 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateVLM: A State-Aware Vision-Language Model for Robotic Affordance Reasoning
May 05, 2026Vision-language models (VLMs) have shown remarkable performance in various robotic tasks, as they can perceive visual information and understand natural language instructions. However, when applied to robotics, VLMs remain subject to a fundamental limitation inherent in large language models (LLMs): they struggle with numerical reasoning, particularly in object detection and object-state localization. To explore numerical reasoning as a regression task in VLMs, we propose a novel training strategy to adapt VLMs for object detection and object-state localization. This approach leverages box decoder outputs to compute an Auxiliary Regression Loss (ARL) during fine-tuning, while preserving standard sequence prediction at inference. We leverage this training strategy to develop StateVLM (State-aware Vision-Language Model), a novel model designed to perceive and learn fine-grained object representations, including precise localization of objects and their states, as well as graspable regions. Due to the lack of a benchmark for object-state affordance reasoning, we introduce an open-source benchmark, Object State Affordance Reasoning (OSAR), which contains 1,172 scenes with 7,746 individual objects and corresponding bounding boxes. Comparative experiments on adapted benchmarks (RefCOCO, RefCOCO+, and \mbox{RefCOCOg}) demonstrate that ARL improves model performance by an average of 1.6\% compared to models without ARL. Experiments on the OSAR benchmark further support this finding, showing that StateVLM with ARL achieves an average of 5.2\% higher performance than models without ARL. In particular, ARL is also important for the complex task of affordance reasoning in OSAR, where it enhances the consistency of model outputs.
Theory of Mind for Explainable Human-Robot Interaction
Dec 31, 2025Within the context of human-robot interaction (HRI), Theory of Mind (ToM) is intended to serve as a user-friendly backend to the interface of robotic systems, enabling robots to infer and respond to human mental states. When integrated into robots, ToM allows them to adapt their internal models to users' behaviors, enhancing the interpretability and predictability of their actions. Similarly, Explainable Artificial Intelligence (XAI) aims to make AI systems transparent and interpretable, allowing humans to understand and interact with them effectively. Since ToM in HRI serves related purposes, we propose to consider ToM as a form of XAI and evaluate it through the eValuation XAI (VXAI) framework and its seven desiderata. This paper identifies a critical gap in the application of ToM within HRI, as existing methods rarely assess the extent to which explanations correspond to the robot's actual internal reasoning. To address this limitation, we propose to integrate ToM within XAI frameworks. By embedding ToM principles inside XAI, we argue for a shift in perspective, as current XAI research focuses predominantly on the AI system itself and often lacks user-centered explanations. Incorporating ToM would enable a change in focus, prioritizing the user's informational needs and perspective.
Talking to Robots: A Practical Examination of Speech Foundation Models for HRI Applications
Aug 25, 2025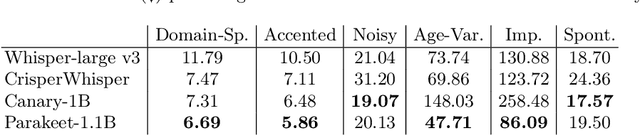
Automatic Speech Recognition (ASR) systems in real-world settings need to handle imperfect audio, often degraded by hardware limitations or environmental noise, while accommodating diverse user groups. In human-robot interaction (HRI), these challenges intersect to create a uniquely challenging recognition environment. We evaluate four state-of-the-art ASR systems on eight publicly available datasets that capture six dimensions of difficulty: domain-specific, accented, noisy, age-variant, impaired, and spontaneous speech. Our analysis demonstrates significant variations in performance, hallucination tendencies, and inherent biases, despite similar scores on standard benchmarks. These limitations have serious implications for HRI, where recognition errors can interfere with task performance, user trust, and safety.
Towards Bio-Inspired Robotic Trajectory Planning via Self-Supervised RNN
Jul 02, 2025Trajectory planning in robotics is understood as generating a sequence of joint configurations that will lead a robotic agent, or its manipulator, from an initial state to the desired final state, thus completing a manipulation task while considering constraints like robot kinematics and the environment. Typically, this is achieved via sampling-based planners, which are computationally intensive. Recent advances demonstrate that trajectory planning can also be performed by supervised sequence learning of trajectories, often requiring only a single or fixed number of passes through a neural architecture, thus ensuring a bounded computation time. Such fully supervised approaches, however, perform imitation learning; they do not learn based on whether the trajectories can successfully reach a goal, but try to reproduce observed trajectories. In our work, we build on this approach and propose a cognitively inspired self-supervised learning scheme based on a recurrent architecture for building a trajectory model. We evaluate the feasibility of the proposed method on a task of kinematic planning for a robotic arm. The results suggest that the model is able to learn to generate trajectories only using given paired forward and inverse kinematics models, and indicate that this novel method could facilitate planning for more complex manipulation tasks requiring adaptive solutions.
Shaken, Not Stirred: A Novel Dataset for Visual Understanding of Glasses in Human-Robot Bartending Tasks
Mar 06, 2025



Datasets for object detection often do not account for enough variety of glasses, due to their transparent and reflective properties. Specifically, open-vocabulary object detectors, widely used in embodied robotic agents, fail to distinguish subclasses of glasses. This scientific gap poses an issue to robotic applications that suffer from accumulating errors between detection, planning, and action execution. The paper introduces a novel method for the acquisition of real-world data from RGB-D sensors that minimizes human effort. We propose an auto-labeling pipeline that generates labels for all the acquired frames based on the depth measurements. We provide a novel real-world glass object dataset that was collected on the Neuro-Inspired COLlaborator (NICOL), a humanoid robot platform. The data set consists of 7850 images recorded from five different cameras. We show that our trained baseline model outperforms state-of-the-art open-vocabulary approaches. In addition, we deploy our baseline model in an embodied agent approach to the NICOL platform, on which it achieves a success rate of 81% in a human-robot bartending scenario.
DIRIGENt: End-To-End Robotic Imitation of Human Demonstrations Based on a Diffusion Model
Jan 28, 2025There has been substantial progress in humanoid robots, with new skills continuously being taught, ranging from navigation to manipulation. While these abilities may seem impressive, the teaching methods often remain inefficient. To enhance the process of teaching robots, we propose leveraging a mechanism effectively used by humans: teaching by demonstrating. In this paper, we introduce DIRIGENt (DIrect Robotic Imitation GENeration model), a novel end-to-end diffusion approach that directly generates joint values from observing human demonstrations, enabling a robot to imitate these actions without any existing mapping between it and humans. We create a dataset in which humans imitate a robot and then use this collected data to train a diffusion model that enables a robot to imitate humans. The following three aspects are the core of our contribution. First is our novel dataset with natural pairs between human and robot poses, allowing our approach to imitate humans accurately despite the gap between their anatomies. Second, the diffusion input to our model alleviates the challenge of redundant joint configurations, limiting the search space. And finally, our end-to-end architecture from perception to action leads to an improved learning capability. Through our experimental analysis, we show that combining these three aspects allows DIRIGENt to outperform existing state-of-the-art approaches in the field of generating joint values from RGB images.
Learning Low-Level Causal Relations using a Simulated Robotic Arm
Oct 10, 2024Causal learning allows humans to predict the effect of their actions on the known environment and use this knowledge to plan the execution of more complex actions. Such knowledge also captures the behaviour of the environment and can be used for its analysis and the reasoning behind the behaviour. This type of knowledge is also crucial in the design of intelligent robotic systems with common sense. In this paper, we study causal relations by learning the forward and inverse models based on data generated by a simulated robotic arm involved in two sensorimotor tasks. As a next step, we investigate feature attribution methods for the analysis of the forward model, which reveals the low-level causal effects corresponding to individual features of the state vector related to both the arm joints and the environment features. This type of analysis provides solid ground for dimensionality reduction of the state representations, as well as for the aggregation of knowledge towards the explainability of causal effects at higher levels.
* 14 pages, 5 figures, 3 tables. Appeared in 2024 International Conference on Artificial Neural Networks (ICANN) proceedings. Published version copyrighted by Springer. This work was funded by the Horizon Europe Twinning project TERAIS, G.A. number 101079338 and in part by the Slovak Grant Agency for Science (VEGA), project 1/0373/23
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Jun 14, 2024

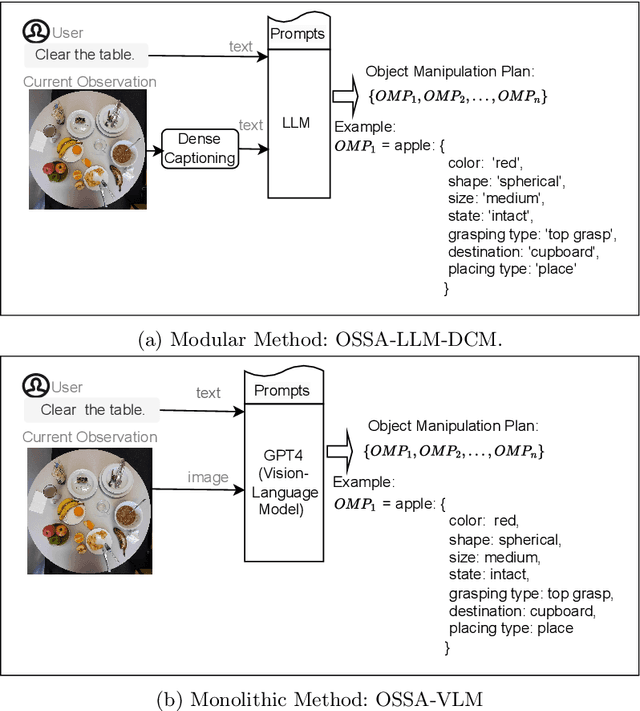
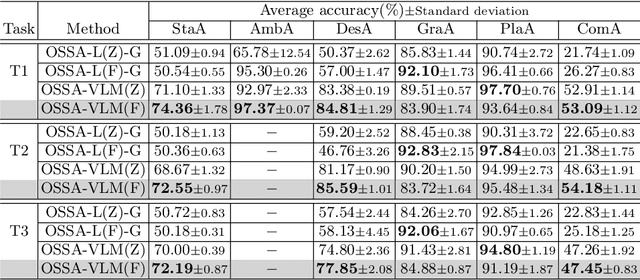
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}
Diffusing in Someone Else's Shoes: Robotic Perspective Taking with Diffusion
Apr 11, 2024Humanoid robots can benefit from their similarity to the human shape by learning from humans. When humans teach other humans how to perform actions, they often demonstrate the actions and the learning human can try to imitate the demonstration. Being able to mentally transfer from a demonstration seen from a third-person perspective to how it should look from a first-person perspective is fundamental for this ability in humans. As this is a challenging task, it is often simplified for robots by creating a demonstration in the first-person perspective. Creating these demonstrations requires more effort but allows for an easier imitation. We introduce a novel diffusion model aimed at enabling the robot to directly learn from the third-person demonstrations. Our model is capable of learning and generating the first-person perspective from the third-person perspective by translating the size and rotations of objects and the environment between two perspectives. This allows us to utilise the benefits of easy-to-produce third-person demonstrations and easy-to-imitate first-person demonstrations. The model can either represent the first-person perspective in an RGB image or calculate the joint values. Our approach significantly outperforms other image-to-image models in this task.
Robotic Imitation of Human Actions
Jan 16, 2024Imitation can allow us to quickly gain an understanding of a new task. Through a demonstration, we can gain direct knowledge about which actions need to be performed and which goals they have. In this paper, we introduce a new approach to imitation learning that tackles the challenges of a robot imitating a human, such as the change in perspective and body schema. Our approach can use a single human demonstration to abstract information about the demonstrated task, and use that information to generalise and replicate it. We facilitate this ability by a new integration of two state-of-the-art methods: a diffusion action segmentation model to abstract temporal information from the demonstration and an open vocabulary object detector for spatial information. Furthermore, we refine the abstracted information and use symbolic reasoning to create an action plan utilising inverse kinematics, to allow the robot to imitate the demonstrated action.