 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVRL: Learning Reward Functions from Multiple Feedback Types with Amortized Variational Inference
Feb 16, 2026Reward learning typically relies on a single feedback type or combines multiple feedback types using manually weighted loss terms. Currently, it remains unclear how to jointly learn reward functions from heterogeneous feedback types such as demonstrations, comparisons, ratings, and stops that provide qualitatively different signals. We address this challenge by formulating reward learning from multiple feedback types as Bayesian inference over a shared latent reward function, where each feedback type contributes information through an explicit likelihood. We introduce a scalable amortized variational inference approach that learns a shared reward encoder and feedback-specific likelihood decoders and is trained by optimizing a single evidence lower bound. Our approach avoids reducing feedback to a common intermediate representation and eliminates the need for manual loss balancing. Across discrete and continuous-control benchmarks, we show that jointly inferred reward posteriors outperform single-type baselines, exploit complementary information across feedback types, and yield policies that are more robust to environment perturbations. The inferred reward uncertainty further provides interpretable signals for analyzing model confidence and consistency across feedback types.
Reinforcement Learning via Self-Distillation
Jan 28, 2026Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
Stackelberg Learning from Human Feedback: Preference Optimization as a Sequential Game
Dec 18, 2025We introduce Stackelberg Learning from Human Feedback (SLHF), a new framework for preference optimization. SLHF frames the alignment problem as a sequential-move game between two policies: a Leader, which commits to an action, and a Follower, which responds conditionally on the Leader's action. This approach decomposes preference optimization into a refinement problem for the Follower and an optimization problem against an adversary for the Leader. Unlike Reinforcement Learning from Human Feedback (RLHF), which assigns scalar rewards to actions, or Nash Learning from Human Feedback (NLHF), which seeks a simultaneous-move equilibrium, SLHF leverages the asymmetry of sequential play to capture richer preference structures. The sequential design of SLHF naturally enables inference-time refinement, as the Follower learns to improve the Leader's actions, and these refinements can be leveraged through iterative sampling. We compare the solution concepts of SLHF, RLHF, and NLHF, and lay out key advantages in consistency, data sensitivity, and robustness to intransitive preferences. Experiments on large language models demonstrate that SLHF achieves strong alignment across diverse preference datasets, scales from 0.5B to 8B parameters, and yields inference-time refinements that transfer across model families without further fine-tuning.
Strategyproof Reinforcement Learning from Human Feedback
Mar 12, 2025We study Reinforcement Learning from Human Feedback (RLHF), where multiple individuals with diverse preferences provide feedback strategically to sway the final policy in their favor. We show that existing RLHF methods are not strategyproof, which can result in learning a substantially misaligned policy even when only one out of $k$ individuals reports their preferences strategically. In turn, we also find that any strategyproof RLHF algorithm must perform $k$-times worse than the optimal policy, highlighting an inherent trade-off between incentive alignment and policy alignment. We then propose a pessimistic median algorithm that, under appropriate coverage assumptions, is approximately strategyproof and converges to the optimal policy as the number of individuals and samples increases.
A Unifying Framework for Causal Imitation Learning with Hidden Confounders
Feb 11, 2025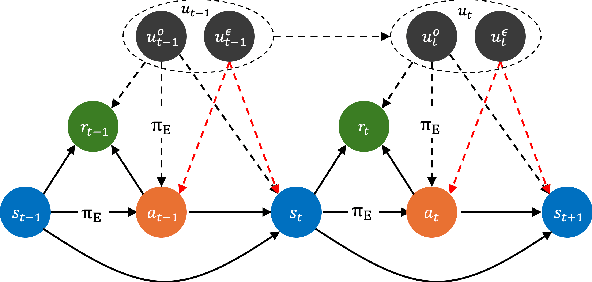

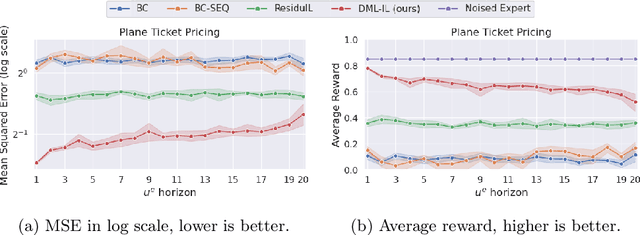
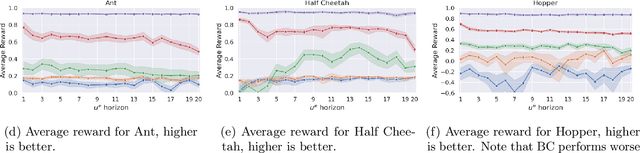
We propose a general and unifying framework for causal Imitation Learning (IL) with hidden confounders that subsumes several existing confounded IL settings from the literature. Our framework accounts for two types of hidden confounders: (a) those observed by the expert, which thus influence the expert's policy, and (b) confounding noise hidden to both the expert and the IL algorithm. For additional flexibility, we also introduce a confounding noise horizon and time-varying expert-observable hidden variables. We show that causal IL in our framework can be reduced to a set of Conditional Moment Restrictions (CMRs) by leveraging trajectory histories as instruments to learn a history-dependent policy. We propose DML-IL, a novel algorithm that uses instrumental variable regression to solve these CMRs and learn a policy. We provide a bound on the imitation gap for DML-IL, which recovers prior results as special cases. Empirical evaluation on a toy environment with continues state-action spaces and multiple Mujoco tasks demonstrate that DML-IL outperforms state-of-the-art causal IL algorithms.
A Minimax Approach to Ad Hoc Teamwork
Feb 04, 2025We propose a minimax-Bayes approach to Ad Hoc Teamwork (AHT) that optimizes policies against an adversarial prior over partners, explicitly accounting for uncertainty about partners at time of deployment. Unlike existing methods that assume a specific distribution over partners, our approach improves worst-case performance guarantees. Extensive experiments, including evaluations on coordinated cooking tasks from the Melting Pot suite, show our method's superior robustness compared to self-play, fictitious play, and best response learning. Our work highlights the importance of selecting an appropriate training distribution over teammates to achieve robustness in AHT.
Strategic Linear Contextual Bandits
Jun 01, 2024Motivated by the phenomenon of strategic agents gaming a recommender system to maximize the number of times they are recommended to users, we study a strategic variant of the linear contextual bandit problem, where the arms can strategically misreport their privately observed contexts to the learner. We treat the algorithm design problem as one of mechanism design under uncertainty and propose the Optimistic Grim Trigger Mechanism (OptGTM) that incentivizes the agents (i.e., arms) to report their contexts truthfully while simultaneously minimizing regret. We also show that failing to account for the strategic nature of the agents results in linear regret. However, a trade-off between mechanism design and regret minimization appears to be unavoidable. More broadly, this work aims to provide insight into the intersection of online learning and mechanism design.
Bandits Meet Mechanism Design to Combat Clickbait in Online Recommendation
Nov 27, 2023
We study a strategic variant of the multi-armed bandit problem, which we coin the strategic click-bandit. This model is motivated by applications in online recommendation where the choice of recommended items depends on both the click-through rates and the post-click rewards. Like in classical bandits, rewards follow a fixed unknown distribution. However, we assume that the click-rate of each arm is chosen strategically by the arm (e.g., a host on Airbnb) in order to maximize the number of times it gets clicked. The algorithm designer does not know the post-click rewards nor the arms' actions (i.e., strategically chosen click-rates) in advance, and must learn both values over time. To solve this problem, we design an incentive-aware learning algorithm, UCB-S, which achieves two goals simultaneously: (a) incentivizing desirable arm behavior under uncertainty; (b) minimizing regret by learning unknown parameters. We characterize all approximate Nash equilibria among arms under UCB-S and show a $\tilde{\mathcal{O}} (\sqrt{KT})$ regret bound uniformly in every equilibrium. We also show that incentive-unaware algorithms generally fail to achieve low regret in the strategic click-bandit. Finally, we support our theoretical results by simulations of strategic arm behavior which confirm the effectiveness and robustness of our proposed incentive design.
Minimax-Bayes Reinforcement Learning
Feb 21, 2023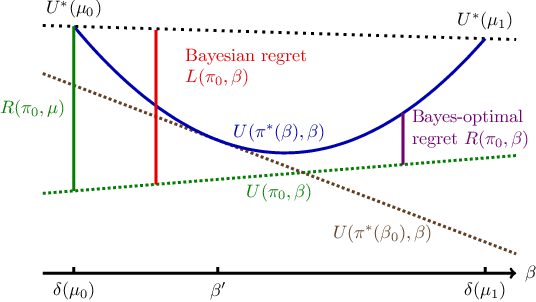

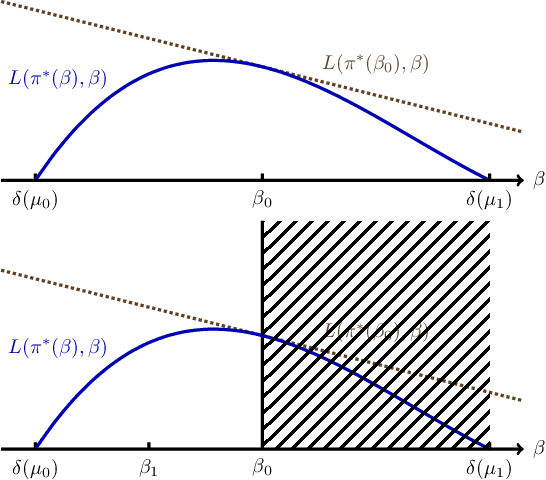
While the Bayesian decision-theoretic framework offers an elegant solution to the problem of decision making under uncertainty, one question is how to appropriately select the prior distribution. One idea is to employ a worst-case prior. However, this is not as easy to specify in sequential decision making as in simple statistical estimation problems. This paper studies (sometimes approximate) minimax-Bayes solutions for various reinforcement learning problems to gain insights into the properties of the corresponding priors and policies. We find that while the worst-case prior depends on the setting, the corresponding minimax policies are more robust than those that assume a standard (i.e. uniform) prior.
Environment Design for Inverse Reinforcement Learning
Oct 26, 2022The task of learning a reward function from expert demonstrations suffers from high sample complexity as well as inherent limitations to what can be learned from demonstrations in a given environment. As the samples used for reward learning require human input, which is generally expensive, much effort has been dedicated towards designing more sample-efficient algorithms. Moreover, even with abundant data, current methods can still fail to learn insightful reward functions that are robust to minor changes in the environment dynamics. We approach these challenges differently than prior work by improving the sample-efficiency as well as the robustness of learned rewards through adaptively designing a sequence of demonstration environments for the expert to act in. We formalise a framework for this environment design process in which learner and expert repeatedly interact, and construct algorithms that actively seek information about the rewards by carefully curating environments for the human to demonstrate the task in.