 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
A Framework for Adapting Human-Robot Interaction to Diverse User Groups
Oct 15, 2024



To facilitate natural and intuitive interactions with diverse user groups in real-world settings, social robots must be capable of addressing the varying requirements and expectations of these groups while adapting their behavior based on user feedback. While previous research often focuses on specific demographics, we present a novel framework for adaptive Human-Robot Interaction (HRI) that tailors interactions to different user groups and enables individual users to modulate interactions through both minor and major interruptions. Our primary contributions include the development of an adaptive, ROS-based HRI framework with an open-source code base. This framework supports natural interactions through advanced speech recognition and voice activity detection, and leverages a large language model (LLM) as a dialogue bridge. We validate the efficiency of our framework through module tests and system trials, demonstrating its high accuracy in age recognition and its robustness to repeated user inputs and plan changes.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Jun 14, 2024

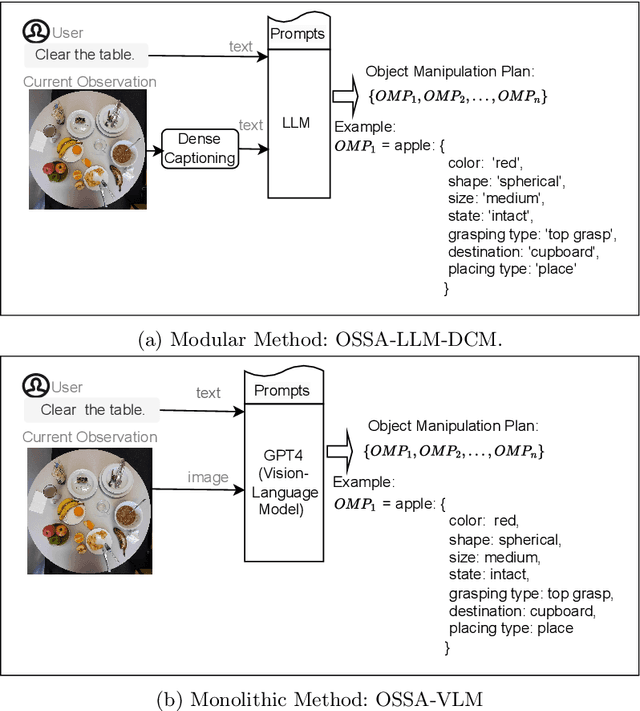
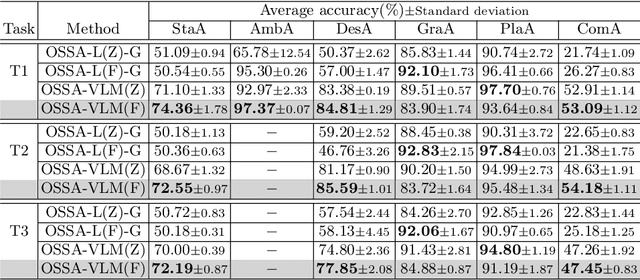
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.