 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Minimax Approach to Ad Hoc Teamwork
Feb 04, 2025We propose a minimax-Bayes approach to Ad Hoc Teamwork (AHT) that optimizes policies against an adversarial prior over partners, explicitly accounting for uncertainty about partners at time of deployment. Unlike existing methods that assume a specific distribution over partners, our approach improves worst-case performance guarantees. Extensive experiments, including evaluations on coordinated cooking tasks from the Melting Pot suite, show our method's superior robustness compared to self-play, fictitious play, and best response learning. Our work highlights the importance of selecting an appropriate training distribution over teammates to achieve robustness in AHT.
Effects of Different Optimization Formulations in Evolutionary Reinforcement Learning on Diverse Behavior Generation
Oct 20, 2021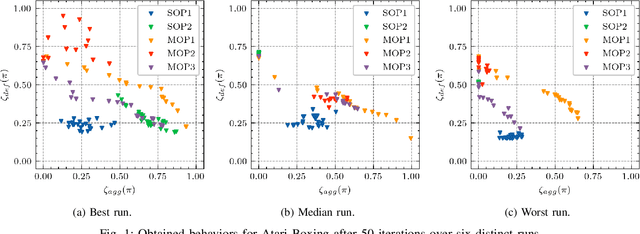
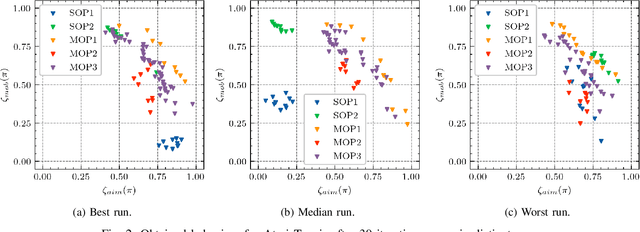
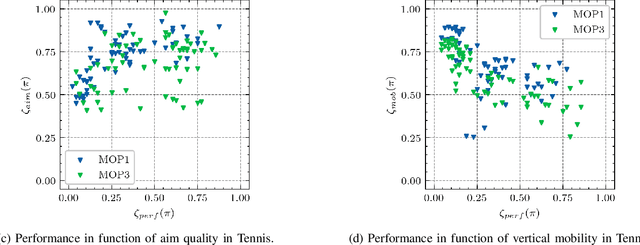

Generating various strategies for a given task is challenging. However, it has already proven to bring many assets to the main learning process, such as improved behavior exploration. With the growth in the interest of heterogeneity in solution in evolutionary computation and reinforcement learning, many promising approaches have emerged. To better understand how one guides multiple policies toward distinct strategies and benefit from diversity, we need to analyze further the influence of the reward signal modulation and other evolutionary mechanisms on the obtained behaviors. To that effect, this paper considers an existing evolutionary reinforcement learning framework which exploits multi-objective optimization as a way to obtain policies that succeed at behavior-related tasks as well as completing the main goal. Experiments on the Atari games stress that optimization formulations which do not consider objectives equally fail at generating diversity and even output agents that are worse at solving the problem at hand, regardless of the obtained behaviors.