 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAEmu: Learning Galaxy Intrinsic Alignment Correlations
Apr 07, 2025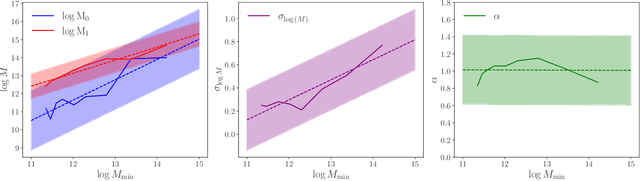
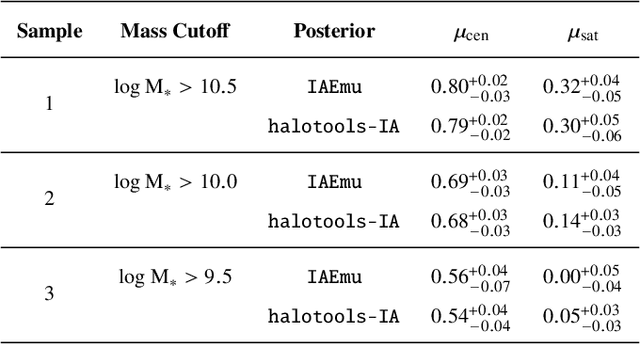
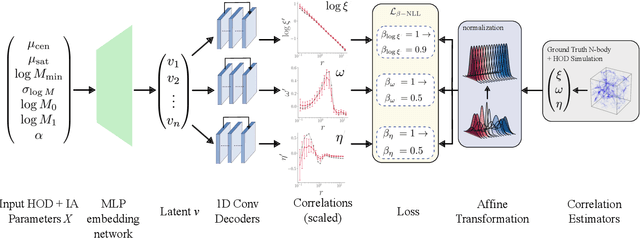
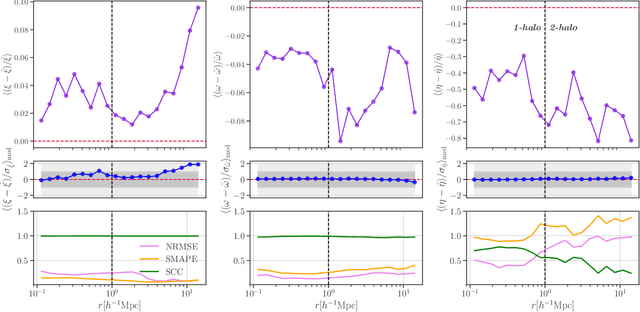
The intrinsic alignments (IA) of galaxies, a key contaminant in weak lensing analyses, arise from correlations in galaxy shapes driven by tidal interactions and galaxy formation processes. Accurate IA modeling is essential for robust cosmological inference, but current approaches rely on perturbative methods that break down on nonlinear scales or on expensive simulations. We introduce IAEmu, a neural network-based emulator that predicts the galaxy position-position ($\xi$), position-orientation ($\omega$), and orientation-orientation ($\eta$) correlation functions and their uncertainties using mock catalogs based on the halo occupation distribution (HOD) framework. Compared to simulations, IAEmu achieves ~3% average error for $\xi$ and ~5% for $\omega$, while capturing the stochasticity of $\eta$ without overfitting. The emulator provides both aleatoric and epistemic uncertainties, helping identify regions where predictions may be less reliable. We also demonstrate generalization to non-HOD alignment signals by fitting to IllustrisTNG hydrodynamical simulation data. As a fully differentiable neural network, IAEmu enables $\sim$10,000$\times$ speed-ups in mapping HOD parameters to correlation functions on GPUs, compared to CPU-based simulations. This acceleration facilitates inverse modeling via gradient-based sampling, making IAEmu a powerful surrogate model for galaxy bias and IA studies with direct applications to Stage IV weak lensing surveys.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
SIDDA: SInkhorn Dynamic Domain Adaptation for Image Classification with Equivariant Neural Networks
Jan 23, 2025



Modern neural networks (NNs) often do not generalize well in the presence of a "covariate shift"; that is, in situations where the training and test data distributions differ, but the conditional distribution of classification labels remains unchanged. In such cases, NN generalization can be reduced to a problem of learning more domain-invariant features. Domain adaptation (DA) methods include a range of techniques aimed at achieving this; however, these methods have struggled with the need for extensive hyperparameter tuning, which then incurs significant computational costs. In this work, we introduce SIDDA, an out-of-the-box DA training algorithm built upon the Sinkhorn divergence, that can achieve effective domain alignment with minimal hyperparameter tuning and computational overhead. We demonstrate the efficacy of our method on multiple simulated and real datasets of varying complexity, including simple shapes, handwritten digits, and real astronomical observations. SIDDA is compatible with a variety of NN architectures, and it works particularly well in improving classification accuracy and model calibration when paired with equivariant neural networks (ENNs). We find that SIDDA enhances the generalization capabilities of NNs, achieving up to a $\approx40\%$ improvement in classification accuracy on unlabeled target data. We also study the efficacy of DA on ENNs with respect to the varying group orders of the dihedral group $D_N$, and find that the model performance improves as the degree of equivariance increases. Finally, we find that SIDDA enhances model calibration on both source and target data--achieving over an order of magnitude improvement in the ECE and Brier score. SIDDA's versatility, combined with its automated approach to domain alignment, has the potential to advance multi-dataset studies by enabling the development of highly generalizable models.
Learning Galaxy Intrinsic Alignment Correlations
Apr 21, 2024



The intrinsic alignments (IA) of galaxies, regarded as a contaminant in weak lensing analyses, represents the correlation of galaxy shapes due to gravitational tidal interactions and galaxy formation processes. As such, understanding IA is paramount for accurate cosmological inferences from weak lensing surveys; however, one limitation to our understanding and mitigation of IA is expensive simulation-based modeling. In this work, we present a deep learning approach to emulate galaxy position-position ($\xi$), position-orientation ($\omega$), and orientation-orientation ($\eta$) correlation function measurements and uncertainties from halo occupation distribution-based mock galaxy catalogs. We find strong Pearson correlation values with the model across all three correlation functions and further predict aleatoric uncertainties through a mean-variance estimation training procedure. $\xi(r)$ predictions are generally accurate to $\leq10\%$. Our model also successfully captures the underlying signal of the noisier correlations $\omega(r)$ and $\eta(r)$, although with a lower average accuracy. We find that the model performance is inhibited by the stochasticity of the data, and will benefit from correlations averaged over multiple data realizations. Our code will be made open source upon journal publication.
E(2) Equivariant Neural Networks for Robust Galaxy Morphology Classification
Nov 02, 2023



We propose the use of group convolutional neural network architectures (GCNNs) equivariant to the 2D Euclidean group, $E(2)$, for the task of galaxy morphology classification by utilizing symmetries of the data present in galaxy images as an inductive bias in the architecture. We conduct robustness studies by introducing artificial perturbations via Poisson noise insertion and one-pixel adversarial attacks to simulate the effects of limited observational capabilities. We train, validate, and test GCNNs equivariant to discrete subgroups of $E(2)$ - the cyclic and dihedral groups of order $N$ - on the Galaxy10 DECals dataset and find that GCNNs achieve higher classification accuracy and are consistently more robust than their non-equivariant counterparts, with an architecture equivariant to the group $D_{16}$ achieving a $95.52 \pm 0.18\%$ test-set accuracy. We also find that the model loses $<6\%$ accuracy on a $50\%$-noise dataset and all GCNNs are less susceptible to one-pixel perturbations than an identically constructed CNN. Our code is publicly available at https://github.com/snehjp2/GCNNMorphology.
AGNet: Weighing Black Holes with Deep Learning
Aug 17, 2021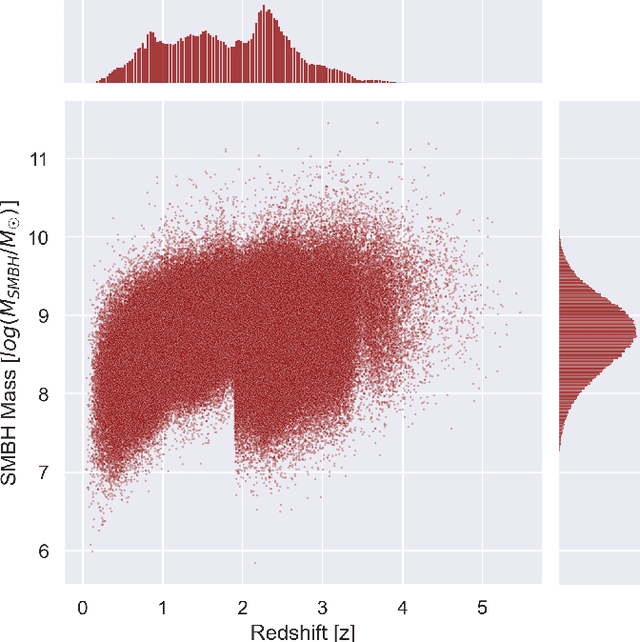
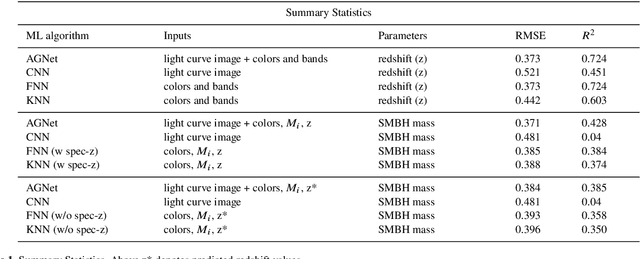
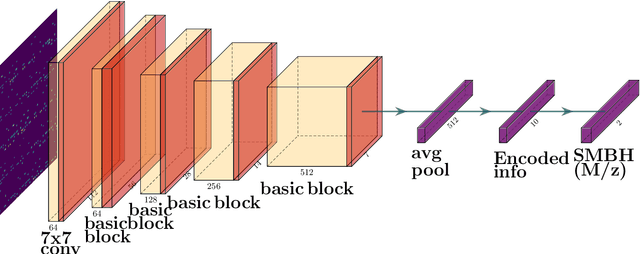
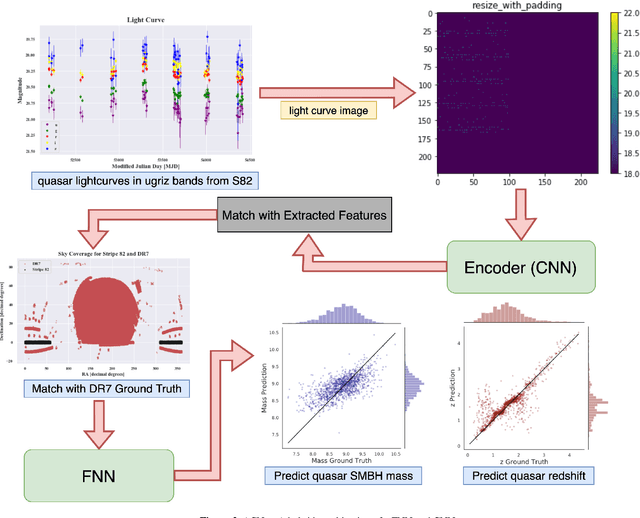
Supermassive black holes (SMBHs) are ubiquitously found at the centers of most massive galaxies. Measuring SMBH mass is important for understanding the origin and evolution of SMBHs. However, traditional methods require spectroscopic data which is expensive to gather. We present an algorithm that weighs SMBHs using quasar light time series, circumventing the need for expensive spectra. We train, validate, and test neural networks that directly learn from the Sloan Digital Sky Survey (SDSS) Stripe 82 light curves for a sample of $38,939$ spectroscopically confirmed quasars to map out the nonlinear encoding between SMBH mass and multi-color optical light curves. We find a 1$\sigma$ scatter of 0.37 dex between the predicted SMBH mass and the fiducial virial mass estimate based on SDSS single-epoch spectra, which is comparable to the systematic uncertainty in the virial mass estimate. Our results have direct implications for more efficient applications with future observations from the Vera C. Rubin Observatory. Our code, \textsf{AGNet}, is publicly available at {\color{red} \url{https://github.com/snehjp2/AGNet}}.
AGNet: Weighing Black Holes with Machine Learning
Dec 01, 2020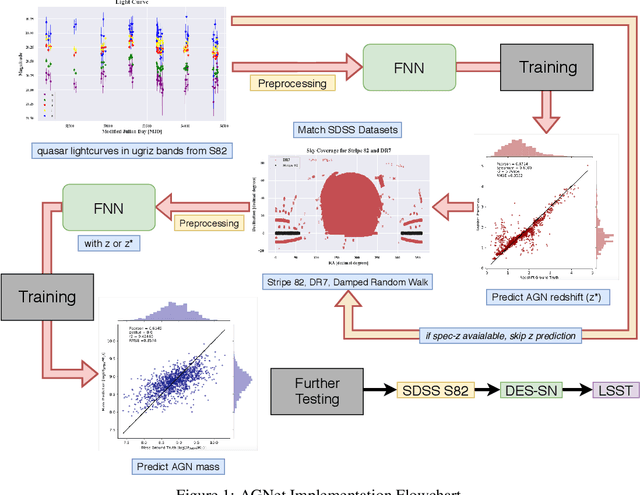
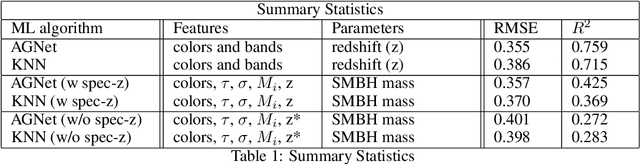

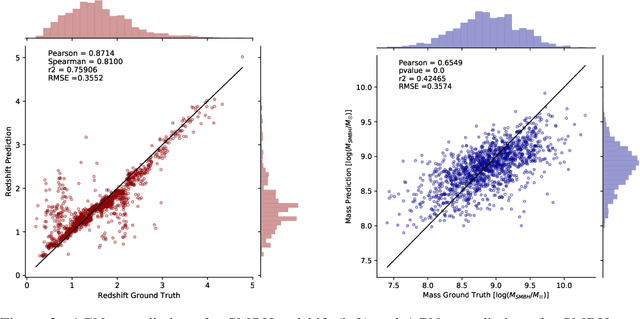
Supermassive black holes (SMBHs) are ubiquitously found at the centers of most galaxies. Measuring SMBH mass is important for understanding the origin and evolution of SMBHs. However, traditional methods require spectral data which is expensive to gather. To solve this problem, we present an algorithm that weighs SMBHs using quasar light time series, circumventing the need for expensive spectra. We train, validate, and test neural networks that directly learn from the Sloan Digital Sky Survey (SDSS) Stripe 82 data for a sample of $9,038$ spectroscopically confirmed quasars to map out the nonlinear encoding between black hole mass and multi-color optical light curves. We find a 1$\sigma$ scatter of 0.35 dex between the predicted mass and the fiducial virial mass based on SDSS single-epoch spectra. Our results have direct implications for efficient applications with future observations from the Vera Rubin Observatory.