 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetails Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Paper and Code


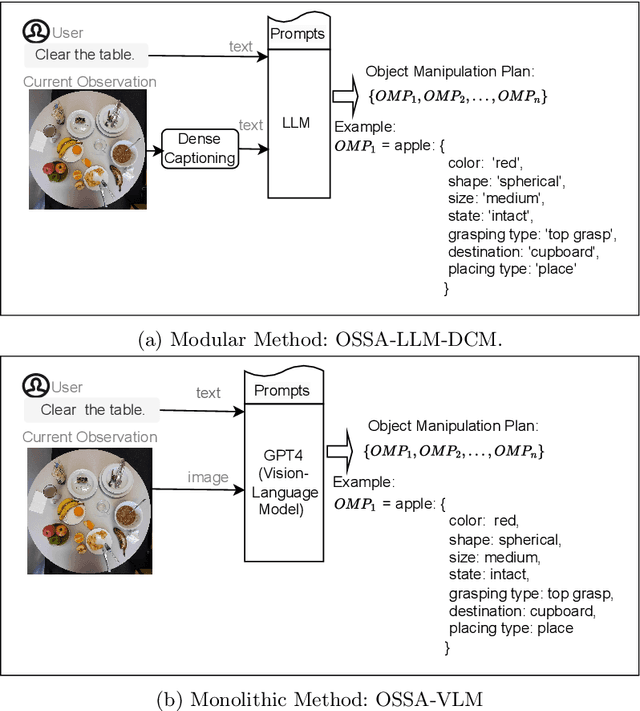
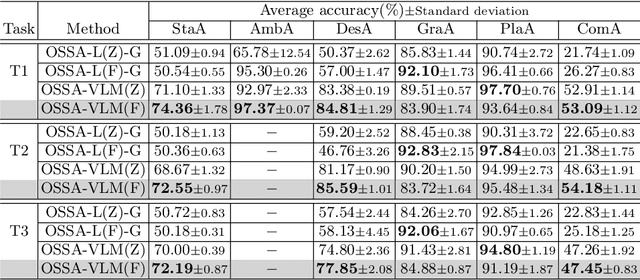
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}