 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating the Effectiveness of a Large Language Model-based Approach for Identifying Children's Development across Various Free Play Settings in Kindergarten
May 06, 2025Free play is a fundamental aspect of early childhood education, supporting children's cognitive, social, emotional, and motor development. However, assessing children's development during free play poses significant challenges due to the unstructured and spontaneous nature of the activity. Traditional assessment methods often rely on direct observations by teachers, parents, or researchers, which may fail to capture comprehensive insights from free play and provide timely feedback to educators. This study proposes an innovative approach combining Large Language Models (LLMs) with learning analytics to analyze children's self-narratives of their play experiences. The LLM identifies developmental abilities, while performance scores across different play settings are calculated using learning analytics techniques. We collected 2,224 play narratives from 29 children in a kindergarten, covering four distinct play areas over one semester. According to the evaluation results from eight professionals, the LLM-based approach achieved high accuracy in identifying cognitive, motor, and social abilities, with accuracy exceeding 90% in most domains. Moreover, significant differences in developmental outcomes were observed across play settings, highlighting each area's unique contributions to specific abilities. These findings confirm that the proposed approach is effective in identifying children's development across various free play settings. This study demonstrates the potential of integrating LLMs and learning analytics to provide child-centered insights into developmental trajectories, offering educators valuable data to support personalized learning and enhance early childhood education practices.
IAEmu: Learning Galaxy Intrinsic Alignment Correlations
Apr 07, 2025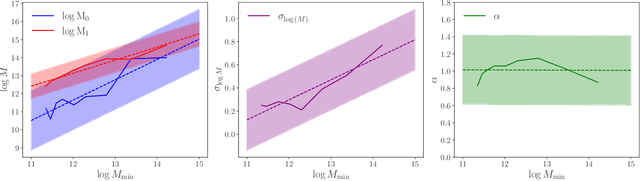
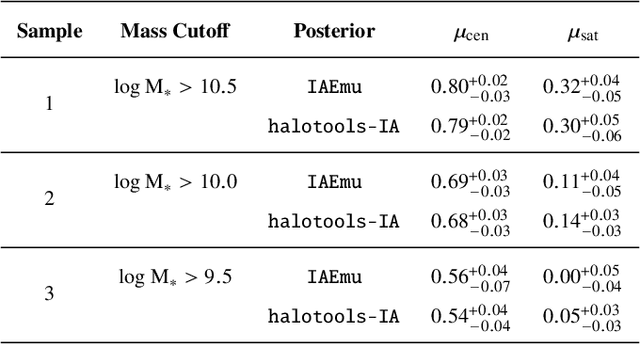
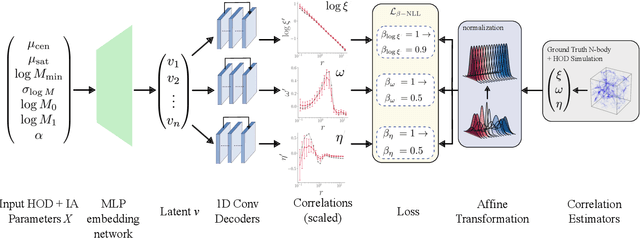
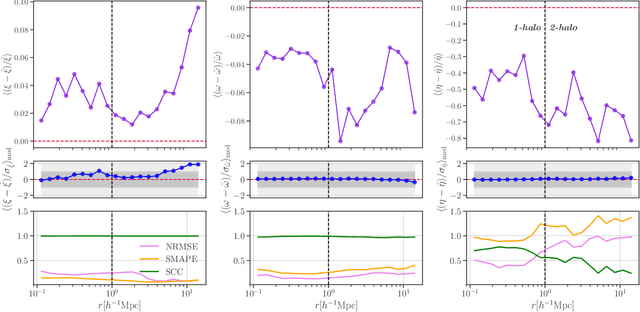
The intrinsic alignments (IA) of galaxies, a key contaminant in weak lensing analyses, arise from correlations in galaxy shapes driven by tidal interactions and galaxy formation processes. Accurate IA modeling is essential for robust cosmological inference, but current approaches rely on perturbative methods that break down on nonlinear scales or on expensive simulations. We introduce IAEmu, a neural network-based emulator that predicts the galaxy position-position ($\xi$), position-orientation ($\omega$), and orientation-orientation ($\eta$) correlation functions and their uncertainties using mock catalogs based on the halo occupation distribution (HOD) framework. Compared to simulations, IAEmu achieves ~3% average error for $\xi$ and ~5% for $\omega$, while capturing the stochasticity of $\eta$ without overfitting. The emulator provides both aleatoric and epistemic uncertainties, helping identify regions where predictions may be less reliable. We also demonstrate generalization to non-HOD alignment signals by fitting to IllustrisTNG hydrodynamical simulation data. As a fully differentiable neural network, IAEmu enables $\sim$10,000$\times$ speed-ups in mapping HOD parameters to correlation functions on GPUs, compared to CPU-based simulations. This acceleration facilitates inverse modeling via gradient-based sampling, making IAEmu a powerful surrogate model for galaxy bias and IA studies with direct applications to Stage IV weak lensing surveys.
Multi-Stage Graph Learning for fMRI Analysis to Diagnose Neuro-Developmental Disorders
Oct 07, 2024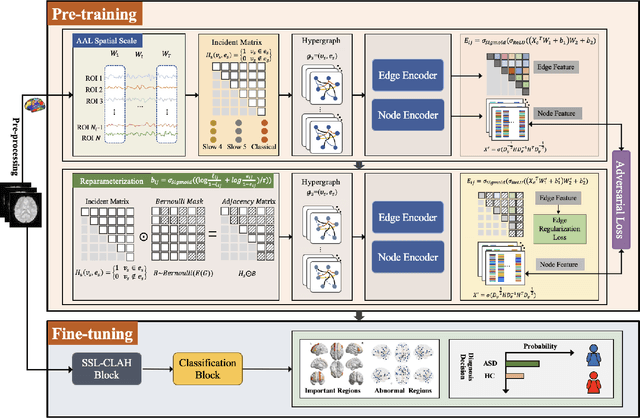
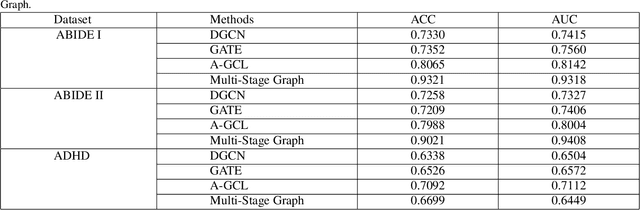
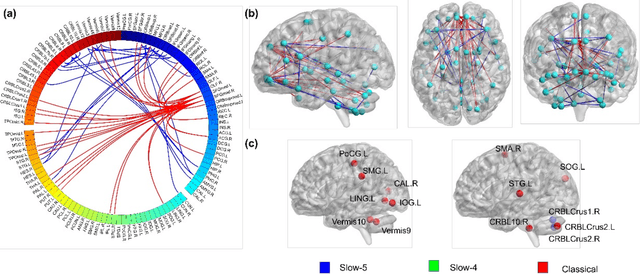

The insufficient supervision limit the performance of the deep supervised models for brain disease diagnosis. It is important to develop a learning framework that can capture more information in limited data and insufficient supervision. To address these issues at some extend, we propose a multi-stage graph learning framework which incorporates 1) pretrain stage : self-supervised graph learning on insufficient supervision of the fmri data 2) fine-tune stage : supervised graph learning for brain disorder diagnosis. Experiment results on three datasets, Autism Brain Imaging Data Exchange ABIDE I, ABIDE II and ADHD with AAL1,demonstrating the superiority and generalizability of the proposed framework compared to the state of art of models.(ranging from 0.7330 to 0.9321,0.7209 to 0.9021,0.6338 to 0.6699)
Benchmarking SLAM Algorithms in the Cloud: The SLAM Hive System
Jun 25, 2024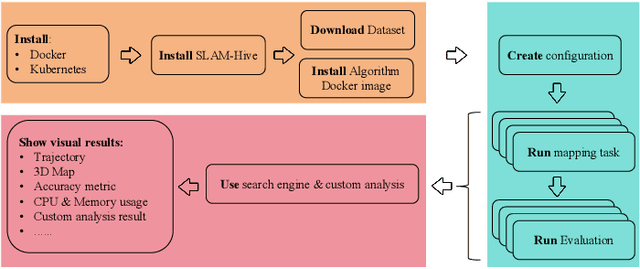
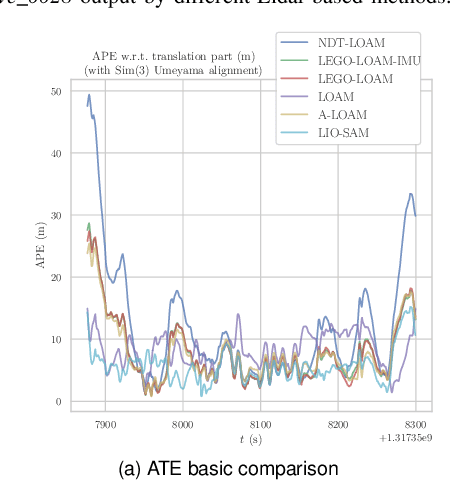
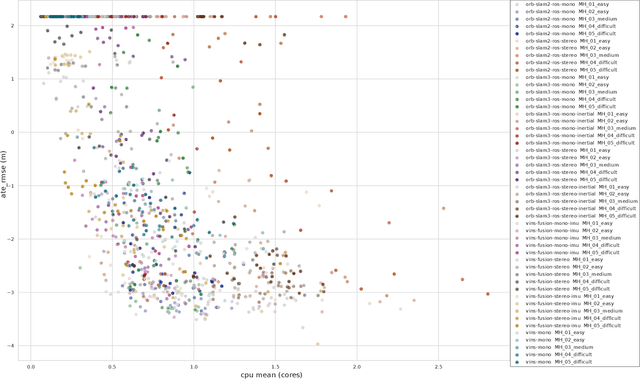
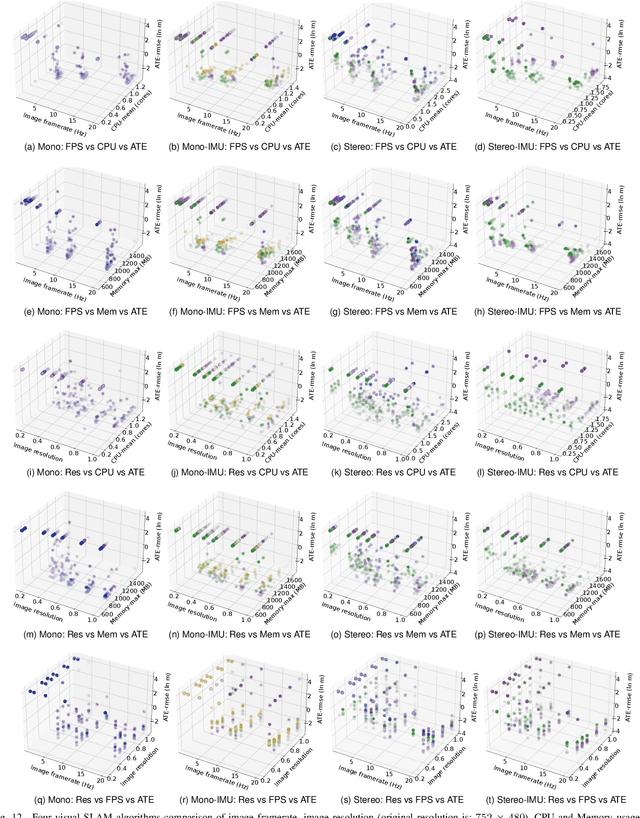
Evaluating the performance of Simultaneous Localization and Mapping (SLAM) algorithms is essential for scientists and users of robotic systems alike. But there are a multitude different permutations of possible options of hardware setups and algorithm configurations, as well as different datasets and algorithms, such that it is infeasible to thoroughly compare SLAM systems against the full state of the art. To solve that we present the SLAM Hive Benchmarking Suite, which is able to analyze SLAM algorithms in thousands of mapping runs, through its utilization of container technology and deployment in the cloud. This paper presents the architecture and open source implementation of SLAM Hive and compares it to existing efforts on SLAM evaluation. We perform mapping runs of many of the most popular visual and LiDAR based SLAM algorithms against commonly used datasets and show how SLAM Hive and then be used to conveniently analyze the results against various aspects. Through this we envision that SLAM Hive can become an essential tool for proper comparisons and evaluations of SLAM algorithms and thus drive the scientific development in the research on SLAM. The open source software as well as a demo to show the live analysis of 100s of mapping runs can be found on our SLAM Hive website.
ShanghaiTech Mapping Robot is All You Need: Robot System for Collecting Universal Ground Vehicle Datasets
Jun 24, 2024This paper presents the ShanghaiTech Mapping Robot, a state-of-the-art unmanned ground vehicle (UGV) designed for collecting comprehensive multi-sensor datasets to support research in robotics, computer vision, and autonomous driving. The robot is equipped with a wide array of sensors including RGB cameras, RGB-D cameras, event-based cameras, IR cameras, LiDARs, mmWave radars, IMUs, ultrasonic range finders, and a GNSS RTK receiver. The sensor suite is integrated onto a specially designed mechanical structure with a centralized power system and a synchronization mechanism to ensure spatial and temporal alignment of the sensor data. A 16-node on-board computing cluster handles sensor control, data collection, and storage. We describe the hardware and software architecture of the robot in detail and discuss the calibration procedures for the various sensors. The capabilities of the platform are demonstrated through an extensive dataset collected in diverse real-world environments. To facilitate research, we make the dataset publicly available along with the associated robot sensor calibration data. Performance evaluations on a set of standard perception and localization tasks showcase the potential of the dataset to support developments in Robot Autonomy.
A Combination Model Based on Sequential General Variational Mode Decomposition Method for Time Series Prediction
Jun 07, 2024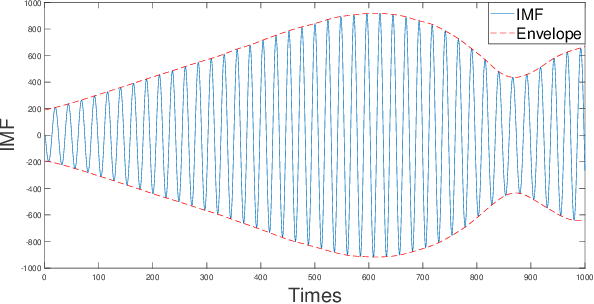
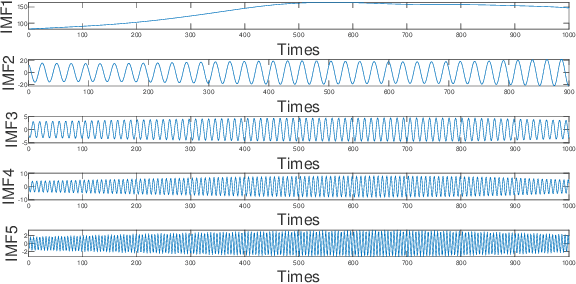
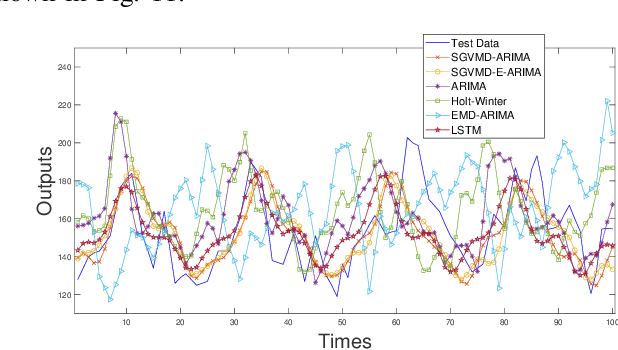
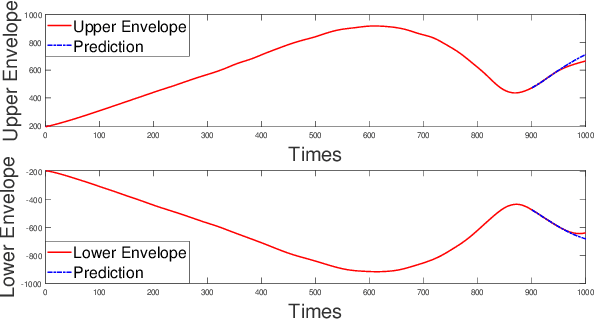
Accurate prediction of financial time series is a key concern for market economy makers and investors. The article selects online store sales and Australian beer sales as representatives of non-stationary, trending, and seasonal financial time series, and constructs a new SGVMD-ARIMA combination model in a non-linear combination way to predict financial time series. The ARIMA model, LSTM model, and other classic decomposition prediction models are used as control models to compare the accuracy of different models. The empirical results indicate that the constructed combination prediction model has universal advantages over the single prediction model and linear combination prediction model of the control group. Within the prediction interval, our proposed combination model has improved advantages over traditional decomposition prediction control group models.
Learning Galaxy Intrinsic Alignment Correlations
Apr 21, 2024



The intrinsic alignments (IA) of galaxies, regarded as a contaminant in weak lensing analyses, represents the correlation of galaxy shapes due to gravitational tidal interactions and galaxy formation processes. As such, understanding IA is paramount for accurate cosmological inferences from weak lensing surveys; however, one limitation to our understanding and mitigation of IA is expensive simulation-based modeling. In this work, we present a deep learning approach to emulate galaxy position-position ($\xi$), position-orientation ($\omega$), and orientation-orientation ($\eta$) correlation function measurements and uncertainties from halo occupation distribution-based mock galaxy catalogs. We find strong Pearson correlation values with the model across all three correlation functions and further predict aleatoric uncertainties through a mean-variance estimation training procedure. $\xi(r)$ predictions are generally accurate to $\leq10\%$. Our model also successfully captures the underlying signal of the noisier correlations $\omega(r)$ and $\eta(r)$, although with a lower average accuracy. We find that the model performance is inhibited by the stochasticity of the data, and will benefit from correlations averaged over multiple data realizations. Our code will be made open source upon journal publication.
Fast Heavy Inner Product Identification Between Weights and Inputs in Neural Network Training
Nov 19, 2023
In this paper, we consider a heavy inner product identification problem, which generalizes the Light Bulb problem~(\cite{prr89}): Given two sets $A \subset \{-1,+1\}^d$ and $B \subset \{-1,+1\}^d$ with $|A|=|B| = n$, if there are exact $k$ pairs whose inner product passes a certain threshold, i.e., $\{(a_1, b_1), \cdots, (a_k, b_k)\} \subset A \times B$ such that $\forall i \in [k], \langle a_i,b_i \rangle \geq \rho \cdot d$, for a threshold $\rho \in (0,1)$, the goal is to identify those $k$ heavy inner products. We provide an algorithm that runs in $O(n^{2 \omega / 3+ o(1)})$ time to find the $k$ inner product pairs that surpass $\rho \cdot d$ threshold with high probability, where $\omega$ is the current matrix multiplication exponent. By solving this problem, our method speed up the training of neural networks with ReLU activation function.
Dueling Optimization with a Monotone Adversary
Nov 18, 2023We introduce and study the problem of dueling optimization with a monotone adversary, which is a generalization of (noiseless) dueling convex optimization. The goal is to design an online algorithm to find a minimizer $\mathbf{x}^{*}$ for a function $f\colon X \to \mathbb{R}$, where $X \subseteq \mathbb{R}^d$. In each round, the algorithm submits a pair of guesses, i.e., $\mathbf{x}^{(1)}$ and $\mathbf{x}^{(2)}$, and the adversary responds with any point in the space that is at least as good as both guesses. The cost of each query is the suboptimality of the worse of the two guesses; i.e., ${\max} \left( f(\mathbf{x}^{(1)}), f(\mathbf{x}^{(2)}) \right) - f(\mathbf{x}^{*})$. The goal is to minimize the number of iterations required to find an $\varepsilon$-optimal point and to minimize the total cost (regret) of the guesses over many rounds. Our main result is an efficient randomized algorithm for several natural choices of the function $f$ and set $X$ that incurs cost $O(d)$ and iteration complexity $O(d\log(1/\varepsilon)^2)$. Moreover, our dependence on $d$ is asymptotically optimal, as we show examples in which any randomized algorithm for this problem must incur $\Omega(d)$ cost and iteration complexity.
A Survey of Robustness and Safety of 2D and 3D Deep Learning Models Against Adversarial Attacks
Oct 01, 2023Benefiting from the rapid development of deep learning, 2D and 3D computer vision applications are deployed in many safe-critical systems, such as autopilot and identity authentication. However, deep learning models are not trustworthy enough because of their limited robustness against adversarial attacks. The physically realizable adversarial attacks further pose fatal threats to the application and human safety. Lots of papers have emerged to investigate the robustness and safety of deep learning models against adversarial attacks. To lead to trustworthy AI, we first construct a general threat model from different perspectives and then comprehensively review the latest progress of both 2D and 3D adversarial attacks. We extend the concept of adversarial examples beyond imperceptive perturbations and collate over 170 papers to give an overview of deep learning model robustness against various adversarial attacks. To the best of our knowledge, we are the first to systematically investigate adversarial attacks for 3D models, a flourishing field applied to many real-world applications. In addition, we examine physical adversarial attacks that lead to safety violations. Last but not least, we summarize present popular topics, give insights on challenges, and shed light on future research on trustworthy AI.