 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Judge on a Budget
Feb 17, 2026LLM-as-a-judge has emerged as a cornerstone technique for evaluating large language models by leveraging LLM reasoning to score prompt-response pairs. Since LLM judgments are stochastic, practitioners commonly query each pair multiple times to estimate mean scores accurately. This raises a critical challenge: given a fixed computational budget $B$, how to optimally allocate queries across $K$ prompt-response pairs to minimize estimation error? % We present a principled variance-adaptive approach leveraging multi-armed bandit theory and concentration inequalities. Our method dynamically allocates queries based on estimated score variances, concentrating resources where uncertainty is highest. Further, our algorithm is shown to achieve a worst-case score-estimation error of $\tilde{O}\left(\sqrt{\frac{\sum_{i=1}^K σ_i^2}{B}}\right)$, $σ_i^2$ being the unknown score variance for pair $i \in [K]$ with near-optimal budget allocation. % Experiments on \emph{Summarize-From-Feedback} and \emph{HelpSteer2} demonstrate that our method significantly outperforms uniform allocation, reducing worst-case estimation error while maintaining identical budgets. Our work establishes a theoretical foundation for efficient LLM evaluation with practical implications for AI safety, model alignment, and automated assessment at scale.
One Good Source is All You Need: Near-Optimal Regret for Bandits under Heterogeneous Noise
Feb 16, 2026We study $K$-armed Multiarmed Bandit (MAB) problem with $M$ heterogeneous data sources, each exhibiting unknown and distinct noise variances $\{σ_j^2\}_{j=1}^M$. The learner's objective is standard MAB regret minimization, with the additional complexity of adaptively selecting which data source to query from at each round. We propose Source-Optimistic Adaptive Regret minimization (SOAR), a novel algorithm that quickly prunes high-variance sources using sharp variance-concentration bounds, followed by a `balanced min-max LCB-UCB approach' that seamlessly integrates the parallel tasks of identifying the best arm and the optimal (minimum-variance) data source. Our analysis shows SOAR achieves an instance-dependent regret bound of $\tilde{O}\left({σ^*}^2\sum_{i=2}^K \frac{\log T}{Δ_i} + \sqrt{K \sum_{j=1}^M σ_j^2}\right)$, up to preprocessing costs depending only on problem parameters, where ${σ^*}^2 := \min_j σ_j^2$ is the minimum source variance and $Δ_i$ denotes the suboptimality gap of the $i$-th arm. This result is both surprising as despite lacking prior knowledge of the minimum-variance source among $M$ alternatives, SOAR attains the optimal instance-dependent regret of standard single-source MAB with variance ${σ^*}^2$, while incurring only an small (and unavoidable) additive cost of $\tilde O(\sqrt{K \sum_{j=1}^M σ_j^2})$ towards the optimal (minimum variance) source identification. Our theoretical bounds represent a significant improvement over some proposed baselines, e.g. Uniform UCB or Explore-then-Commit UCB, which could potentially suffer regret scaling with $σ_{\max}^2$ in place of ${σ^*}^2$-a gap that can be arbitrarily large when $σ_{\max} \gg σ^*$. Experiments on multiple synthetic problem instances and the real-world MovieLens\;25M dataset, demonstrating the superior performance of SOAR over the baselines.
Learning to Allocate Resources with Censored Feedback
Feb 06, 2026We study the online resource allocation problem in which at each round, a budget $B$ must be allocated across $K$ arms under censored feedback. An arm yields a reward if and only if two conditions are satisfied: (i) the arm is activated according to an arm-specific Bernoulli random variable with unknown parameter, and (ii) the allocated budget exceeds a random threshold drawn from a parametric distribution with unknown parameter. Over $T$ rounds, the learner must jointly estimate the unknown parameters and allocate the budget so as to maximize cumulative reward facing the exploration--exploitation trade-off. We prove an information-theoretic regret lower bound $Ω(T^{1/3})$, demonstrating the intrinsic difficulty of the problem. We then propose RA-UCB, an optimistic algorithm that leverages non-trivial parameter estimation and confidence bounds. When the budget $B$ is known at the beginning of each round, RA-UCB achieves a regret of order $\widetilde{\mathcal{O}}(\sqrt{T})$, and even $\mathcal{O}(\mathrm{poly}\text{-}\log T)$ under stronger assumptions. As for unknown, round dependent budget, we introduce MG-UCB, which allows within-round switching and infinitesimal allocations, and matches the regret guarantees of RA-UCB. We then validate our theoretical results through experiments on real-world datasets.
Tracking the Best Expert Privately
Mar 12, 2025We design differentially private algorithms for the problem of prediction with expert advice under dynamic regret, also known as tracking the best expert. Our work addresses three natural types of adversaries, stochastic with shifting distributions, oblivious, and adaptive, and designs algorithms with sub-linear regret for all three cases. In particular, under a shifting stochastic adversary where the distribution may shift $S$ times, we provide an $\epsilon$-differentially private algorithm whose expected dynamic regret is at most $O\left( \sqrt{S T \log (NT)} + \frac{S \log (NT)}{\epsilon}\right)$, where $T$ and $N$ are the epsilon horizon and number of experts, respectively. For oblivious adversaries, we give a reduction from dynamic regret minimization to static regret minimization, resulting in an upper bound of $O\left(\sqrt{S T \log(NT)} + \frac{S T^{1/3}\log(T/\delta) \log(NT)}{\epsilon^{2/3}}\right)$ on the expected dynamic regret, where $S$ now denotes the allowable number of switches of the best expert. Finally, similar to static regret, we establish a fundamental separation between oblivious and adaptive adversaries for the dynamic setting: while our algorithms show that sub-linear regret is achievable for oblivious adversaries in the high-privacy regime $\epsilon \le \sqrt{S/T}$, we show that any $(\epsilon, \delta)$-differentially private algorithm must suffer linear dynamic regret under adaptive adversaries for $\epsilon \le \sqrt{S/T}$. Finally, to complement this lower bound, we give an $\epsilon$-differentially private algorithm that attains sub-linear dynamic regret under adaptive adversaries whenever $\epsilon \gg \sqrt{S/T}$.
Hybrid Preference Optimization for Alignment: Provably Faster Convergence Rates by Combining Offline Preferences with Online Exploration
Dec 13, 2024Reinforcement Learning from Human Feedback (RLHF) is currently the leading approach for aligning large language models with human preferences. Typically, these models rely on extensive offline preference datasets for training. However, offline algorithms impose strict concentrability requirements, which are often difficult to satisfy. On the other hand, while online algorithms can avoid the concentrability issue, pure online exploration could be expensive due to the active preference query cost and real-time implementation overhead. In this paper, we propose a novel approach: Hybrid Preference Optimization (HPO) which combines online exploration with existing offline preferences by relaxing the stringent concentrability conditions for offline exploration, as well as significantly improving the sample efficiency for its online counterpart. We give the first provably optimal theoretical bound for Hybrid RLHF with preference feedback, providing sample complexity bounds for policy optimization with matching lower bounds. Our results yield improved sample efficiency of hybrid RLHF over pure offline and online exploration.
Strategic Linear Contextual Bandits
Jun 01, 2024Motivated by the phenomenon of strategic agents gaming a recommender system to maximize the number of times they are recommended to users, we study a strategic variant of the linear contextual bandit problem, where the arms can strategically misreport their privately observed contexts to the learner. We treat the algorithm design problem as one of mechanism design under uncertainty and propose the Optimistic Grim Trigger Mechanism (OptGTM) that incentivizes the agents (i.e., arms) to report their contexts truthfully while simultaneously minimizing regret. We also show that failing to account for the strategic nature of the agents results in linear regret. However, a trade-off between mechanism design and regret minimization appears to be unavoidable. More broadly, this work aims to provide insight into the intersection of online learning and mechanism design.
DP-Dueling: Learning from Preference Feedback without Compromising User Privacy
Mar 22, 2024We consider the well-studied dueling bandit problem, where a learner aims to identify near-optimal actions using pairwise comparisons, under the constraint of differential privacy. We consider a general class of utility-based preference matrices for large (potentially unbounded) decision spaces and give the first differentially private dueling bandit algorithm for active learning with user preferences. Our proposed algorithms are computationally efficient with near-optimal performance, both in terms of the private and non-private regret bound. More precisely, we show that when the decision space is of finite size $K$, our proposed algorithm yields order optimal $O\Big(\sum_{i = 2}^K\log\frac{KT}{\Delta_i} + \frac{K}{\epsilon}\Big)$ regret bound for pure $\epsilon$-DP, where $\Delta_i$ denotes the suboptimality gap of the $i$-th arm. We also present a matching lower bound analysis which proves the optimality of our algorithms. Finally, we extend our results to any general decision space in $d$-dimensions with potentially infinite arms and design an $\epsilon$-DP algorithm with regret $\tilde{O} \left( \frac{d^6}{\kappa \epsilon } + \frac{ d\sqrt{T }}{\kappa} \right)$, providing privacy for free when $T \gg d$.
Stop Relying on No-Choice and Do not Repeat the Moves: Optimal, Efficient and Practical Algorithms for Assortment Optimization
Feb 29, 2024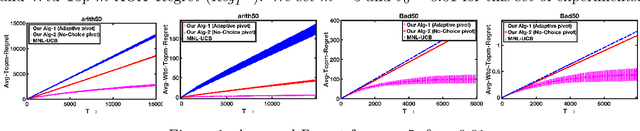
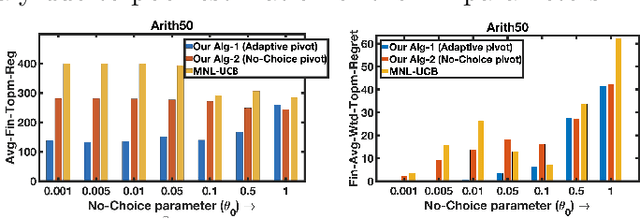
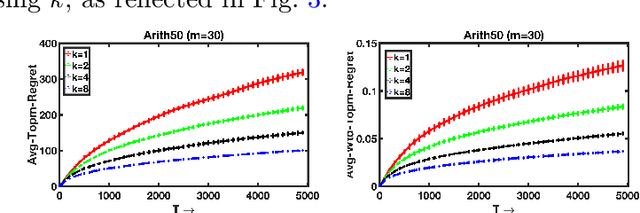
We address the problem of active online assortment optimization problem with preference feedback, which is a framework for modeling user choices and subsetwise utility maximization. The framework is useful in various real-world applications including ad placement, online retail, recommender systems, fine-tuning language models, amongst many. The problem, although has been studied in the past, lacks an intuitive and practical solution approach with simultaneously efficient algorithm and optimal regret guarantee. E.g., popularly used assortment selection algorithms often require the presence of a `strong reference' which is always included in the choice sets, further they are also designed to offer the same assortments repeatedly until the reference item gets selected -- all such requirements are quite unrealistic for practical applications. In this paper, we designed efficient algorithms for the problem of regret minimization in assortment selection with \emph{Plackett Luce} (PL) based user choices. We designed a novel concentration guarantee for estimating the score parameters of the PL model using `\emph{Pairwise Rank-Breaking}', which builds the foundation of our proposed algorithms. Moreover, our methods are practical, provably optimal, and devoid of the aforementioned limitations of the existing methods. Empirical evaluations corroborate our findings and outperform the existing baselines.
Think Before You Duel: Understanding Complexities of Preference Learning under Constrained Resources
Dec 28, 2023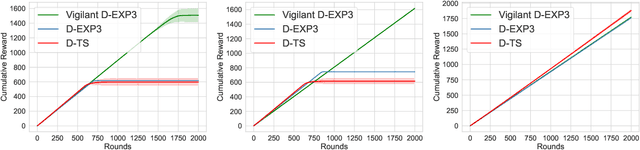
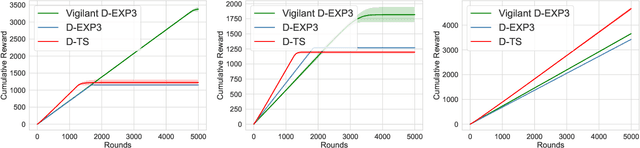
We consider the problem of reward maximization in the dueling bandit setup along with constraints on resource consumption. As in the classic dueling bandits, at each round the learner has to choose a pair of items from a set of $K$ items and observe a relative feedback for the current pair. Additionally, for both items, the learner also observes a vector of resource consumptions. The objective of the learner is to maximize the cumulative reward, while ensuring that the total consumption of any resource is within the allocated budget. We show that due to the relative nature of the feedback, the problem is more difficult than its bandit counterpart and that without further assumptions the problem is not learnable from a regret minimization perspective. Thereafter, by exploiting assumptions on the available budget, we provide an EXP3 based dueling algorithm that also considers the associated consumptions and show that it achieves an $\tilde{\mathcal{O}}\left({\frac{OPT^{(b)}}{B}}K^{1/3}T^{2/3}\right)$ regret, where $OPT^{(b)}$ is the optimal value and $B$ is the available budget. Finally, we provide numerical simulations to demonstrate the efficacy of our proposed method.
Faster Convergence with Multiway Preferences
Dec 19, 2023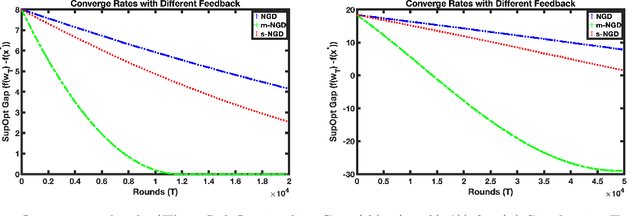
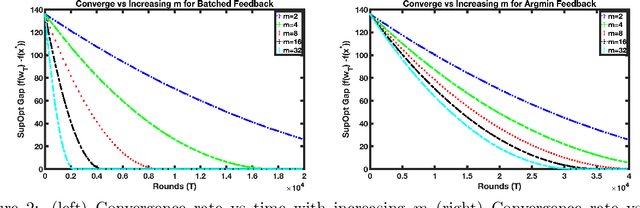
We address the problem of convex optimization with preference feedback, where the goal is to minimize a convex function given a weaker form of comparison queries. Each query consists of two points and the dueling feedback returns a (noisy) single-bit binary comparison of the function values of the two queried points. Here we consider the sign-function-based comparison feedback model and analyze the convergence rates with batched and multiway (argmin of a set queried points) comparisons. Our main goal is to understand the improved convergence rates owing to parallelization in sign-feedback-based optimization problems. Our work is the first to study the problem of convex optimization with multiway preferences and analyze the optimal convergence rates. Our first contribution lies in designing efficient algorithms with a convergence rate of $\smash{\widetilde O}(\frac{d}{\min\{m,d\} \epsilon})$ for $m$-batched preference feedback where the learner can query $m$-pairs in parallel. We next study a $m$-multiway comparison (`battling') feedback, where the learner can get to see the argmin feedback of $m$-subset of queried points and show a convergence rate of $\smash{\widetilde O}(\frac{d}{ \min\{\log m,d\}\epsilon })$. We show further improved convergence rates with an additional assumption of strong convexity. Finally, we also study the convergence lower bounds for batched preferences and multiway feedback optimization showing the optimality of our convergence rates w.r.t. $m$.