 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGNet: Weighing Black Holes with Deep Learning
Aug 17, 2021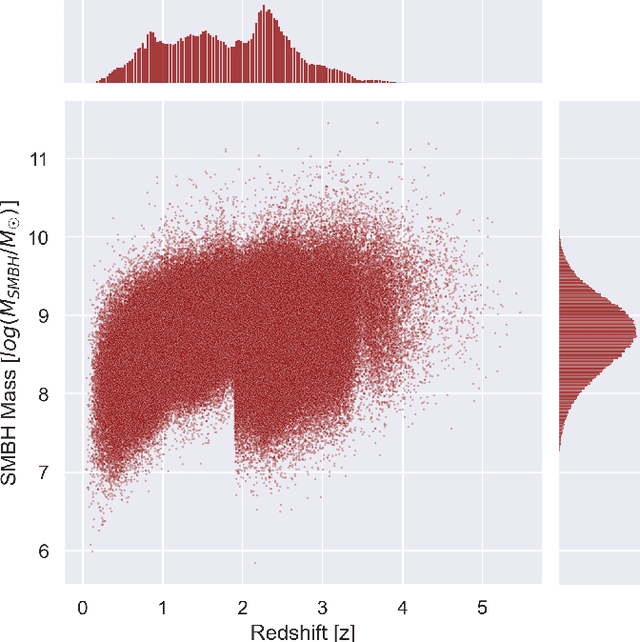
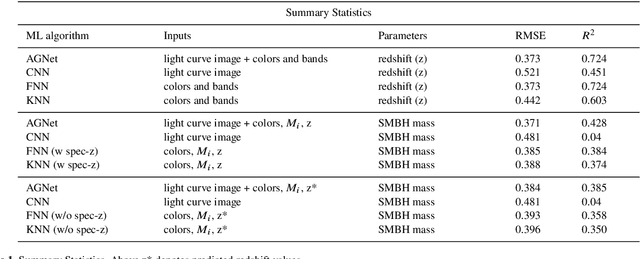
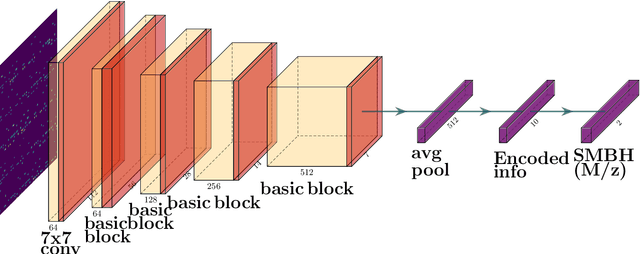
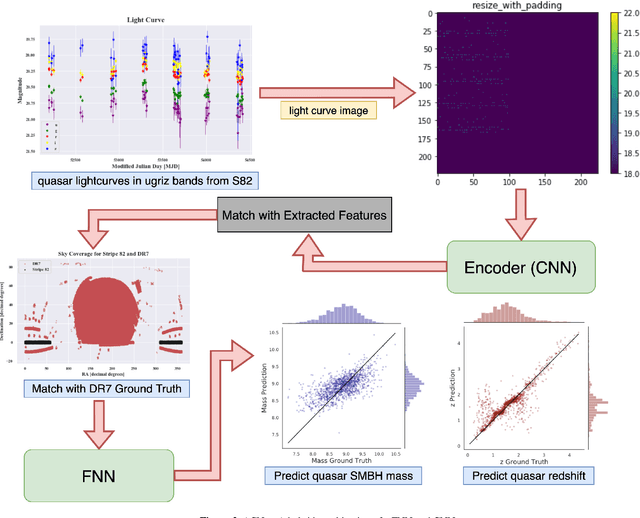
Supermassive black holes (SMBHs) are ubiquitously found at the centers of most massive galaxies. Measuring SMBH mass is important for understanding the origin and evolution of SMBHs. However, traditional methods require spectroscopic data which is expensive to gather. We present an algorithm that weighs SMBHs using quasar light time series, circumventing the need for expensive spectra. We train, validate, and test neural networks that directly learn from the Sloan Digital Sky Survey (SDSS) Stripe 82 light curves for a sample of $38,939$ spectroscopically confirmed quasars to map out the nonlinear encoding between SMBH mass and multi-color optical light curves. We find a 1$\sigma$ scatter of 0.37 dex between the predicted SMBH mass and the fiducial virial mass estimate based on SDSS single-epoch spectra, which is comparable to the systematic uncertainty in the virial mass estimate. Our results have direct implications for more efficient applications with future observations from the Vera C. Rubin Observatory. Our code, \textsf{AGNet}, is publicly available at {\color{red} \url{https://github.com/snehjp2/AGNet}}.
AGNet: Weighing Black Holes with Machine Learning
Dec 01, 2020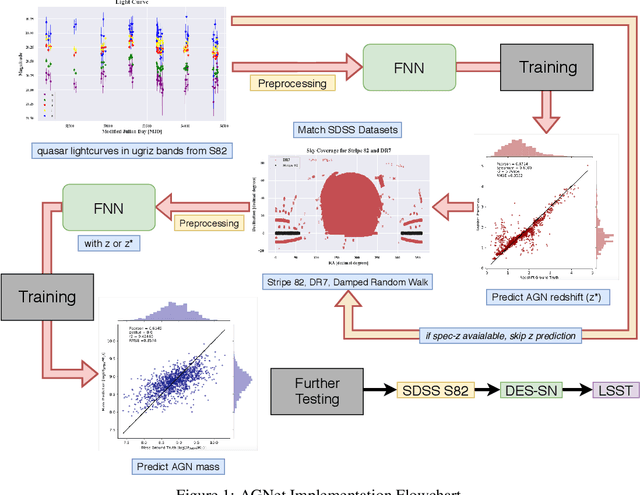
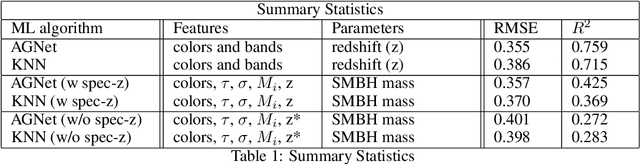

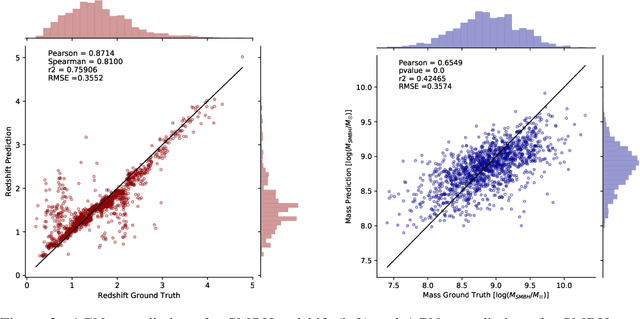
Supermassive black holes (SMBHs) are ubiquitously found at the centers of most galaxies. Measuring SMBH mass is important for understanding the origin and evolution of SMBHs. However, traditional methods require spectral data which is expensive to gather. To solve this problem, we present an algorithm that weighs SMBHs using quasar light time series, circumventing the need for expensive spectra. We train, validate, and test neural networks that directly learn from the Sloan Digital Sky Survey (SDSS) Stripe 82 data for a sample of $9,038$ spectroscopically confirmed quasars to map out the nonlinear encoding between black hole mass and multi-color optical light curves. We find a 1$\sigma$ scatter of 0.35 dex between the predicted mass and the fiducial virial mass based on SDSS single-epoch spectra. Our results have direct implications for efficient applications with future observations from the Vera Rubin Observatory.
Survey2Survey: A deep learning generative model approach for cross-survey image mapping
Nov 13, 2020

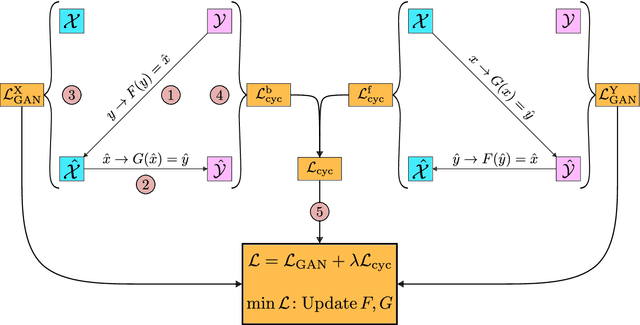
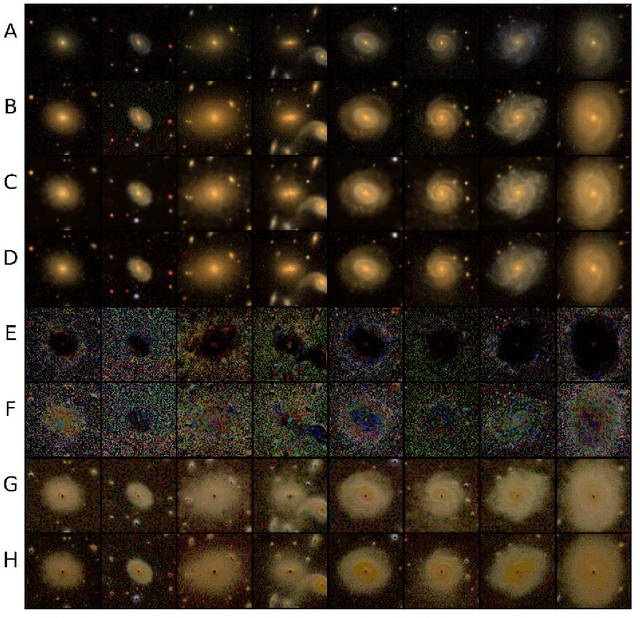
During the last decade, there has been an explosive growth in survey data and deep learning techniques, both of which have enabled great advances for astronomy. The amount of data from various surveys from multiple epochs with a wide range of wavelengths and vast sky coverage, albeit with varying brightness and quality, is overwhelming, and leveraging information from overlapping observations from different surveys has limitless potential in understanding galaxy formation and evolution. Synthetic galaxy image generation using physical models has been an important tool for survey data analysis, while using deep learning generative models shows great promise. In this paper, we present a novel approach for robustly expanding and improving survey data through cross-survey feature translation. We trained two types of generative neural networks to map images from the Sloan Digital Sky Survey (SDSS) into corresponding images from the Dark Energy Survey (DES), increasing the brightness and S/N of the fainter, lower quality source images without losing important morphological information. We demonstrate the robustness of our method by generating DES representations of SDSS images from outside the overlapping region, showing that the brightness and quality are improved even when the source images are of lower quality than the training images. Finally, we highlight several images in which the reconstruction process appears to have removed large artifacts from SDSS images. While only an initial application, our method shows promise as a method for robustly expanding and improving the quality of optical survey data and provides a potential avenue for cross-band reconstruction.
Deep Learning for Multi-Messenger Astrophysics: A Gateway for Discovery in the Big Data Era
Feb 01, 2019This report provides an overview of recent work that harnesses the Big Data Revolution and Large Scale Computing to address grand computational challenges in Multi-Messenger Astrophysics, with a particular emphasis on real-time discovery campaigns. Acknowledging the transdisciplinary nature of Multi-Messenger Astrophysics, this document has been prepared by members of the physics, astronomy, computer science, data science, software and cyberinfrastructure communities who attended the NSF-, DOE- and NVIDIA-funded "Deep Learning for Multi-Messenger Astrophysics: Real-time Discovery at Scale" workshop, hosted at the National Center for Supercomputing Applications, October 17-19, 2018. Highlights of this report include unanimous agreement that it is critical to accelerate the development and deployment of novel, signal-processing algorithms that use the synergy between artificial intelligence (AI) and high performance computing to maximize the potential for scientific discovery with Multi-Messenger Astrophysics. We discuss key aspects to realize this endeavor, namely (i) the design and exploitation of scalable and computationally efficient AI algorithms for Multi-Messenger Astrophysics; (ii) cyberinfrastructure requirements to numerically simulate astrophysical sources, and to process and interpret Multi-Messenger Astrophysics data; (iii) management of gravitational wave detections and triggers to enable electromagnetic and astro-particle follow-ups; (iv) a vision to harness future developments of machine and deep learning and cyberinfrastructure resources to cope with the scale of discovery in the Big Data Era; (v) and the need to build a community that brings domain experts together with data scientists on equal footing to maximize and accelerate discovery in the nascent field of Multi-Messenger Astrophysics.
Extended Isolation Forest
Nov 06, 2018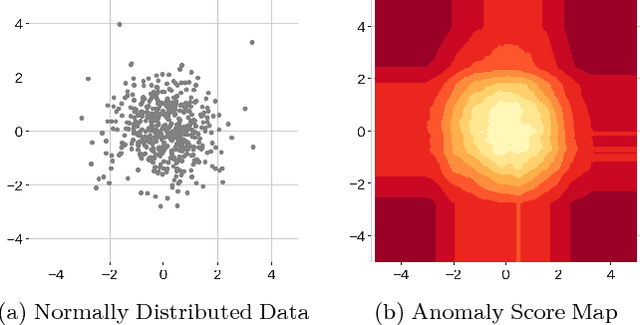
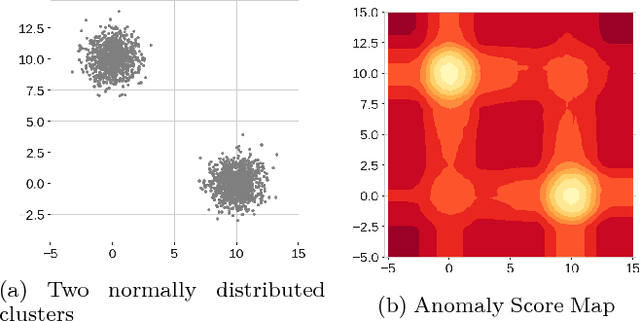
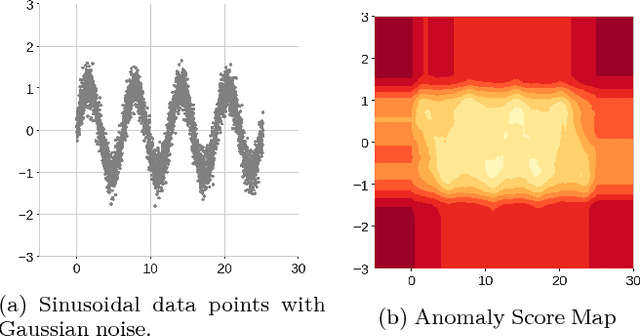
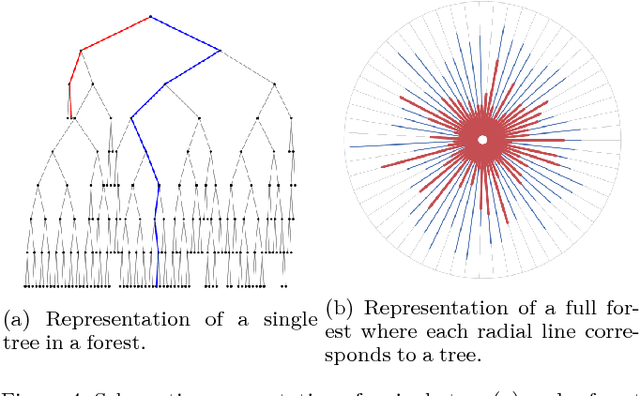
We present an extension to the model-free anomaly detection algorithm, Isolation Forest. This extension, named Extended Isolation Forest (EIF), improves the consistency and reliability of the anomaly score produced for a given data point. We show that the standard Isolation Forest produces inconsistent scores using score maps. The score maps suffer from an artifact generated as a result of how the criteria for branching operation of the binary tree is selected. We propose two different approaches for improving the situation. First we propose transforming the data randomly before creation of each tree, which results in averaging out the bias introduced in the algorithm. Second, which is the preferred way, is to allow the slicing of the data to use hyperplanes with random slopes. This approach results in improved score maps. We show that the consistency and reliability of the algorithm is much improved using this method by looking at the variance of scores of data points distributed along constant score lines. We find no appreciable difference in the rate of convergence nor in computation time between the standard Isolation Forest and EIF, which highlights its potential as anomaly detection algorithm.