 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating White and Black Box Techniques for Interpretable Machine Learning
Jul 12, 2024In machine learning algorithm design, there exists a trade-off between the interpretability and performance of the algorithm. In general, algorithms which are simpler and easier for humans to comprehend tend to show worse performance than more complex, less transparent algorithms. For example, a random forest classifier is likely to be more accurate than a simple decision tree, but at the expense of interpretability. In this paper, we present an ensemble classifier design which classifies easier inputs using a highly-interpretable classifier (i.e., white box model), and more difficult inputs using a more powerful, but less interpretable classifier (i.e., black box model).
Privacy-preserving Continual Federated Clustering via Adaptive Resonance Theory
Sep 07, 2023


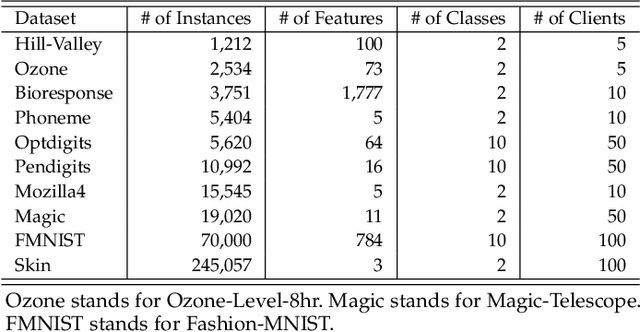
With the increasing importance of data privacy protection, various privacy-preserving machine learning methods have been proposed. In the clustering domain, various algorithms with a federated learning framework (i.e., federated clustering) have been actively studied and showed high clustering performance while preserving data privacy. However, most of the base clusterers (i.e., clustering algorithms) used in existing federated clustering algorithms need to specify the number of clusters in advance. These algorithms, therefore, are unable to deal with data whose distributions are unknown or continually changing. To tackle this problem, this paper proposes a privacy-preserving continual federated clustering algorithm. In the proposed algorithm, an adaptive resonance theory-based clustering algorithm capable of continual learning is used as a base clusterer. Therefore, the proposed algorithm inherits the ability of continual learning. Experimental results with synthetic and real-world datasets show that the proposed algorithm has superior clustering performance to state-of-the-art federated clustering algorithms while realizing data privacy protection and continual learning ability. The source code is available at \url{https://github.com/Masuyama-lab/FCAC}.
A Parameter-free Adaptive Resonance Theory-based Topological Clustering Algorithm Capable of Continual Learning
May 03, 2023



In general, a similarity threshold (i.e., a vigilance parameter) for a node learning process in Adaptive Resonance Theory (ART)-based algorithms has a significant impact on clustering performance. In addition, an edge deletion threshold in a topological clustering algorithm plays an important role in adaptively generating well-separated clusters during a self-organizing process. In this paper, we propose a new parameter-free ART-based topological clustering algorithm capable of continual learning by introducing parameter estimation methods. Experimental results with synthetic and real-world datasets show that the proposed algorithm has superior clustering performance to the state-of-the-art clustering algorithms without any parameter pre-specifications.
Reference Vector Adaptation and Mating Selection Strategy via Adaptive Resonance Theory-based Clustering for Many-objective Optimization
May 04, 2022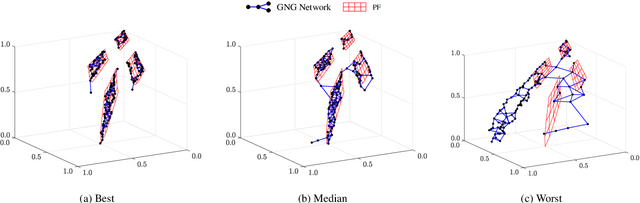
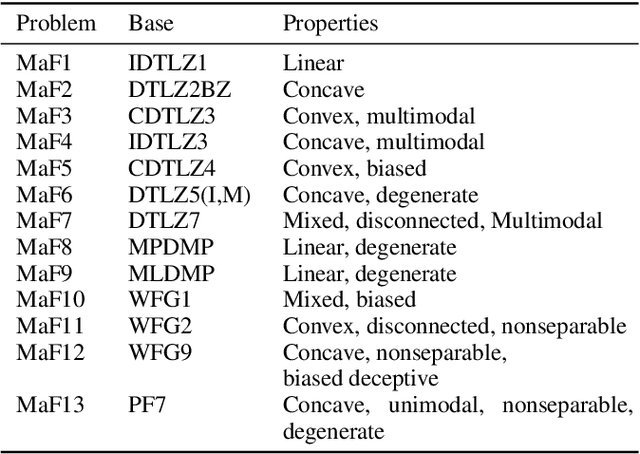
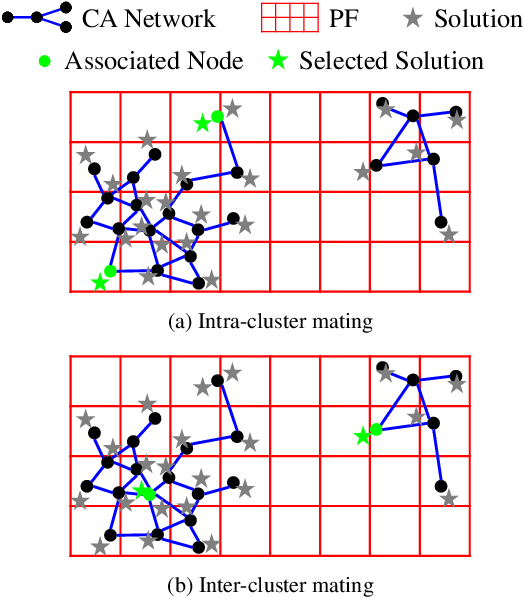

Decomposition-based multiobjective evolutionary algorithms (MOEAs) with clustering-based reference vector adaptation show good optimization performance for many-objective optimization problems (MaOPs). Especially, algorithms that employ a clustering algorithm with a topological structure (i.e., a network composed of nodes and edges) show superior optimization performance to other MOEAs for MaOPs with irregular Pareto optimal fronts (PFs). These algorithms, however, do not effectively utilize information of the topological structure in the search process. Moreover, the clustering algorithms typically used in conventional studies have limited clustering performance, inhibiting the ability to extract useful information for the search process. This paper proposes an adaptive reference vector-guided evolutionary algorithm using an adaptive resonance theory-based clustering with a topological structure. The proposed algorithm utilizes the information of the topological structure not only for reference vector adaptation but also for mating selection. The proposed algorithm is compared with 8 state-of-the-art MOEAs on 78 test problems. Experimental results reveal the outstanding optimization performance of the proposed algorithm over the others on MaOPs with various properties.
Class-wise Classifier Design Capable of Continual Learning using Adaptive Resonance Theory-based Topological Clustering
Mar 18, 2022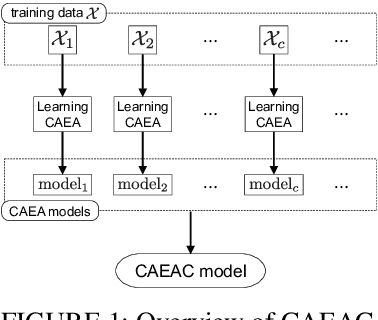

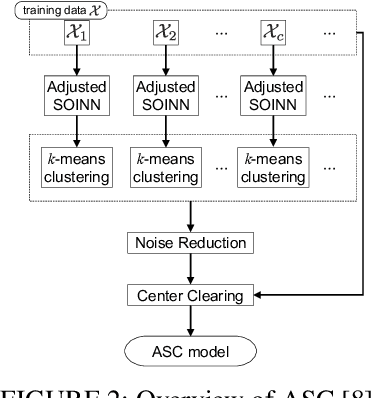
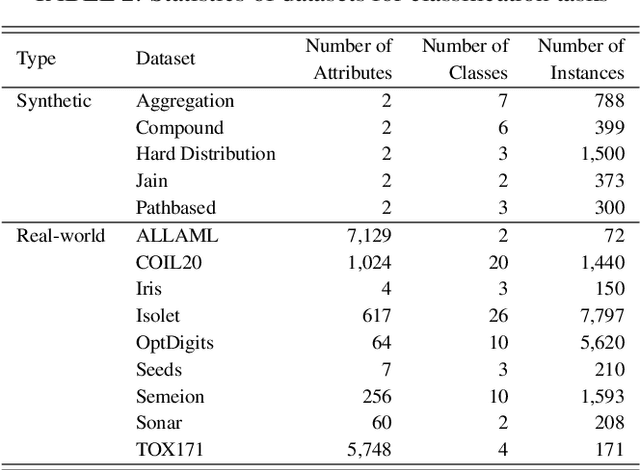
This paper proposes a supervised classification algorithm capable of continual learning by utilizing an Adaptive Resonance Theory (ART)-based growing self-organizing clustering algorithm. The ART-based clustering algorithm is theoretically capable of continual learning, and the proposed algorithm independently applies it to each class of training data for generating classifiers. Whenever an additional training data set from a new class is given, a new ART-based clustering will be defined in a different learning space. Thanks to the above-mentioned features, the proposed algorithm realizes continual learning capability. Simulation experiments showed that the proposed algorithm has superior classification performance compared with state-of-the-art clustering-based classification algorithms capable of continual learning.
Adaptive Resonance Theory-based Topological Clustering with a Divisive Hierarchical Structure Capable of Continual Learning
Feb 02, 2022
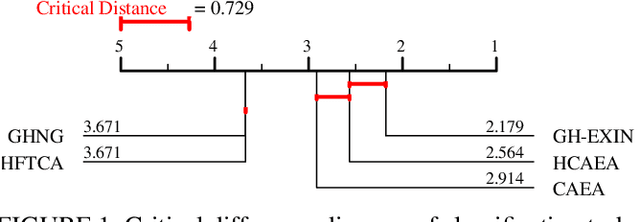
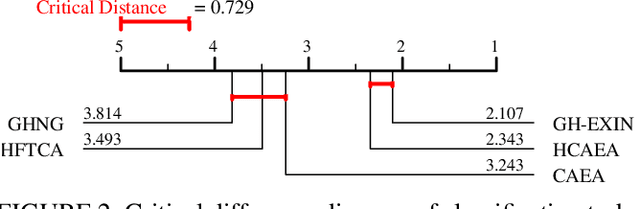
Adaptive Resonance Theory (ART) is considered as an effective approach for realizing continual learning thanks to its ability to handle the plasticity-stability dilemma. In general, however, the clustering performance of ART-based algorithms strongly depends on the specification of a similarity threshold, i.e., a vigilance parameter, which is data-dependent and specified by hand. This paper proposes an ART-based topological clustering algorithm with a mechanism that automatically estimates a similarity threshold from the distribution of data points. In addition, for improving information extraction performance, a divisive hierarchical clustering algorithm capable of continual learning is proposed by introducing a hierarchical structure to the proposed algorithm. Experimental results demonstrate that the proposed algorithm has high clustering performance comparable with recently-proposed state-of-the-art hierarchical clustering algorithms.
Effects of Different Optimization Formulations in Evolutionary Reinforcement Learning on Diverse Behavior Generation
Oct 20, 2021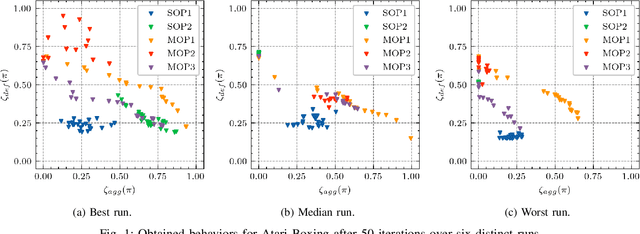
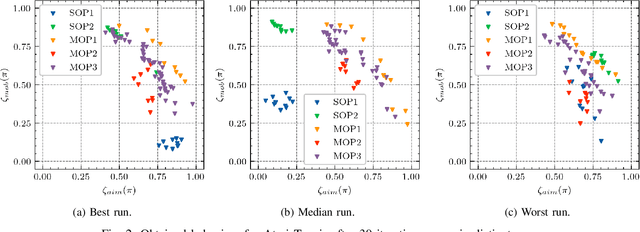

Generating various strategies for a given task is challenging. However, it has already proven to bring many assets to the main learning process, such as improved behavior exploration. With the growth in the interest of heterogeneity in solution in evolutionary computation and reinforcement learning, many promising approaches have emerged. To better understand how one guides multiple policies toward distinct strategies and benefit from diversity, we need to analyze further the influence of the reward signal modulation and other evolutionary mechanisms on the obtained behaviors. To that effect, this paper considers an existing evolutionary reinforcement learning framework which exploits multi-objective optimization as a way to obtain policies that succeed at behavior-related tasks as well as completing the main goal. Experiments on the Atari games stress that optimization formulations which do not consider objectives equally fail at generating diversity and even output agents that are worse at solving the problem at hand, regardless of the obtained behaviors.
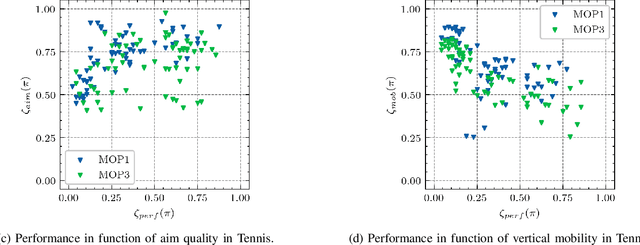
Multi-label Classification via Adaptive Resonance Theory-based Clustering
Mar 03, 2021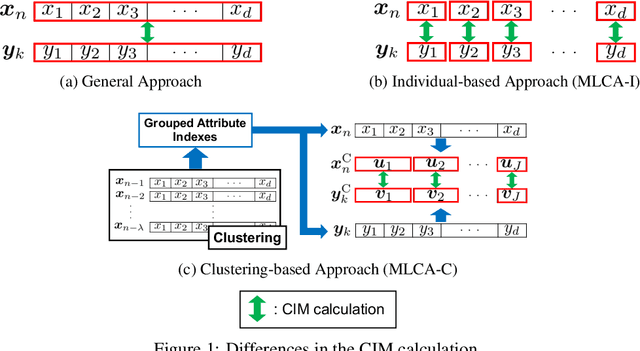

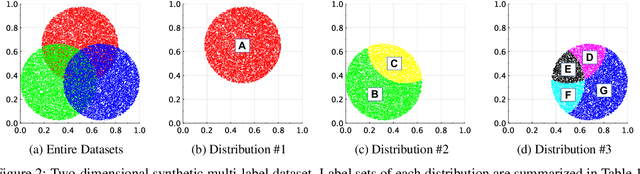
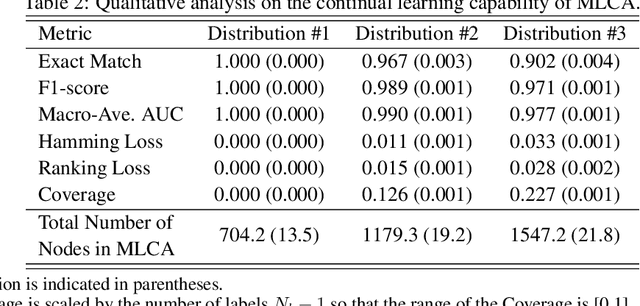
This paper proposes a multi-label classification algorithm capable of continual learning by applying an Adaptive Resonance Theory (ART)-based clustering algorithm and the Bayesian approach for label probability computation. The ART-based clustering algorithm adaptively and continually generates prototype nodes corresponding to given data, and the generated nodes are used as classifiers. The label probability computation independently counts the number of label appearances for each class and calculates the Bayesian probabilities. Thus, the label probability computation can cope with an increase in the number of labels. Experimental results with synthetic and real-world multi-label datasets show that the proposed algorithm has competitive classification performance to other well-known algorithms while realizing continual learning.
Identifying Properties of Real-World Optimisation Problems through a Questionnaire
Nov 11, 2020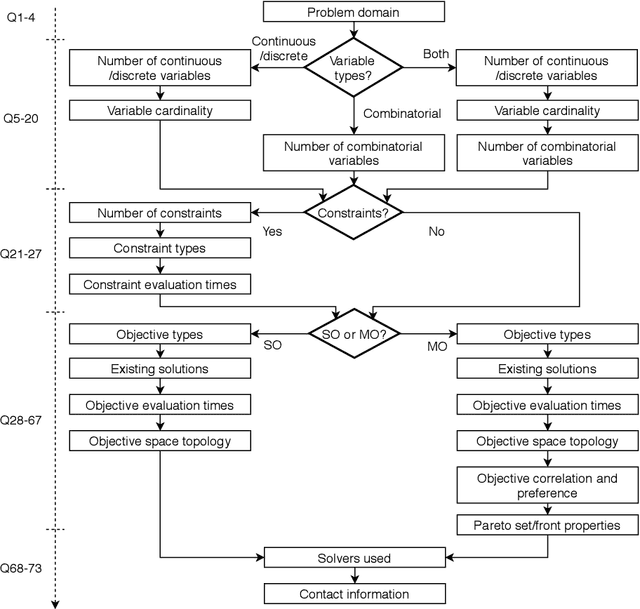
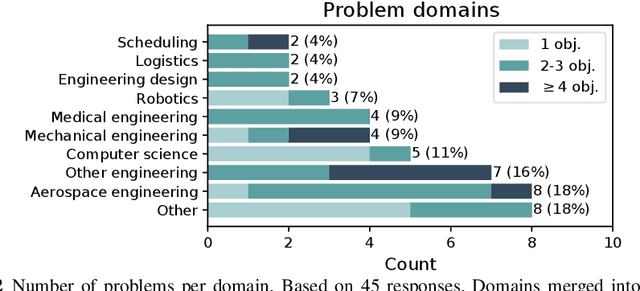
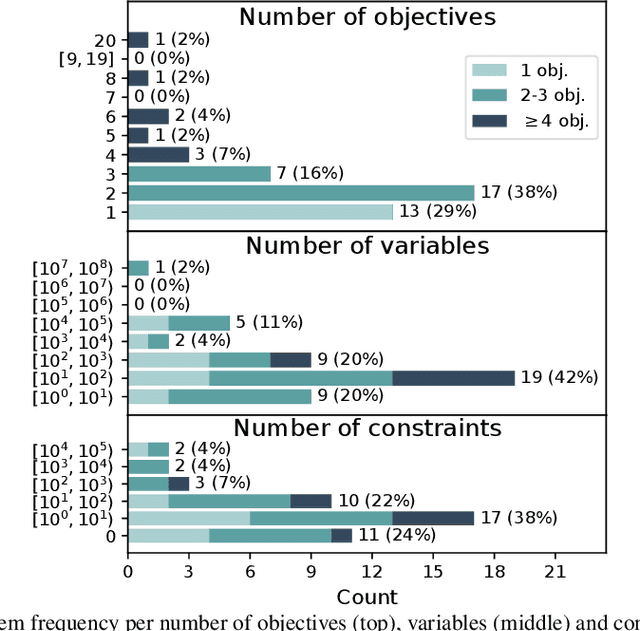
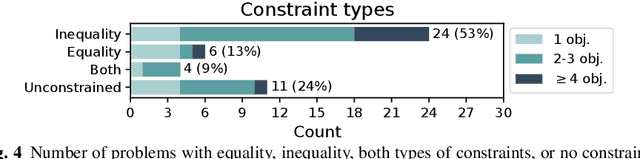
Optimisation algorithms are commonly compared on benchmarks to get insight into performance differences. However, it is not clear how closely benchmarks match the properties of real-world problems because these properties are largely unknown. This work investigates the properties of real-world problems through a questionnaire to enable the design of future benchmark problems that more closely resemble those found in the real world. The results, while not representative, show that many problems possess at least one of the following properties: they are constrained, deterministic, have only continuous variables, require substantial computation times for both the objectives and the constraints, or allow a limited number of evaluations. Properties like known optimal solutions and analytical gradients are rarely available, limiting the options in guiding the optimisation process. These are all important aspects to consider when designing realistic benchmark problems. At the same time, objective functions are often reported to be black-box and since many problem properties are unknown the design of realistic benchmarks is difficult. To further improve the understanding of real-world problems, readers working on a real-world optimisation problem are encouraged to fill out the questionnaire: https://tinyurl.com/opt-survey
Towards Realistic Optimization Benchmarks: A Questionnaire on the Properties of Real-World Problems
Apr 14, 2020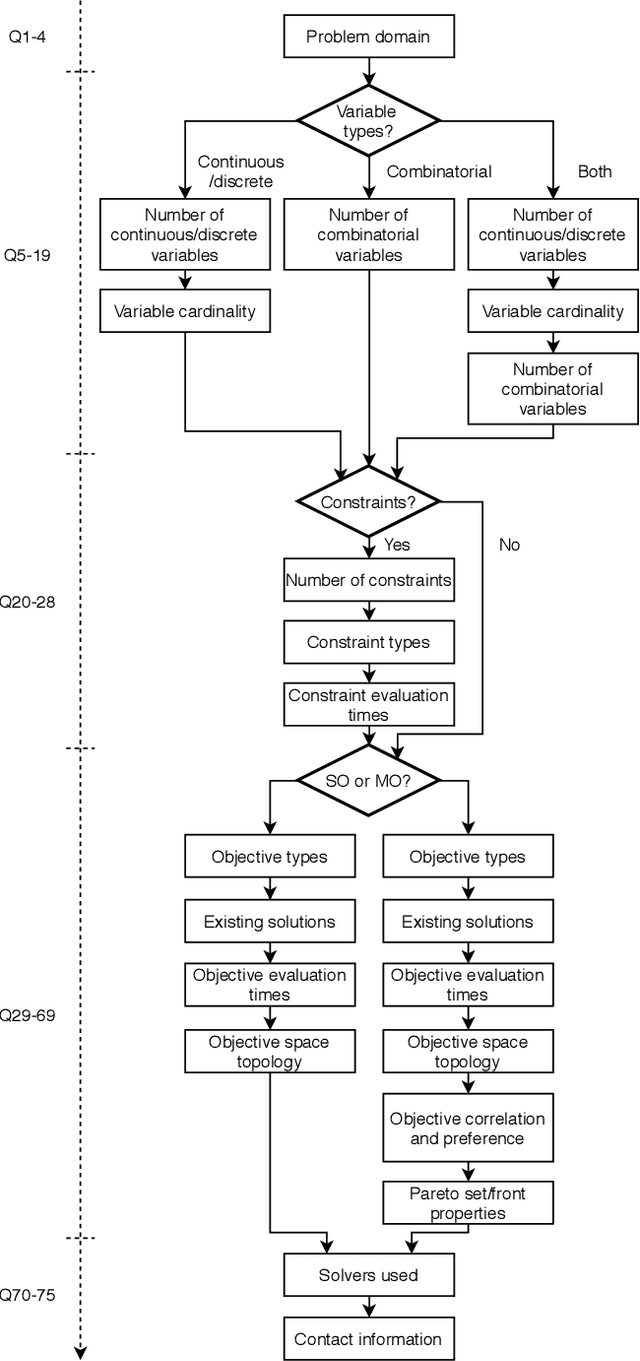
Benchmarks are a useful tool for empirical performance comparisons. However, one of the main shortcomings of existing benchmarks is that it remains largely unclear how they relate to real-world problems. What does an algorithm's performance on a benchmark say about its potential on a specific real-world problem? This work aims to identify properties of real-world problems through a questionnaire on real-world single-, multi-, and many-objective optimization problems. Based on initial responses, a few challenges that have to be considered in the design of realistic benchmarks can already be identified. A key point for future work is to gather more responses to the questionnaire to allow an analysis of common combinations of properties. In turn, such common combinations can then be included in improved benchmark suites. To gather more data, the reader is invited to participate in the questionnaire at: https://tinyurl.com/opt-survey