 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Relying on No-Choice and Do not Repeat the Moves: Optimal, Efficient and Practical Algorithms for Assortment Optimization
Paper and Code
Feb 29, 2024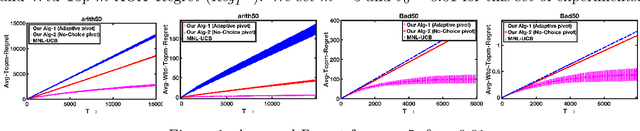
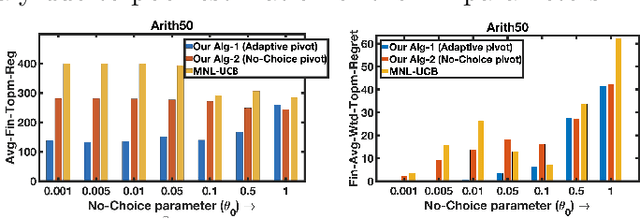
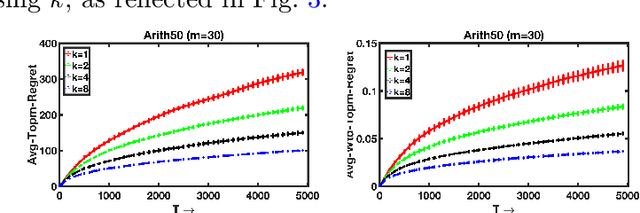
We address the problem of active online assortment optimization problem with preference feedback, which is a framework for modeling user choices and subsetwise utility maximization. The framework is useful in various real-world applications including ad placement, online retail, recommender systems, fine-tuning language models, amongst many. The problem, although has been studied in the past, lacks an intuitive and practical solution approach with simultaneously efficient algorithm and optimal regret guarantee. E.g., popularly used assortment selection algorithms often require the presence of a `strong reference' which is always included in the choice sets, further they are also designed to offer the same assortments repeatedly until the reference item gets selected -- all such requirements are quite unrealistic for practical applications. In this paper, we designed efficient algorithms for the problem of regret minimization in assortment selection with \emph{Plackett Luce} (PL) based user choices. We designed a novel concentration guarantee for estimating the score parameters of the PL model using `\emph{Pairwise Rank-Breaking}', which builds the foundation of our proposed algorithms. Moreover, our methods are practical, provably optimal, and devoid of the aforementioned limitations of the existing methods. Empirical evaluations corroborate our findings and outperform the existing baselines.