively.
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
HATS: Hardness-Aware Trajectory Synthesis for GUI Agents
Mar 12, 2026Graphical user interface (GUI) agents powered by large vision-language models (VLMs) have shown remarkable potential in automating digital tasks, highlighting the need for high-quality trajectory data to support effective agent training. Yet existing trajectory synthesis pipelines often yield agents that fail to generalize beyond simple interactions. We identify this limitation as stemming from the neglect of semantically ambiguous actions, whose meanings are context-dependent, sequentially dependent, or visually ambiguous. Such actions are crucial for real-world robustness but are under-represented and poorly processed in current datasets, leading to semantic misalignment between task instructions and execution. To address these issues, we propose HATS, a Hardness-Aware Trajectory Synthesis framework designed to mitigate the impact of semantic ambiguity. We define hardness as the degree of semantic ambiguity associated with an action and develop two complementary modules: (1) hardness-driven exploration, which guides data collection toward ambiguous yet informative interactions, and (2) alignment-guided refinement, which iteratively validates and repairs instruction-execution alignment. The two modules operate in a closed loop: exploration supplies refinement with challenging trajectories, while refinement feedback updates the hardness signal to guide future exploration. Extensive experiments show that agents trained with HATS consistently outperform state-of-the-art baselines across benchmark GUI environments.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
Towards Robust Process Reward Modeling via Noise-aware Learning
Jan 19, 2026Process Reward Models (PRMs) have achieved strong results in complex reasoning, but are bottlenecked by costly process-level supervision. A widely used alternative, Monte Carlo Estimation (MCE), defines process rewards as the probability that a policy model reaches the correct final answer from a given reasoning step. However, step correctness is an intrinsic property of the reasoning trajectory, and should be invariant to policy choice. Our empirical findings show that MCE producing policy-dependent rewards that induce label noise, including false positives that reward incorrect steps and false negatives that penalize correct ones. To address above challenges, we propose a two-stage framework to mitigate noisy supervision. In the labeling stage, we introduce a reflection-aware label correction mechanism that uses a large language model (LLM) as a judge to detect reflection and self-correction behaviors related to the current reasoning step, thereby suppressing overestimated rewards. In the training stage, we further propose a \underline{\textbf{N}}oise-\underline{\textbf{A}}ware \underline{\textbf{I}}terative \underline{\textbf{T}}raining framework that enables the PRM to progressively refine noisy labels based on its own confidence. Extensive Experiments show that our method substantially improves step-level correctness discrimination, achieving up to a 27\% absolute gain in average F1 over PRMs trained with noisy supervision.
R$^2$PO: Decoupling Training Trajectories from Inference Responses for LLM Reasoning
Jan 17, 2026Reinforcement learning has become a central paradigm for improving LLM reasoning. However, existing methods use a single policy to produce both inference responses and training optimization trajectories. The objective conflict between generating stable inference responses and diverse training trajectories leads to insufficient exploration, which harms reasoning capability. In this paper, to address the problem, we propose R$^2$PO (Residual Rollout Policy Optimization), which introduces a lightweight Residual Rollout-Head atop the policy to decouple training trajectories from inference responses, enabling controlled trajectory diversification during training while keeping inference generation stable. Experiments across multiple benchmarks show that our method consistently outperforms baselines, achieving average accuracy gains of 3.1% on MATH-500 and 2.4% on APPS, while also reducing formatting errors and mitigating length bias for stable optimization. Our code is publicly available at https://github.com/RRPO-ARR/Code.
MaskMed: Decoupled Mask and Class Prediction for Medical Image Segmentation
Nov 19, 2025Medical image segmentation typically adopts a point-wise convolutional segmentation head to predict dense labels, where each output channel is heuristically tied to a specific class. This rigid design limits both feature sharing and semantic generalization. In this work, we propose a unified decoupled segmentation head that separates multi-class prediction into class-agnostic mask prediction and class label prediction using shared object queries. Furthermore, we introduce a Full-Scale Aware Deformable Transformer module that enables low-resolution encoder features to attend across full-resolution encoder features via deformable attention, achieving memory-efficient and spatially aligned full-scale fusion. Our proposed method, named MaskMed, achieves state-of-the-art performance, surpassing nnUNet by +2.0% Dice on AMOS 2022 and +6.9% Dice on BTCV.
SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
MemoryVLA: Perceptual-Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation
Aug 26, 2025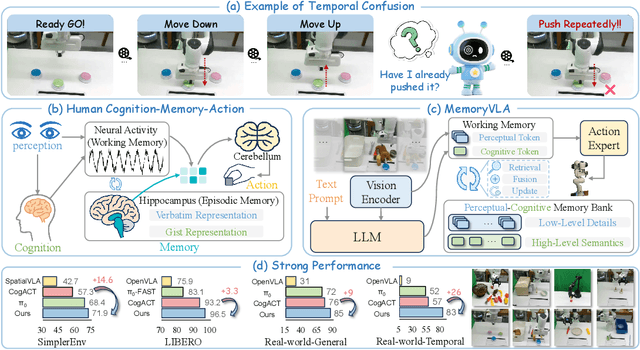
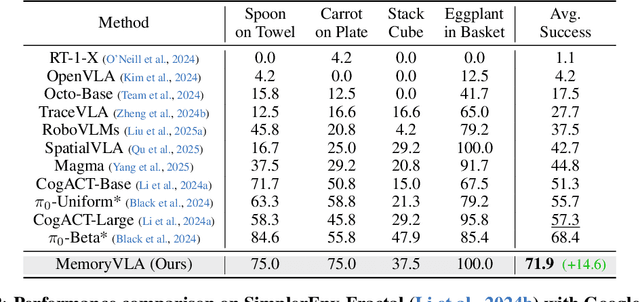
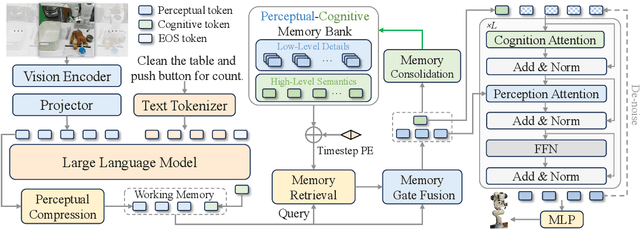
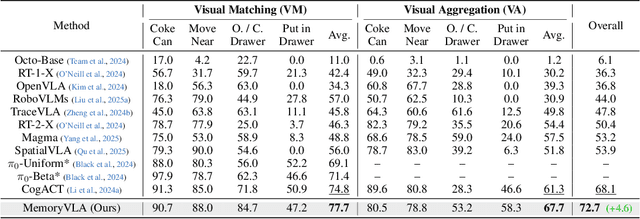
Temporal context is essential for robotic manipulation because such tasks are inherently non-Markovian, yet mainstream VLA models typically overlook it and struggle with long-horizon, temporally dependent tasks. Cognitive science suggests that humans rely on working memory to buffer short-lived representations for immediate control, while the hippocampal system preserves verbatim episodic details and semantic gist of past experience for long-term memory. Inspired by these mechanisms, we propose MemoryVLA, a Cognition-Memory-Action framework for long-horizon robotic manipulation. A pretrained VLM encodes the observation into perceptual and cognitive tokens that form working memory, while a Perceptual-Cognitive Memory Bank stores low-level details and high-level semantics consolidated from it. Working memory retrieves decision-relevant entries from the bank, adaptively fuses them with current tokens, and updates the bank by merging redundancies. Using these tokens, a memory-conditioned diffusion action expert yields temporally aware action sequences. We evaluate MemoryVLA on 150+ simulation and real-world tasks across three robots. On SimplerEnv-Bridge, Fractal, and LIBERO-5 suites, it achieves 71.9%, 72.7%, and 96.5% success rates, respectively, all outperforming state-of-the-art baselines CogACT and pi-0, with a notable +14.6 gain on Bridge. On 12 real-world tasks spanning general skills and long-horizon temporal dependencies, MemoryVLA achieves 84.0% success rate, with long-horizon tasks showing a +26 improvement over state-of-the-art baseline. Project Page: https://shihao1895.github.io/MemoryVLA