 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning a Generalizable 3D Scene Representation from 2D Observations
Feb 11, 2026We introduce a Generalizable Neural Radiance Field approach for predicting 3D workspace occupancy from egocentric robot observations. Unlike prior methods operating in camera-centric coordinates, our model constructs occupancy representations in a global workspace frame, making it directly applicable to robotic manipulation. The model integrates flexible source views and generalizes to unseen object arrangements without scene-specific finetuning. We demonstrate the approach on a humanoid robot and evaluate predicted geometry against 3D sensor ground truth. Trained on 40 real scenes, our model achieves 26mm reconstruction error, including occluded regions, validating its ability to infer complete 3D occupancy beyond traditional stereo vision methods.
A Closer Look at Reward Decomposition for High-Level Robotic Explanations
Apr 25, 2023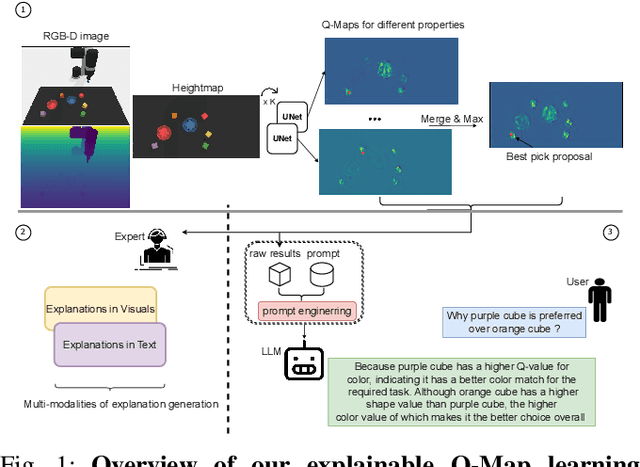

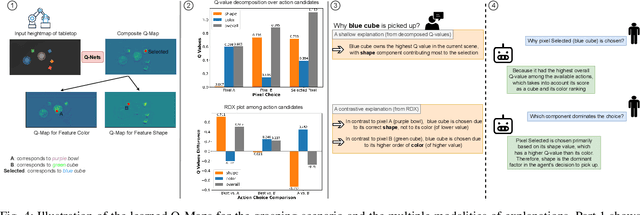
Explaining the behavior of intelligent agents such as robots to humans is challenging due to their incomprehensible proprioceptive states, variational intermediate goals, and resultant unpredictability. Moreover, one-step explanations for reinforcement learning agents can be ambiguous as they fail to account for the agent's future behavior at each transition, adding to the complexity of explaining robot actions. By leveraging abstracted actions that map to task-specific primitives, we avoid explanations on the movement level. Our proposed framework combines reward decomposition (RD) with abstracted action spaces into an explainable learning framework, allowing for non-ambiguous and high-level explanations based on object properties in the task. We demonstrate the effectiveness of our framework through quantitative and qualitative analysis of two robot scenarios, showcasing visual and textual explanations, from output artifacts of RD explanation, that are easy for humans to comprehend. Additionally, we demonstrate the versatility of integrating these artifacts with large language models for reasoning and interactive querying.
Neural Field Conditioning Strategies for 2D Semantic Segmentation
Apr 12, 2023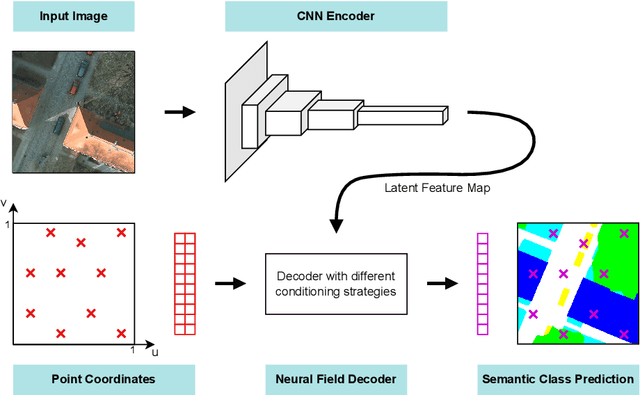


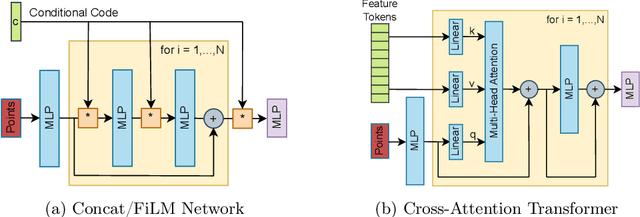
Neural fields are neural networks which map coordinates to a desired signal. When a neural field should jointly model multiple signals, and not memorize only one, it needs to be conditioned on a latent code which describes the signal at hand. Despite being an important aspect, there has been little research on conditioning strategies for neural fields. In this work, we explore the use of neural fields as decoders for 2D semantic segmentation. For this task, we compare three conditioning methods, simple concatenation of the latent code, Feature Wise Linear Modulation (FiLM), and Cross-Attention, in conjunction with latent codes which either describe the full image or only a local region of the image. Our results show a considerable difference in performance between the examined conditioning strategies. Furthermore, we show that conditioning via Cross-Attention achieves the best results and is competitive with a CNN-based decoder for semantic segmentation.
Robotic Tissue Sampling for Safe Post-mortem Biopsy in Infectious Corpses
Jan 28, 2022
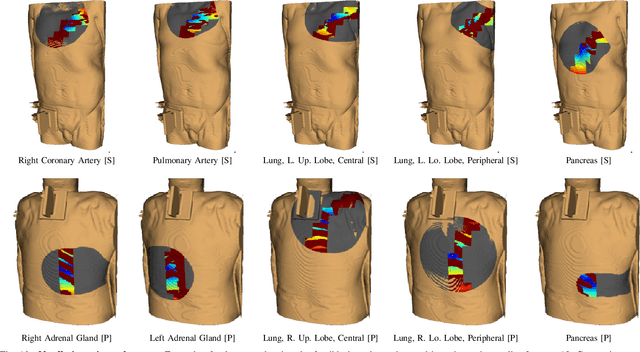
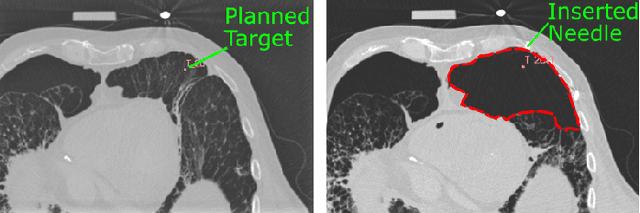
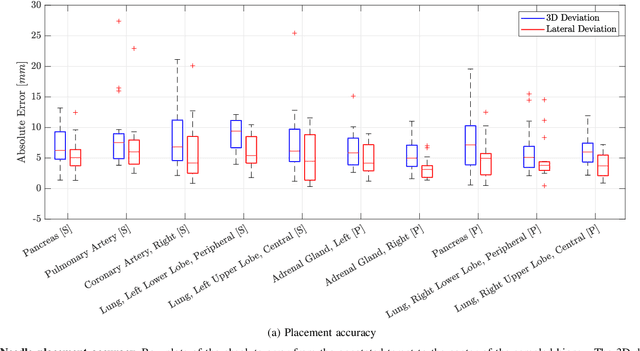
In pathology and legal medicine, the histopathological and microbiological analysis of tissue samples from infected deceased is a valuable information for developing treatment strategies during a pandemic such as COVID-19. However, a conventional autopsy carries the risk of disease transmission and may be rejected by relatives. We propose minimally invasive biopsy with robot assistance under CT guidance to minimize the risk of disease transmission during tissue sampling and to improve accuracy. A flexible robotic system for biopsy sampling is presented, which is applied to human corpses placed inside protective body bags. An automatic planning and decision system estimates optimal insertion point. Heat maps projected onto the segmented skin visualize the distance and angle of insertions and estimate the minimum cost of a puncture while avoiding bone collisions. Further, we test multiple insertion paths concerning feasibility and collisions. A custom end effector is designed for inserting needles and extracting tissue samples under robotic guidance. Our robotic post-mortem biopsy (RPMB) system is evaluated in a study during the COVID-19 pandemic on 20 corpses and 10 tissue targets, 5 of them being infected with SARS-CoV-2. The mean planning time including robot path planning is (5.72+-1.67) s. Mean needle placement accuracy is (7.19+-4.22) mm.
Towards Deep Learning-Based EEG Electrode Detection Using Automatically Generated Labels
Aug 12, 2019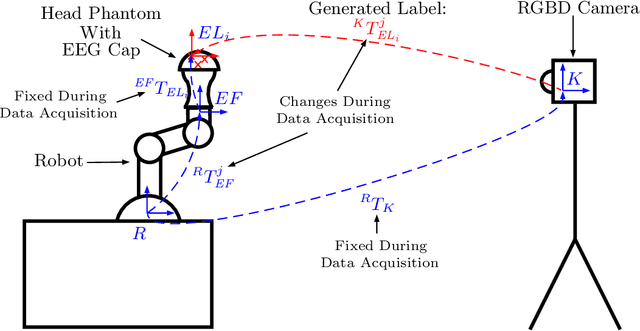
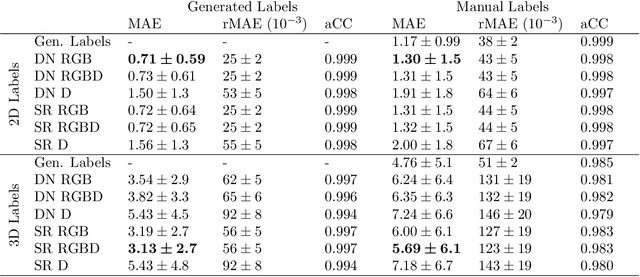
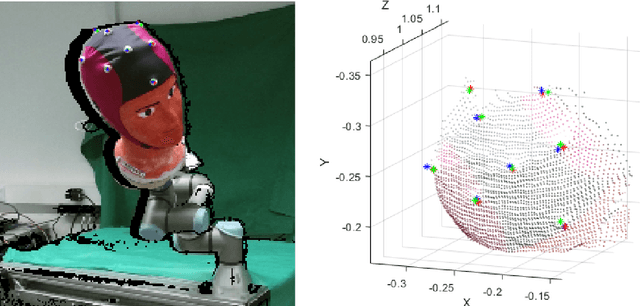
Electroencephalography (EEG) allows for source measurement of electrical brain activity. Particularly for inverse localization, the electrode positions on the scalp need to be known. Often, systems such as optical digitizing scanners are used for accurate localization with a stylus. However, the approach is time-consuming as each electrode needs to be scanned manually and the scanning systems are expensive. We propose using an RGBD camera to directly track electrodes in the images using deep learning methods. Studying and evaluating deep learning methods requires large amounts of labeled data. To overcome the time-consuming data annotation, we generate a large number of ground-truth labels using a robotic setup. We demonstrate that deep learning-based electrode detection is feasible with a mean absolute error of 5.69 +- 6.1mm and that our annotation scheme provides a useful environment for studying deep learning methods for electrode detection.
Two-path 3D CNNs for calibration of system parameters for OCT-based motion compensation
Oct 22, 2018Automatic motion compensation and adjustment of an intraoperative imaging modality's field of view is a common problem during interventions. Optical coherence tomography (OCT) is an imaging modality which is used in interventions due to its high spatial resolution of few micrometers and its temporal resolution of potentially several hundred volumes per second. However, performing motion compensation with OCT is problematic due to its small field of view which might lead to tracked objects being lost quickly. We propose a novel deep learning-based approach that directly learns input parameters of motors that move the scan area for motion compensation from optical coherence tomography volumes. We design a two-path 3D convolutional neural network (CNN) architecture that takes two volumes with an object to be tracked as its input and predicts the necessary motor input parameters to compensate the object's movement. In this way, we learn the calibration between object movement and system parameters for motion compensation with arbitrary objects. Thus, we avoid error-prone hand-eye calibration and handcrafted feature tracking from classical approaches. We achieve an average correlation coefficient of 0.998 between predicted and ground-truth motor parameters which leads to sub-voxel accuracy. Furthermore, we show that our deep learning model is real-time capable for use with the system's high volume acquisition frequency.
Towards Head Motion Compensation Using Multi-Scale Convolutional Neural Networks
Jul 10, 2018



Head pose estimation and tracking is useful in variety of medical applications. With the advent of RGBD cameras like Kinect, it has become feasible to do markerless tracking by estimating the head pose directly from the point clouds. One specific medical application is robot assisted transcranial magnetic stimulation (TMS) where any patient motion is compensated with the help of a robot. For increased patient comfort, it is important to track the head without markers. In this regard, we address the head pose estimation problem using two different approaches. In the first approach, we build upon the more traditional approach of model based head tracking, where a head model is morphed according to the particular head to be tracked and the morphed model is used to track the head in the point cloud streams. In the second approach, we propose a new multi-scale convolutional neural network architecture for more accurate pose regression. Additionally, we outline a systematic data set acquisition strategy using a head phantom mounted on the robot and ground-truth labels generated using a highly accurate tracking system.