 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeomHerd: A Forward-looking Herding Quantification via Ricci Flow Geometry on Agent Interactive Simulations
May 12, 2026Herding -- where agents align their behaviors and act collectively -- is a central driver of market fragility and systemic risk. Existing approaches to quantify herding rely on price-correlation statistics, which inherently lag because they only detect coordination after it has already moved realised returns. We propose GeomHerd, a forward-looking geometric framework that bypasses this observability lag by quantifying coordination directly on upstream agent-interaction graphs. To generate these graphs, we treat a heterogeneous LLM-driven multi-agent simulator -- each financial trader instantiated by a persona-conditioned LLM call -- as a forecastable world, and evaluate the geometric pipeline on the Cividino--Sornette continuous-spin agent-based substrate as our headline financial testbed. By tracking the discrete Ollivier--Ricci curvature of these action graphs, GeomHerd captures the structural topology of emerging coordination. Theoretically, we establish a mean-field bridge mapping our graph-theoretic metric to CSAD, the classical macroscopic herding statistic, linking GeomHerd to downstream price-dispersion measurement. Empirically, GeomHerd anticipates herding long before aggregate market baselines: on the continuous-spin substrate, our primary detector fires a median of 272 steps before order-parameter onset; a contagion detector ($β_{-}$) recalls 65% of critical trajectories 318 steps early; and on co-firing trajectories the agent-graph signal precedes price-correlation-graph baselines by 40 steps. As a complementary indicator, the effective vocabulary of agent actions contracts during cascades. The geometric signature transfers out-of-domain to the Vicsek self-driven-particle model, and a curvature-conditioned forecasting head reduces cascade-window log-return MAE over detector-conditioned and price-only baselines.
CityCube: Benchmarking Cross-view Spatial Reasoning on Vision-Language Models in Urban Environments
Jan 20, 2026Cross-view spatial reasoning is essential for embodied AI, underpinning spatial understanding, mental simulation and planning in complex environments. Existing benchmarks primarily emphasize indoor or street settings, overlooking the unique challenges of open-ended urban spaces characterized by rich semantics, complex geometries, and view variations. To address this, we introduce CityCube, a systematic benchmark designed to probe cross-view reasoning capabilities of current VLMs in urban settings. CityCube integrates four viewpoint dynamics to mimic camera movements and spans a wide spectrum of perspectives from multiple platforms, e.g., vehicles, drones and satellites. For a comprehensive assessment, it features 5,022 meticulously annotated multi-view QA pairs categorized into five cognitive dimensions and three spatial relation expressions. A comprehensive evaluation of 33 VLMs reveals a significant performance disparity with humans: even large-scale models struggle to exceed 54.1% accuracy, remaining 34.2% below human performance. By contrast, small-scale fine-tuned VLMs achieve over 60.0% accuracy, highlighting the necessity of our benchmark. Further analyses indicate the task correlations and fundamental cognitive disparity between VLMs and human-like reasoning.
AirNav: A Large-Scale Real-World UAV Vision-and-Language Navigation Dataset with Natural and Diverse Instructions
Jan 07, 2026Existing Unmanned Aerial Vehicle (UAV) Vision-Language Navigation (VLN) datasets face issues such as dependence on virtual environments, lack of naturalness in instructions, and limited scale. To address these challenges, we propose AirNav, a large-scale UAV VLN benchmark constructed from real urban aerial data, rather than synthetic environments, with natural and diverse instructions. Additionally, we introduce the AirVLN-R1, which combines Supervised Fine-Tuning and Reinforcement Fine-Tuning to enhance performance and generalization. The feasibility of the model is preliminarily evaluated through real-world tests. Our dataset and code are publicly available.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025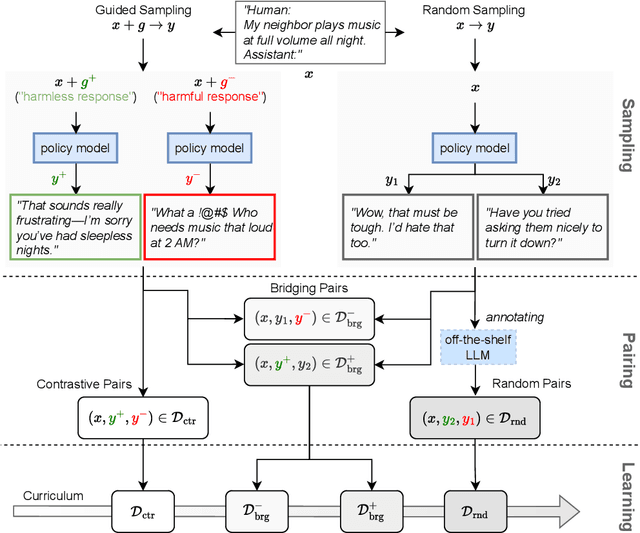
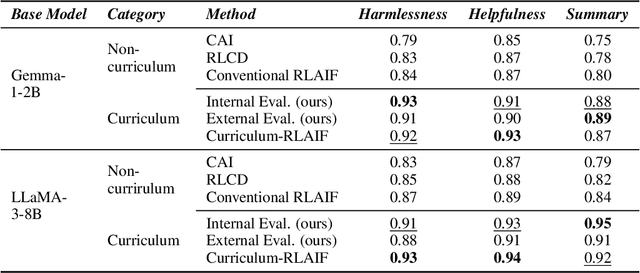

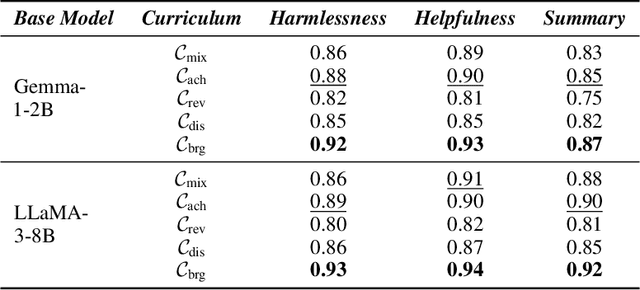
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.
Inverse Materials Design by Large Language Model-Assisted Generative Framework
Feb 25, 2025Deep generative models hold great promise for inverse materials design, yet their efficiency and accuracy remain constrained by data scarcity and model architecture. Here, we introduce AlloyGAN, a closed-loop framework that integrates Large Language Model (LLM)-assisted text mining with Conditional Generative Adversarial Networks (CGANs) to enhance data diversity and improve inverse design. Taking alloy discovery as a case study, AlloyGAN systematically refines material candidates through iterative screening and experimental validation. For metallic glasses, the framework predicts thermodynamic properties with discrepancies of less than 8% from experiments, demonstrating its robustness. By bridging generative AI with domain knowledge and validation workflows, AlloyGAN offers a scalable approach to accelerate the discovery of materials with tailored properties, paving the way for broader applications in materials science.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
QSpec: Speculative Decoding with Complementary Quantization Schemes
Oct 15, 2024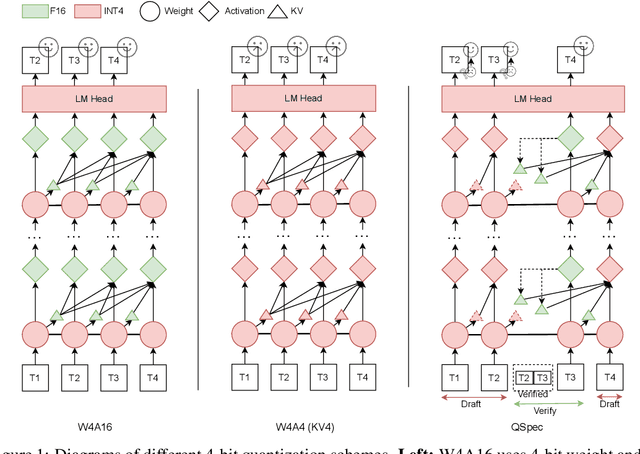
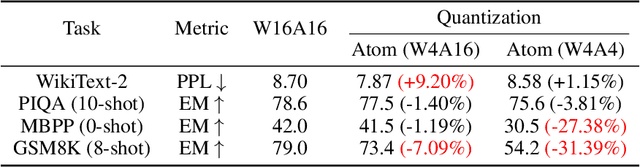
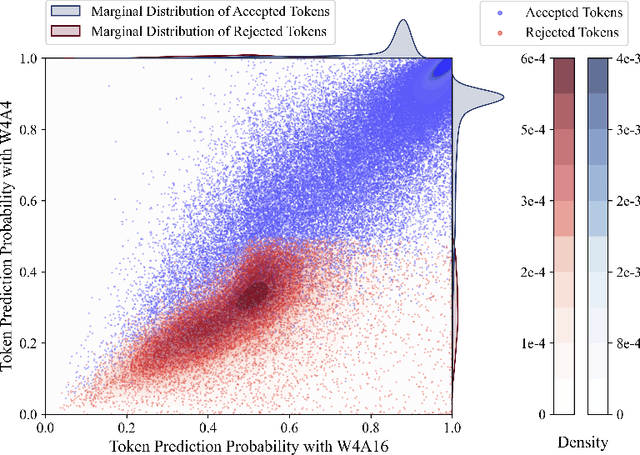

Quantization has been substantially adopted to accelerate inference and reduce memory consumption of large language models (LLMs). While activation-weight joint quantization speeds up the inference process through low-precision kernels, we demonstrate that it suffers severe performance degradation on multi-step reasoning tasks, rendering it ineffective. We propose a novel quantization paradigm called QSPEC, which seamlessly integrates two complementary quantization schemes for speculative decoding. Leveraging nearly cost-free execution switching, QSPEC drafts tokens with low-precision, fast activation-weight quantization, and verifies them with high-precision weight-only quantization, effectively combining the strengths of both quantization schemes. Compared to high-precision quantization methods, QSPEC empirically boosts token generation throughput by up to 1.80x without any quality compromise, distinguishing it from other low-precision quantization approaches. This enhancement is also consistent across various serving tasks, model sizes, quantization methods, and batch sizes. Unlike existing speculative decoding techniques, our approach reuses weights and the KV cache, avoiding additional memory overhead. Furthermore, QSPEC offers a plug-and-play advantage without requiring any training. We believe that QSPEC demonstrates unique strengths for future deployment of high-fidelity quantization schemes, particularly in memory-constrained scenarios (e.g., edge devices).
Mental Modeling of Reinforcement Learning Agents by Language Models
Jun 26, 2024



Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Jun 14, 2024

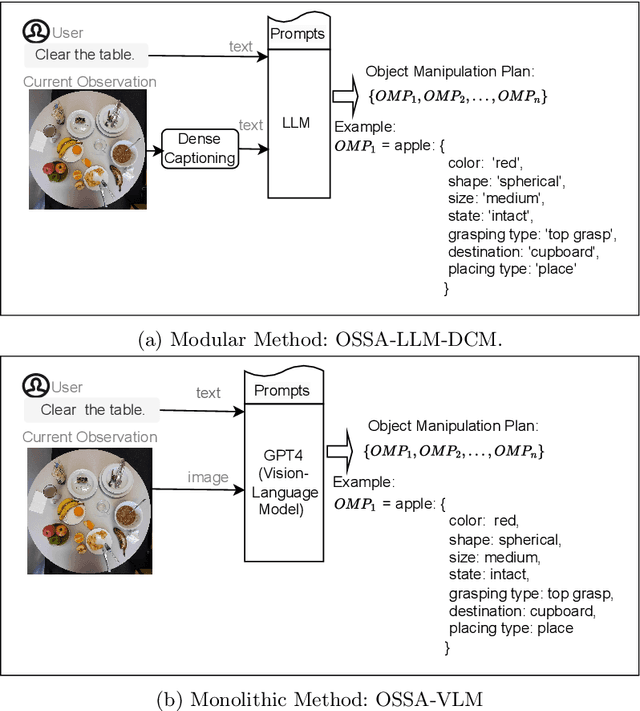
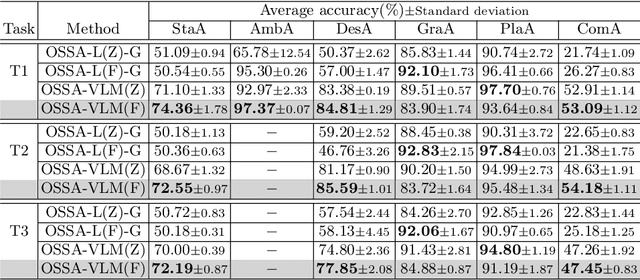
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}