 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop Improvement: An Efficient Approach for Extracting Shared Features from Heterogeneous Data without Central Server
Mar 21, 2024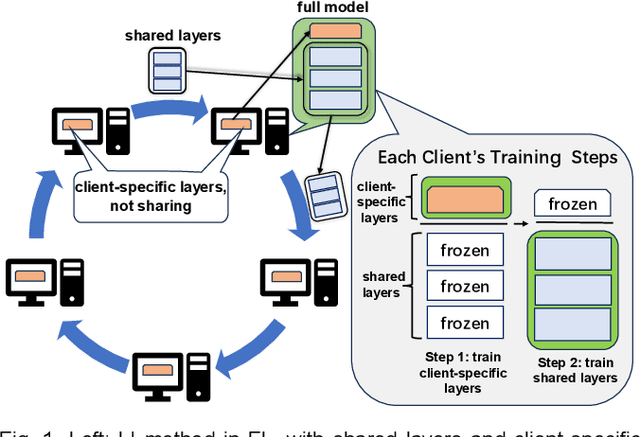
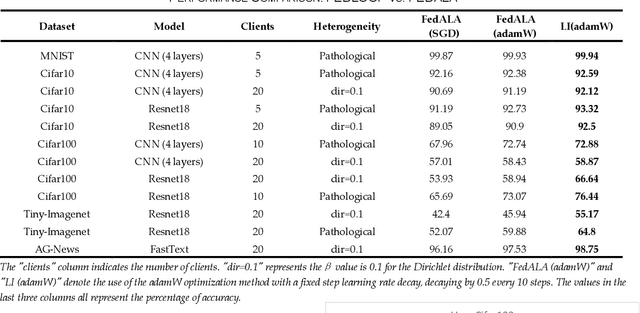
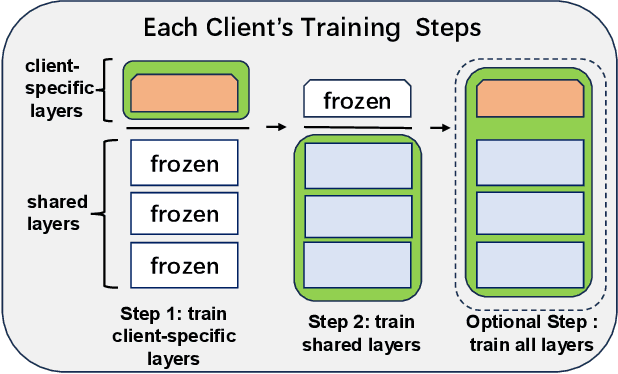
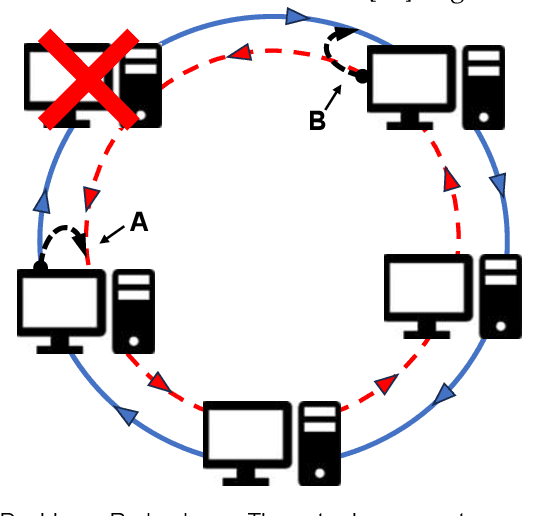
In federated learning, data heterogeneity significantly impacts performance. A typical solution involves segregating these parameters into shared and personalized components, a concept also relevant in multi-task learning. Addressing this, we propose "Loop Improvement" (LI), a novel method enhancing this separation and feature extraction without necessitating a central server or data interchange among participants. Our experiments reveal LI's superiority in several aspects: In personalized federated learning environments, LI consistently outperforms the advanced FedALA algorithm in accuracy across diverse scenarios. Additionally, LI's feature extractor closely matches the performance achieved when aggregating data from all clients. In global model contexts, employing LI with stacked personalized layers and an additional network also yields comparable results to combined client data scenarios. Furthermore, LI's adaptability extends to multi-task learning, streamlining the extraction of common features across tasks and obviating the need for simultaneous training. This approach not only enhances individual task performance but also achieves accuracy levels on par with classic multi-task learning methods where all tasks are trained simultaneously. LI integrates a loop topology with layer-wise and end-to-end training, compatible with various neural network models. This paper also delves into the theoretical underpinnings of LI's effectiveness, offering insights into its potential applications. The code is on https://github.com/axedge1983/LI
Explainable Lifelong Stream Learning Based on "Glocal" Pairwise Fusion
Jun 23, 2023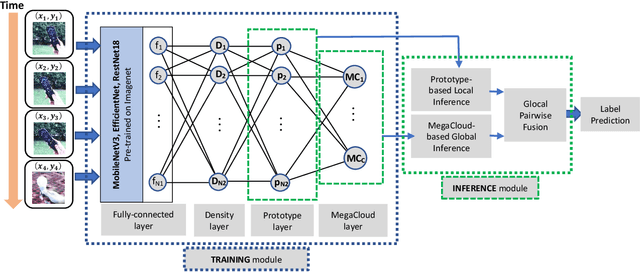
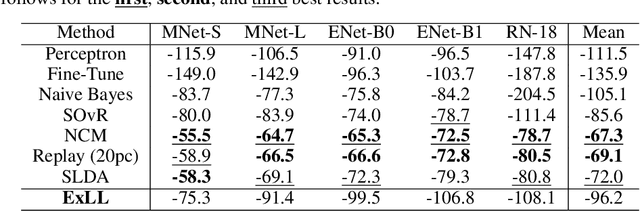
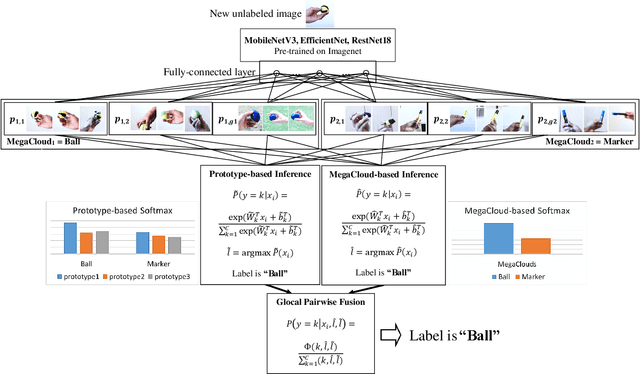
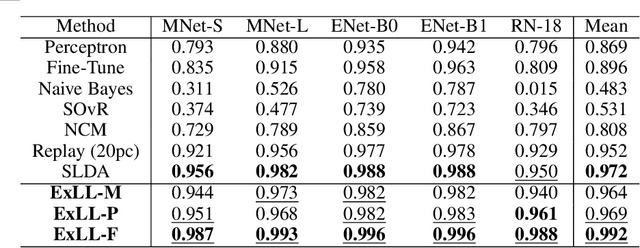
Real-time on-device continual learning applications are used on mobile phones, consumer robots, and smart appliances. Such devices have limited processing and memory storage capabilities, whereas continual learning acquires data over a long period of time. By necessity, lifelong learning algorithms have to be able to operate under such constraints while delivering good performance. This study presents the Explainable Lifelong Learning (ExLL) model, which incorporates several important traits: 1) learning to learn, in a single pass, from streaming data with scarce examples and resources; 2) a self-organizing prototype-based architecture that expands as needed and clusters streaming data into separable groups by similarity and preserves data against catastrophic forgetting; 3) an interpretable architecture to convert the clusters into explainable IF-THEN rules as well as to justify model predictions in terms of what is similar and dissimilar to the inference; and 4) inferences at the global and local level using a pairwise decision fusion process to enhance the accuracy of the inference, hence ``Glocal Pairwise Fusion.'' We compare ExLL against contemporary online learning algorithms for image recognition, using OpenLoris, F-SIOL-310, and Places datasets to evaluate several continual learning scenarios for video streams, low-sample learning, ability to scale, and imbalanced data streams. The algorithms are evaluated for their performance in accuracy, number of parameters, and experiment runtime requirements. ExLL outperforms all algorithms for accuracy in the majority of the tested scenarios.