 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateVLM: A State-Aware Vision-Language Model for Robotic Affordance Reasoning
May 05, 2026Vision-language models (VLMs) have shown remarkable performance in various robotic tasks, as they can perceive visual information and understand natural language instructions. However, when applied to robotics, VLMs remain subject to a fundamental limitation inherent in large language models (LLMs): they struggle with numerical reasoning, particularly in object detection and object-state localization. To explore numerical reasoning as a regression task in VLMs, we propose a novel training strategy to adapt VLMs for object detection and object-state localization. This approach leverages box decoder outputs to compute an Auxiliary Regression Loss (ARL) during fine-tuning, while preserving standard sequence prediction at inference. We leverage this training strategy to develop StateVLM (State-aware Vision-Language Model), a novel model designed to perceive and learn fine-grained object representations, including precise localization of objects and their states, as well as graspable regions. Due to the lack of a benchmark for object-state affordance reasoning, we introduce an open-source benchmark, Object State Affordance Reasoning (OSAR), which contains 1,172 scenes with 7,746 individual objects and corresponding bounding boxes. Comparative experiments on adapted benchmarks (RefCOCO, RefCOCO+, and \mbox{RefCOCOg}) demonstrate that ARL improves model performance by an average of 1.6\% compared to models without ARL. Experiments on the OSAR benchmark further support this finding, showing that StateVLM with ARL achieves an average of 5.2\% higher performance than models without ARL. In particular, ARL is also important for the complex task of affordance reasoning in OSAR, where it enhances the consistency of model outputs.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025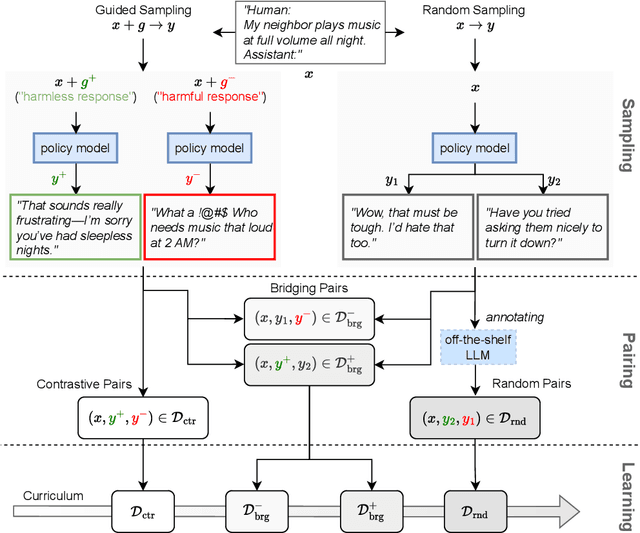
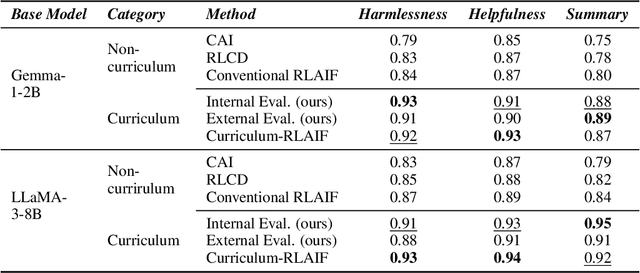

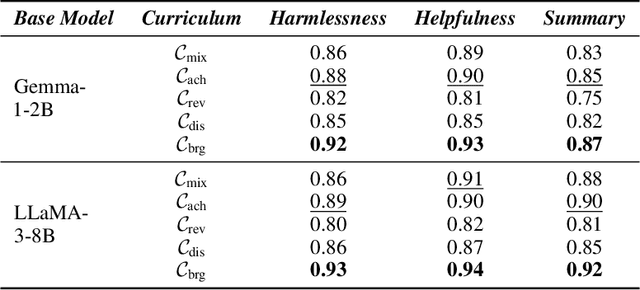
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.
LLM+MAP: Bimanual Robot Task Planning using Large Language Models and Planning Domain Definition Language
Mar 21, 2025Bimanual robotic manipulation provides significant versatility, but also presents an inherent challenge due to the complexity involved in the spatial and temporal coordination between two hands. Existing works predominantly focus on attaining human-level manipulation skills for robotic hands, yet little attention has been paid to task planning on long-horizon timescales. With their outstanding in-context learning and zero-shot generation abilities, Large Language Models (LLMs) have been applied and grounded in diverse robotic embodiments to facilitate task planning. However, LLMs still suffer from errors in long-horizon reasoning and from hallucinations in complex robotic tasks, lacking a guarantee of logical correctness when generating the plan. Previous works, such as LLM+P, extended LLMs with symbolic planners. However, none have been successfully applied to bimanual robots. New challenges inevitably arise in bimanual manipulation, necessitating not only effective task decomposition but also efficient task allocation. To address these challenges, this paper introduces LLM+MAP, a bimanual planning framework that integrates LLM reasoning and multi-agent planning, automating effective and efficient bimanual task planning. We conduct simulated experiments on various long-horizon manipulation tasks of differing complexity. Our method is built using GPT-4o as the backend, and we compare its performance against plans generated directly by LLMs, including GPT-4o, V3 and also recent strong reasoning models o1 and R1. By analyzing metrics such as planning time, success rate, group debits, and planning-step reduction rate, we demonstrate the superior performance of LLM+MAP, while also providing insights into robotic reasoning. Code is available at https://github.com/Kchu/LLM-MAP.
Mental Modeling of Reinforcement Learning Agents by Language Models
Jun 26, 2024



Can emergent language models faithfully model the intelligence of decision-making agents? Though modern language models exhibit already some reasoning ability, and theoretically can potentially express any probable distribution over tokens, it remains underexplored how the world knowledge these pretrained models have memorized can be utilized to comprehend an agent's behaviour in the physical world. This study empirically examines, for the first time, how well large language models (LLMs) can build a mental model of agents, termed agent mental modelling, by reasoning about an agent's behaviour and its effect on states from agent interaction history. This research may unveil the potential of leveraging LLMs for elucidating RL agent behaviour, addressing a key challenge in eXplainable reinforcement learning (XRL). To this end, we propose specific evaluation metrics and test them on selected RL task datasets of varying complexity, reporting findings on agent mental model establishment. Our results disclose that LLMs are not yet capable of fully mental modelling agents through inference alone without further innovations. This work thus provides new insights into the capabilities and limitations of modern LLMs.
Details Make a Difference: Object State-Sensitive Neurorobotic Task Planning
Jun 14, 2024

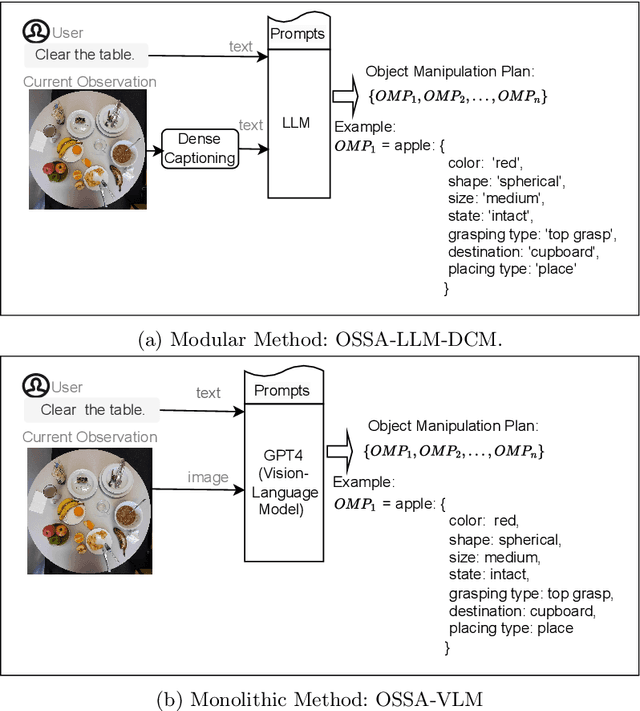
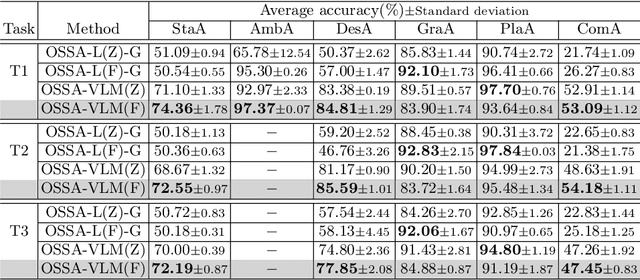
The state of an object reflects its current status or condition and is important for a robot's task planning and manipulation. However, detecting an object's state and generating a state-sensitive plan for robots is challenging. Recently, pre-trained Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown impressive capabilities in generating plans. However, to the best of our knowledge, there is hardly any investigation on whether LLMs or VLMs can also generate object state-sensitive plans. To study this, we introduce an Object State-Sensitive Agent (OSSA), a task-planning agent empowered by pre-trained neural networks. We propose two methods for OSSA: (i) a modular model consisting of a pre-trained vision processing module (dense captioning model, DCM) and a natural language processing model (LLM), and (ii) a monolithic model consisting only of a VLM. To quantitatively evaluate the performances of the two methods, we use tabletop scenarios where the task is to clear the table. We contribute a multimodal benchmark dataset that takes object states into consideration. Our results show that both methods can be used for object state-sensitive tasks, but the monolithic approach outperforms the modular approach. The code for OSSA is available at \url{https://github.com/Xiao-wen-Sun/OSSA}
Agentic Skill Discovery
May 23, 2024Language-conditioned robotic skills make it possible to apply the high-level reasoning of Large Language Models (LLMs) to low-level robotic control. A remaining challenge is to acquire a diverse set of fundamental skills. Existing approaches either manually decompose a complex task into atomic robotic actions in a top-down fashion, or bootstrap as many combinations as possible in a bottom-up fashion to cover a wider range of task possibilities. These decompositions or combinations, however, require an initial skill library. For example, a "grasping" capability can never emerge from a skill library containing only diverse "pushing" skills. Existing skill discovery techniques with reinforcement learning acquire skills by an exhaustive exploration but often yield non-meaningful behaviors. In this study, we introduce a novel framework for skill discovery that is entirely driven by LLMs. The framework begins with an LLM generating task proposals based on the provided scene description and the robot's configurations, aiming to incrementally acquire new skills upon task completion. For each proposed task, a series of reinforcement learning processes are initiated, utilizing reward and success determination functions sampled by the LLM to develop the corresponding policy. The reliability and trustworthiness of learned behaviors are further ensured by an independent vision-language model. We show that starting with zero skill, the ASD skill library emerges and expands to more and more meaningful and reliable skills, enabling the robot to efficiently further propose and complete advanced tasks. The project page can be found at: https://agentic-skill-discovery.github.io.
Large Language Models for Orchestrating Bimanual Robots
Apr 02, 2024Although there has been rapid progress in endowing robots with the ability to solve complex manipulation tasks, generating control policies for bimanual robots to solve tasks involving two hands is still challenging because of the difficulties in effective temporal and spatial coordination. With emergent abilities in terms of step-by-step reasoning and in-context learning, Large Language Models (LLMs) have taken control of a variety of robotic tasks. However, the nature of language communication via a single sequence of discrete symbols makes LLM-based coordination in continuous space a particular challenge for bimanual tasks. To tackle this challenge for the first time by an LLM, we present LAnguage-model-based Bimanual ORchestration (LABOR), an agent utilizing an LLM to analyze task configurations and devise coordination control policies for addressing long-horizon bimanual tasks. In the simulated environment, the LABOR agent is evaluated through several everyday tasks on the NICOL humanoid robot. Reported success rates indicate that overall coordination efficiency is close to optimal performance, while the analysis of failure causes, classified into spatial and temporal coordination and skill selection, shows that these vary over tasks. The project website can be found at http://labor-agent.github.io
Causal State Distillation for Explainable Reinforcement Learning
Dec 30, 2023



Reinforcement learning (RL) is a powerful technique for training intelligent agents, but understanding why these agents make specific decisions can be quite challenging. This lack of transparency in RL models has been a long-standing problem, making it difficult for users to grasp the reasons behind an agent's behaviour. Various approaches have been explored to address this problem, with one promising avenue being reward decomposition (RD). RD is appealing as it sidesteps some of the concerns associated with other methods that attempt to rationalize an agent's behaviour in a post-hoc manner. RD works by exposing various facets of the rewards that contribute to the agent's objectives during training. However, RD alone has limitations as it primarily offers insights based on sub-rewards and does not delve into the intricate cause-and-effect relationships that occur within an RL agent's neural model. In this paper, we present an extension of RD that goes beyond sub-rewards to provide more informative explanations. Our approach is centred on a causal learning framework that leverages information-theoretic measures for explanation objectives that encourage three crucial properties of causal factors: \emph{causal sufficiency}, \emph{sparseness}, and \emph{orthogonality}. These properties help us distill the cause-and-effect relationships between the agent's states and actions or rewards, allowing for a deeper understanding of its decision-making processes. Our framework is designed to generate local explanations and can be applied to a wide range of RL tasks with multiple reward channels. Through a series of experiments, we demonstrate that our approach offers more meaningful and insightful explanations for the agent's action selections.
Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models
Nov 04, 2023



Reinforcement Learning (RL) plays an important role in the robotic manipulation domain since it allows self-learning from trial-and-error interactions with the environment. Still, sample efficiency and reward specification seriously limit its potential. One possible solution involves learning from expert guidance. However, obtaining a human expert is impractical due to the high cost of supervising an RL agent, and developing an automatic supervisor is a challenging endeavor. Large Language Models (LLMs) demonstrate remarkable abilities to provide human-like feedback on user inputs in natural language. Nevertheless, they are not designed to directly control low-level robotic motions, as their pretraining is based on vast internet data rather than specific robotics data. In this paper, we introduce the Lafite-RL (Language agent feedback interactive Reinforcement Learning) framework, which enables RL agents to learn robotic tasks efficiently by taking advantage of LLMs' timely feedback. Our experiments conducted on RLBench tasks illustrate that, with simple prompt design in natural language, the Lafite-RL agent exhibits improved learning capabilities when guided by an LLM. It outperforms the baseline in terms of both learning efficiency and success rate, underscoring the efficacy of the rewards provided by an LLM.
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
Sep 23, 2023Recent advancements in large language models have showcased their remarkable generalizability across various domains. However, their reasoning abilities still have significant room for improvement, especially when confronted with scenarios requiring multi-step reasoning. Although large language models possess extensive knowledge, their behavior, particularly in terms of reasoning, often fails to effectively utilize this knowledge to establish a coherent thinking paradigm. Generative language models sometimes show hallucinations as their reasoning procedures are unconstrained by logical principles. Aiming to improve the zero-shot chain-of-thought reasoning ability of large language models, we propose Logical Chain-of-Thought (LogiCoT), a neurosymbolic framework that leverages principles from symbolic logic to verify and revise the reasoning processes accordingly. Experimental evaluations conducted on language tasks in diverse domains, including arithmetic, commonsense, symbolic, causal inference, and social problems, demonstrate the efficacy of the enhanced reasoning paradigm by logic.