 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop Improvement: An Efficient Approach for Extracting Shared Features from Heterogeneous Data without Central Server
Mar 21, 2024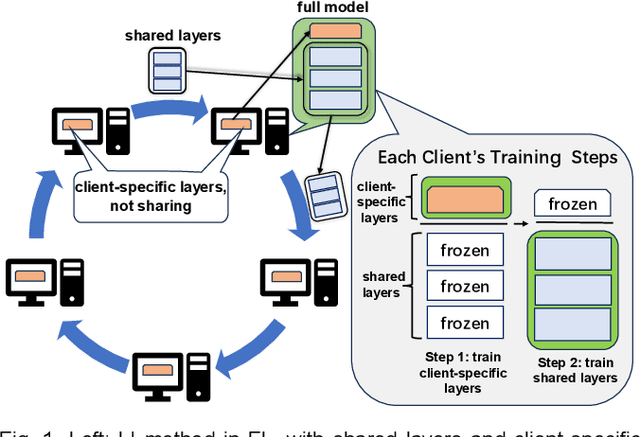
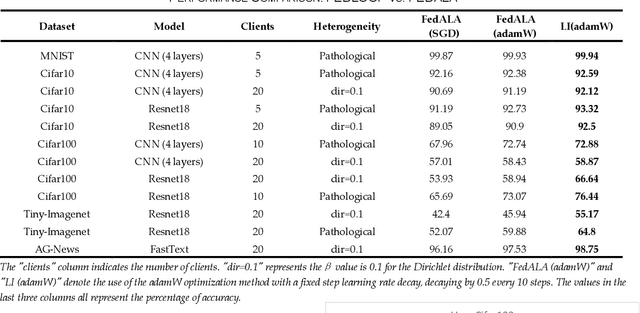
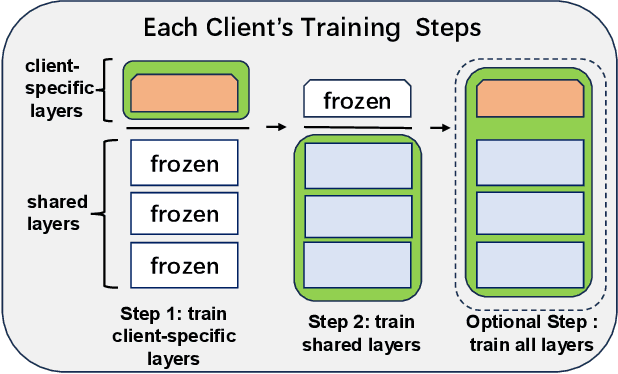
In federated learning, data heterogeneity significantly impacts performance. A typical solution involves segregating these parameters into shared and personalized components, a concept also relevant in multi-task learning. Addressing this, we propose "Loop Improvement" (LI), a novel method enhancing this separation and feature extraction without necessitating a central server or data interchange among participants. Our experiments reveal LI's superiority in several aspects: In personalized federated learning environments, LI consistently outperforms the advanced FedALA algorithm in accuracy across diverse scenarios. Additionally, LI's feature extractor closely matches the performance achieved when aggregating data from all clients. In global model contexts, employing LI with stacked personalized layers and an additional network also yields comparable results to combined client data scenarios. Furthermore, LI's adaptability extends to multi-task learning, streamlining the extraction of common features across tasks and obviating the need for simultaneous training. This approach not only enhances individual task performance but also achieves accuracy levels on par with classic multi-task learning methods where all tasks are trained simultaneously. LI integrates a loop topology with layer-wise and end-to-end training, compatible with various neural network models. This paper also delves into the theoretical underpinnings of LI's effectiveness, offering insights into its potential applications. The code is on https://github.com/axedge1983/LI
Privacy-preserving Continual Federated Clustering via Adaptive Resonance Theory
Sep 07, 2023


With the increasing importance of data privacy protection, various privacy-preserving machine learning methods have been proposed. In the clustering domain, various algorithms with a federated learning framework (i.e., federated clustering) have been actively studied and showed high clustering performance while preserving data privacy. However, most of the base clusterers (i.e., clustering algorithms) used in existing federated clustering algorithms need to specify the number of clusters in advance. These algorithms, therefore, are unable to deal with data whose distributions are unknown or continually changing. To tackle this problem, this paper proposes a privacy-preserving continual federated clustering algorithm. In the proposed algorithm, an adaptive resonance theory-based clustering algorithm capable of continual learning is used as a base clusterer. Therefore, the proposed algorithm inherits the ability of continual learning. Experimental results with synthetic and real-world datasets show that the proposed algorithm has superior clustering performance to state-of-the-art federated clustering algorithms while realizing data privacy protection and continual learning ability. The source code is available at \url{https://github.com/Masuyama-lab/FCAC}.
Explainable Lifelong Stream Learning Based on "Glocal" Pairwise Fusion
Jun 23, 2023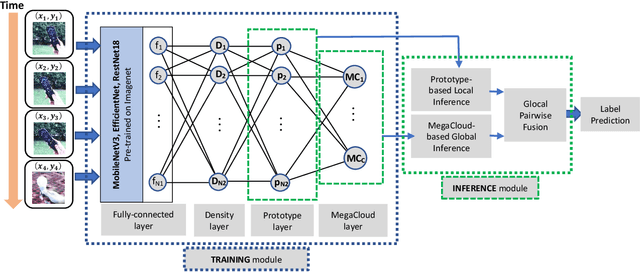
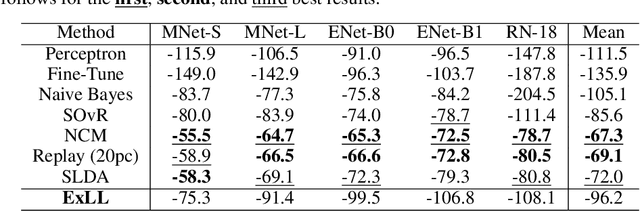
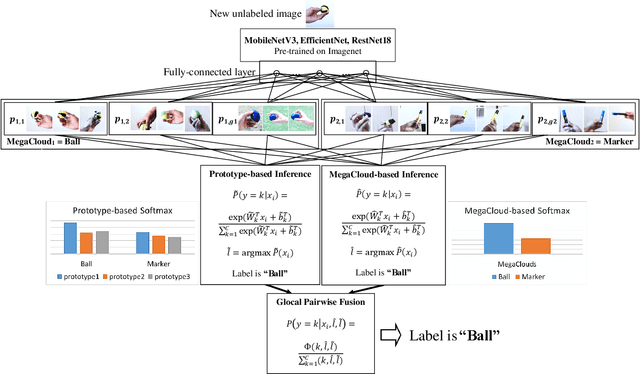
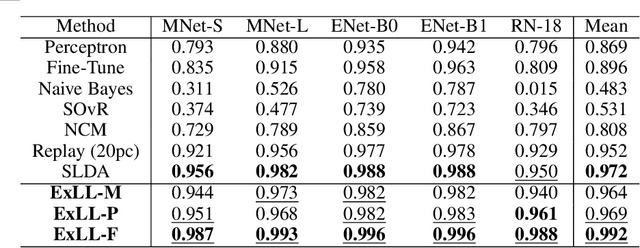
Real-time on-device continual learning applications are used on mobile phones, consumer robots, and smart appliances. Such devices have limited processing and memory storage capabilities, whereas continual learning acquires data over a long period of time. By necessity, lifelong learning algorithms have to be able to operate under such constraints while delivering good performance. This study presents the Explainable Lifelong Learning (ExLL) model, which incorporates several important traits: 1) learning to learn, in a single pass, from streaming data with scarce examples and resources; 2) a self-organizing prototype-based architecture that expands as needed and clusters streaming data into separable groups by similarity and preserves data against catastrophic forgetting; 3) an interpretable architecture to convert the clusters into explainable IF-THEN rules as well as to justify model predictions in terms of what is similar and dissimilar to the inference; and 4) inferences at the global and local level using a pairwise decision fusion process to enhance the accuracy of the inference, hence ``Glocal Pairwise Fusion.'' We compare ExLL against contemporary online learning algorithms for image recognition, using OpenLoris, F-SIOL-310, and Places datasets to evaluate several continual learning scenarios for video streams, low-sample learning, ability to scale, and imbalanced data streams. The algorithms are evaluated for their performance in accuracy, number of parameters, and experiment runtime requirements. ExLL outperforms all algorithms for accuracy in the majority of the tested scenarios.
A Parameter-free Adaptive Resonance Theory-based Topological Clustering Algorithm Capable of Continual Learning
May 03, 2023



In general, a similarity threshold (i.e., a vigilance parameter) for a node learning process in Adaptive Resonance Theory (ART)-based algorithms has a significant impact on clustering performance. In addition, an edge deletion threshold in a topological clustering algorithm plays an important role in adaptively generating well-separated clusters during a self-organizing process. In this paper, we propose a new parameter-free ART-based topological clustering algorithm capable of continual learning by introducing parameter estimation methods. Experimental results with synthetic and real-world datasets show that the proposed algorithm has superior clustering performance to the state-of-the-art clustering algorithms without any parameter pre-specifications.
Modeling Generalized Specialist Approach To Train Quality Resilient Snapshot Ensemble
Jun 12, 2022
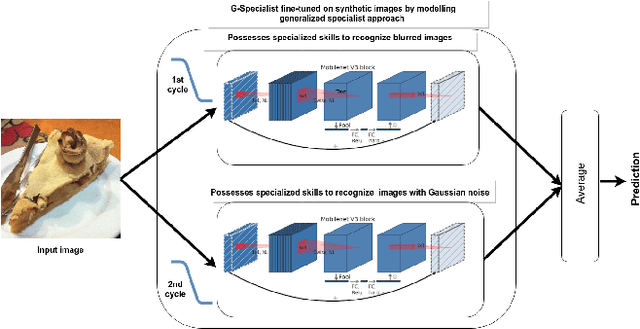


Convolutional neural networks (CNNs) apply well with food image recognition due to the ability to learn discriminative visual features. Nevertheless, recognizing distorted images is challenging for existing CNNs. Hence, the study modelled a generalized specialist approach to train a quality resilient ensemble. The approach aids the models in the ensemble framework retain general skills of recognizing clean images and shallow skills of classifying noisy images with one deep expertise area on a particular distortion. Subsequently, a novel data augmentation random quality mixup (RQMixUp) is combined with snapshot ensembling to train G-Specialist. During each training cycle of G-Specialist, a model is fine-tuned on the synthetic images generated by RQMixup, intermixing clean and distorted images of a particular distortion at a randomly chosen level. Resultantly, each snapshot in the ensemble gained expertise on several distortion levels, with shallow skills on other quality distortions. Next, the filter outputs from diverse experts were fused for higher accuracy. The learning process has no additional cost due to a single training process to train experts, compatible with a wide range of supervised CNNs for transfer learning. Finally, the experimental analysis on three real-world food and a Malaysian food database showed significant improvement for distorted images with competitive classification performance on pristine food images.
Lifelong Learning from Event-based Data
Nov 11, 2021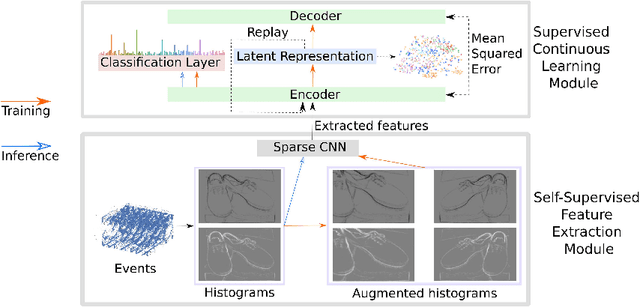

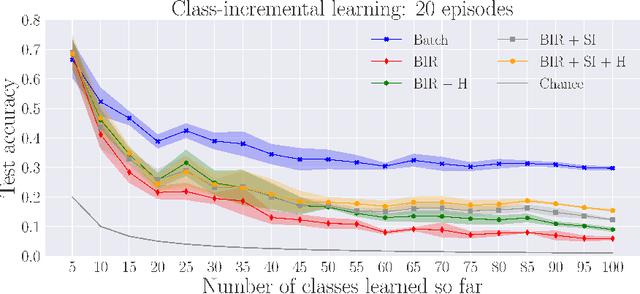
Lifelong learning is a long-standing aim for artificial agents that act in dynamic environments, in which an agent needs to accumulate knowledge incrementally without forgetting previously learned representations. We investigate methods for learning from data produced by event cameras and compare techniques to mitigate forgetting while learning incrementally. We propose a model that is composed of both, feature extraction and continuous learning. Furthermore, we introduce a habituation-based method to mitigate forgetting. Our experimental results show that the combination of different techniques can help to avoid catastrophic forgetting while learning incrementally from the features provided by the extraction module.
A Review of the Vision-based Approaches for Dietary Assessment
Jun 29, 2021
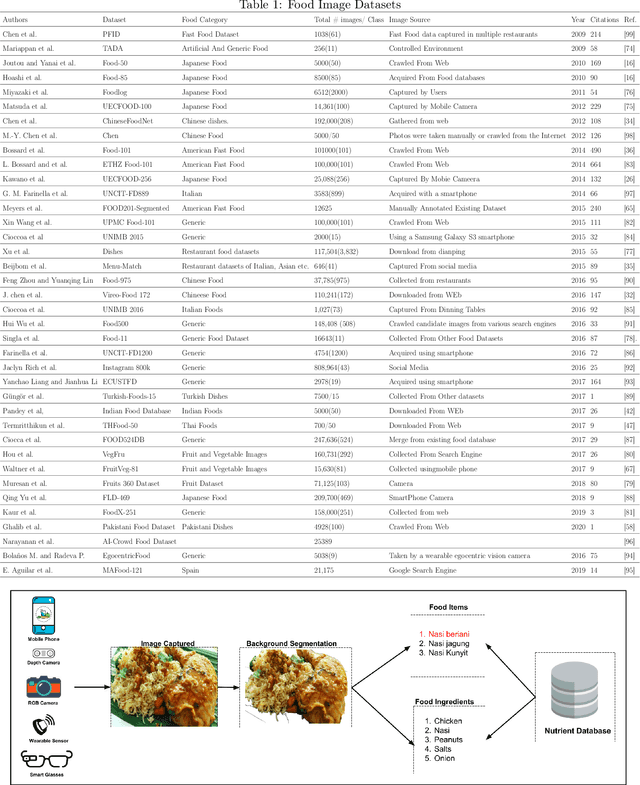
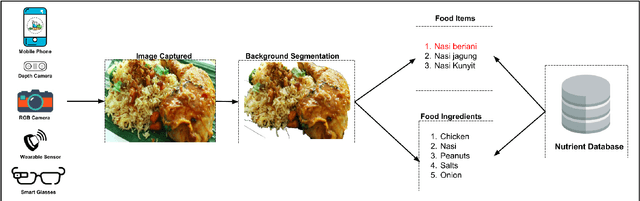
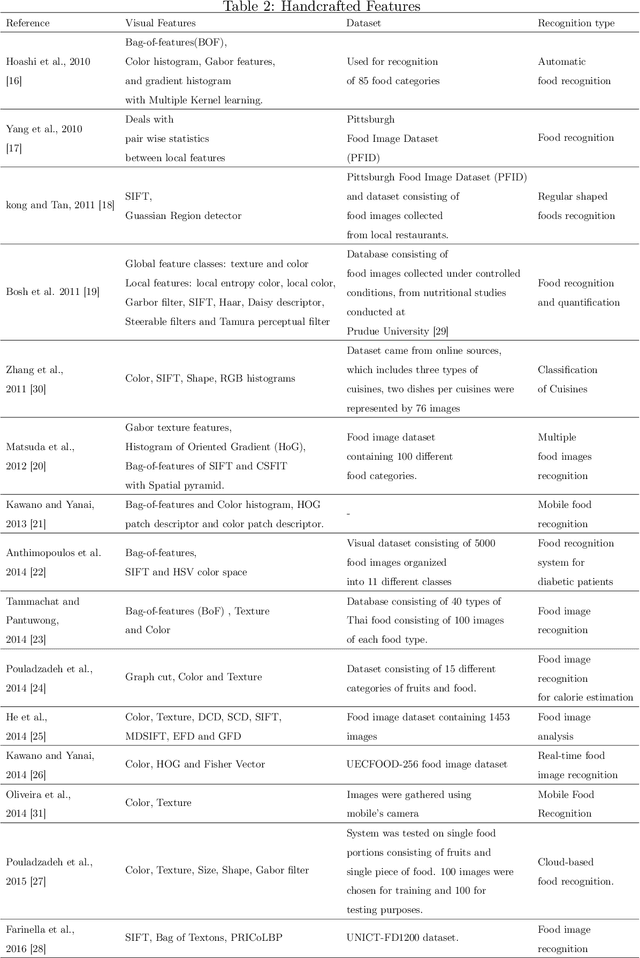
Last ten years have witnessed the growth of many computer vision applications for food recognition. Dietary studies showed that dietary-related problem such as obesity is associated with other chronic diseases like hypertension, irregular blood sugar levels, and increased risk of heart attacks. The primary cause of these problems is poor lifestyle choices and unhealthy dietary habits, which are manageable by using interactive mHealth apps that use automatic visual-based methods to assess dietary intake. This review discusses the most performing methodologies that have been developed so far for automatic food recognition. First, we will present the rationale of visual-based methods for food recognition. The core of the paper is the presentation, discussion and evaluation of these methods on popular food image databases. We also discussed the mobile applications that are implementing these methods. The review ends with a discussion of research gaps and future challenges in this area.
Multi-label Classification via Adaptive Resonance Theory-based Clustering
Mar 03, 2021

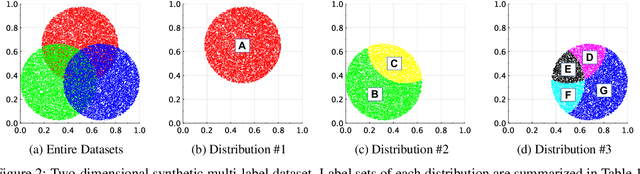
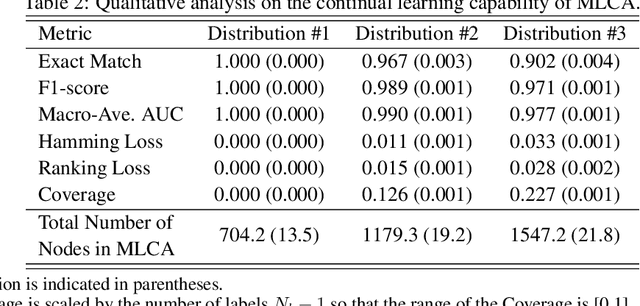
This paper proposes a multi-label classification algorithm capable of continual learning by applying an Adaptive Resonance Theory (ART)-based clustering algorithm and the Bayesian approach for label probability computation. The ART-based clustering algorithm adaptively and continually generates prototype nodes corresponding to given data, and the generated nodes are used as classifiers. The label probability computation independently counts the number of label appearances for each class and calculates the Bayesian probabilities. Thus, the label probability computation can cope with an increase in the number of labels. Experimental results with synthetic and real-world multi-label datasets show that the proposed algorithm has competitive classification performance to other well-known algorithms while realizing continual learning.
Explainable Goal-Driven Agents and Robots- A Comprehensive Review and New Framework
Apr 21, 2020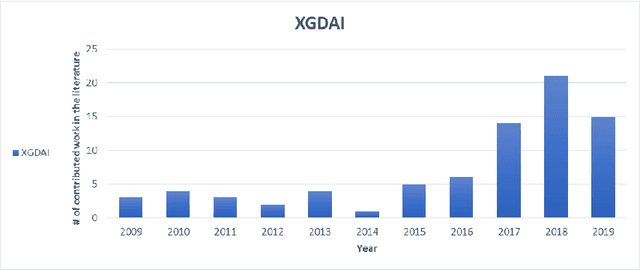
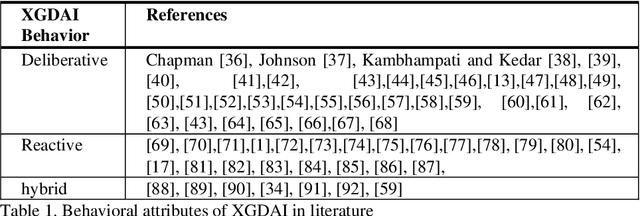
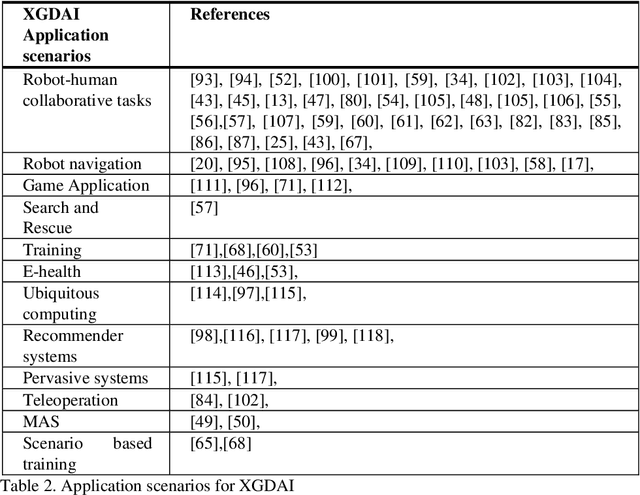
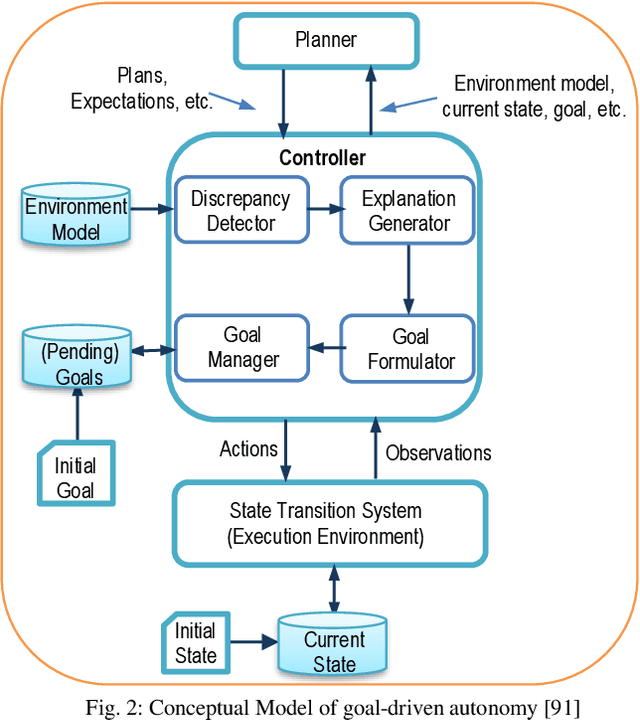
Recent applications of autonomous agents and robots, for example, self-driving cars, scenario-based trainers, exploration robots, service robots, have brought attention to crucial trust-related problems associated with the current generation of artificial intelligence (AI) systems. AI systems particularly dominated by the connectionist deep learning neural network approach lack capabilities of explaining their decisions and actions to others, despite their great successes. They are fundamentally non-intuitive black boxes, which renders their decision or actions opaque, making it difficult to trust them in safety-critical applications. The recent stance on the explainability of AI systems has witnessed several works on eXplainable Artificial Intelligence; however, most of the studies have focused on data-driven XAI systems applied in computational sciences. Studies addressing the increasingly pervasive goal-driven agents and robots are still missing. This paper reviews works on explainable goal-driven intelligent agents and robots, focusing on techniques for explaining and communicating agents perceptual functions (for example, senses, vision, etc.) and cognitive reasoning (for example, beliefs, desires, intention, plans, and goals) with humans in the loop. The review highlights key strategies that emphasize transparency and understandability, and continual learning for explainability. Finally, the paper presents requirements for explainability and suggests a roadmap for the possible realization of effective goal-driven explainable agents and robots
Bio-Inspired Human Action Recognition using Hybrid Max-Product Neuro-Fuzzy Classifier and Quantum-Behaved PSO
Feb 21, 2016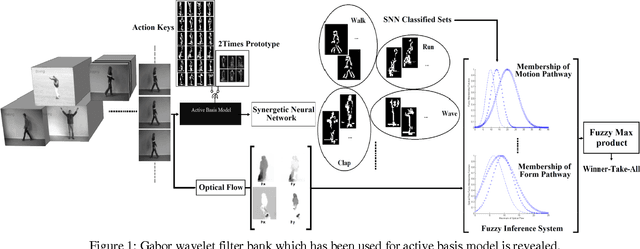
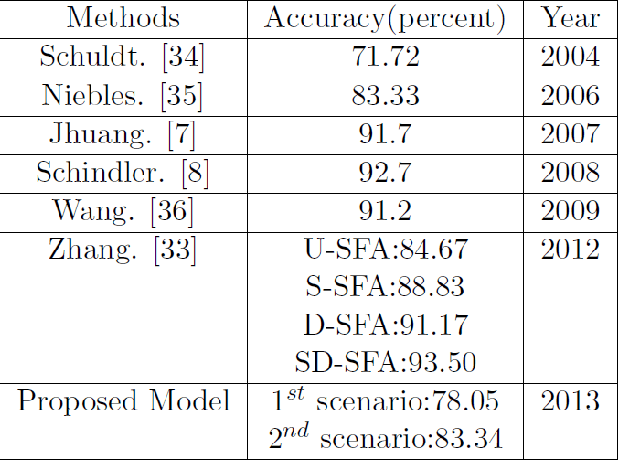

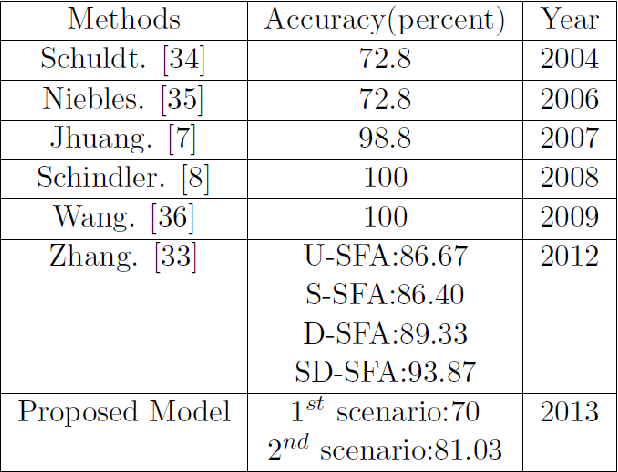
Studies on computational neuroscience through functional magnetic resonance imaging (fMRI) and following biological inspired system stated that human action recognition in the brain of mammalian leads two distinct pathways in the model, which are specialized for analysis of motion (optic flow) and form information. Principally, we have defined a novel and robust form features applying active basis model as form extractor in form pathway in the biological inspired model. An unbalanced synergetic neural net-work classifies shapes and structures of human objects along with tuning its attention parameter by quantum particle swarm optimization (QPSO) via initiation of Centroidal Voronoi Tessellations. These tools utilized and justified as strong tools for following biological system model in form pathway. But the final decision has done by combination of ultimate outcomes of both pathways via fuzzy inference which increases novality of proposed model. Combination of these two brain pathways is done by considering each feature sets in Gaussian membership functions with fuzzy product inference method. Two configurations have been proposed for form pathway: applying multi-prototype human action templates using two time synergetic neural network for obtaining uniform template regarding each actions, and second scenario that it uses abstracting human action in four key-frames. Experimental results showed promising accuracy performance on different datasets (KTH and Weizmann).