 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning with 4D spatio-temporal data representations for OCT-based force estimation
May 20, 2020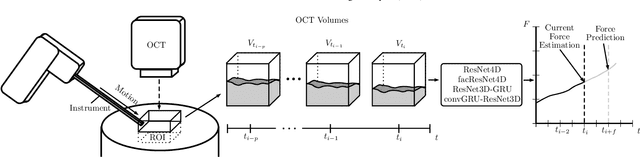
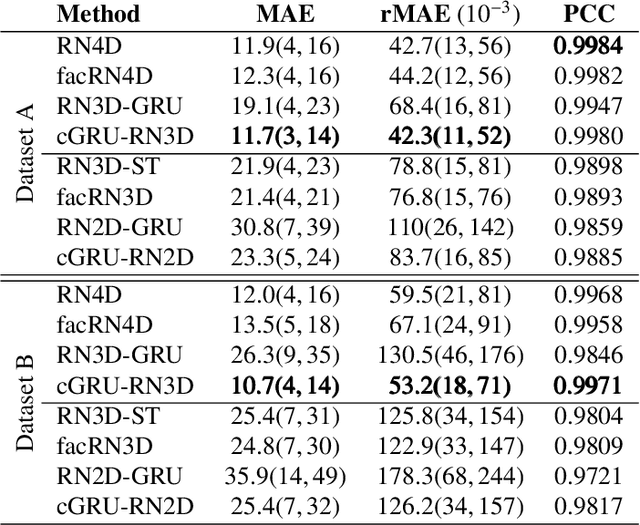
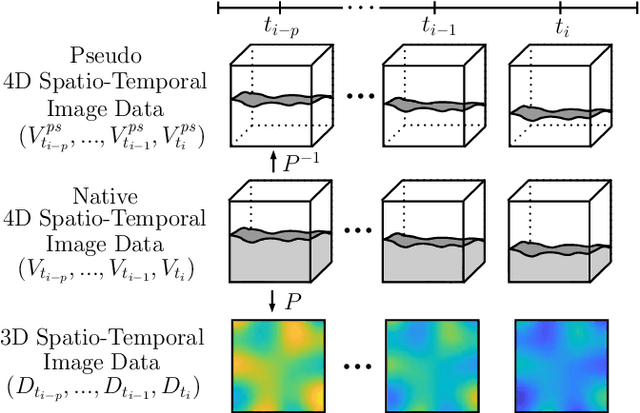
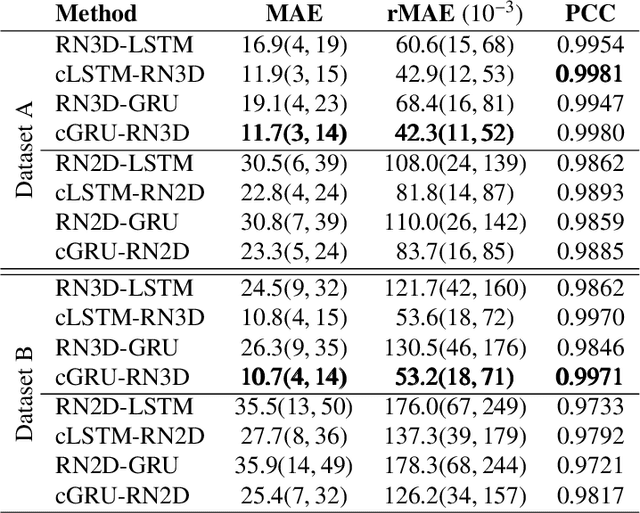
Estimating the forces acting between instruments and tissue is a challenging problem for robot-assisted minimally-invasive surgery. Recently, numerous vision-based methods have been proposed to replace electro-mechanical approaches. Moreover, optical coherence tomography (OCT) and deep learning have been used for estimating forces based on deformation observed in volumetric image data. The method demonstrated the advantage of deep learning with 3D volumetric data over 2D depth images for force estimation. In this work, we extend the problem of deep learning-based force estimation to 4D spatio-temporal data with streams of 3D OCT volumes. For this purpose, we design and evaluate several methods extending spatio-temporal deep learning to 4D which is largely unexplored so far. Furthermore, we provide an in-depth analysis of multi-dimensional image data representations for force estimation, comparing our 4D approach to previous, lower-dimensional methods. Also, we analyze the effect of temporal information and we study the prediction of short-term future force values, which could facilitate safety features. For our 4D force estimation architectures, we find that efficient decoupling of spatial and temporal processing is advantageous. We show that using 4D spatio-temporal data outperforms all previously used data representations with a mean absolute error of 10.7mN. We find that temporal information is valuable for force estimation and we demonstrate the feasibility of force prediction.
Spatio-Temporal Deep Learning Methods for Motion Estimation Using 4D OCT Image Data
Apr 21, 2020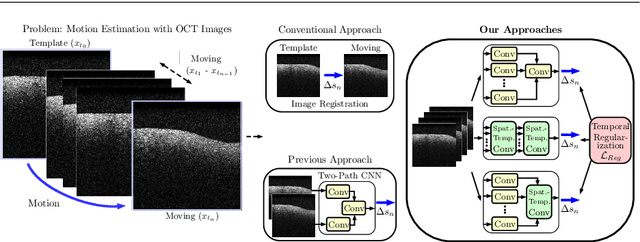
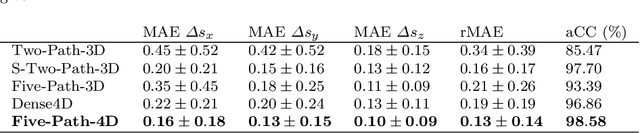
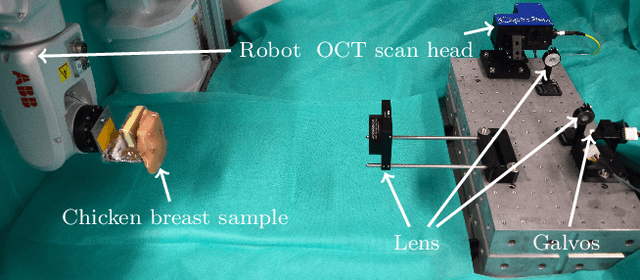
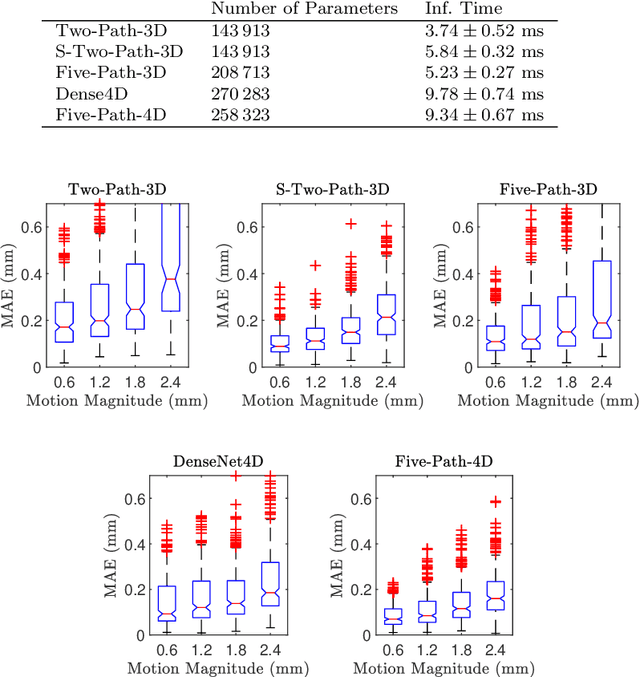
Purpose. Localizing structures and estimating the motion of a specific target region are common problems for navigation during surgical interventions. Optical coherence tomography (OCT) is an imaging modality with a high spatial and temporal resolution that has been used for intraoperative imaging and also for motion estimation, for example, in the context of ophthalmic surgery or cochleostomy. Recently, motion estimation between a template and a moving OCT image has been studied with deep learning methods to overcome the shortcomings of conventional, feature-based methods. Methods. We investigate whether using a temporal stream of OCT image volumes can improve deep learning-based motion estimation performance. For this purpose, we design and evaluate several 3D and 4D deep learning methods and we propose a new deep learning approach. Also, we propose a temporal regularization strategy at the model output. Results. Using a tissue dataset without additional markers, our deep learning methods using 4D data outperform previous approaches. The best performing 4D architecture achieves an correlation coefficient (aCC) of 98.58% compared to 85.0% of a previous 3D deep learning method. Also, our temporal regularization strategy at the output further improves 4D model performance to an aCC of 99.06%. In particular, our 4D method works well for larger motion and is robust towards image rotations and motion distortions. Conclusions. We propose 4D spatio-temporal deep learning for OCT-based motion estimation. On a tissue dataset, we find that using 4D information for the model input improves performance while maintaining reasonable inference times. Our regularization strategy demonstrates that additional temporal information is also beneficial at the model output.
Towards Automatic Lesion Classification in the Upper Aerodigestive Tract Using OCT and Deep Transfer Learning Methods
Feb 10, 2019
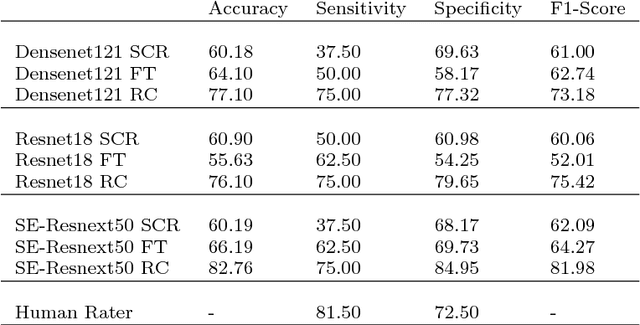
Early detection of cancer is crucial for treatment and overall patient survival. In the upper aerodigestive tract (UADT) the gold standard for identification of malignant tissue is an invasive biopsy. Recently, non-invasive imaging techniques such as confocal laser microscopy and optical coherence tomography (OCT) have been used for tissue assessment. In particular, in a recent study experts classified lesions in the UADT with respect to their invasiveness using OCT images only. As the results were promising, automatic classification of lesions might be feasible which could assist experts in their decision making. Therefore, we address the problem of automatic lesion classification from OCT images. This task is very challenging as the available dataset is extremely small and the data quality is limited. However, as similar issues are typical in many clinical scenarios we study to what extent deep learning approaches can still be trained and used for decision support.
Two-path 3D CNNs for calibration of system parameters for OCT-based motion compensation
Oct 22, 2018Automatic motion compensation and adjustment of an intraoperative imaging modality's field of view is a common problem during interventions. Optical coherence tomography (OCT) is an imaging modality which is used in interventions due to its high spatial resolution of few micrometers and its temporal resolution of potentially several hundred volumes per second. However, performing motion compensation with OCT is problematic due to its small field of view which might lead to tracked objects being lost quickly. We propose a novel deep learning-based approach that directly learns input parameters of motors that move the scan area for motion compensation from optical coherence tomography volumes. We design a two-path 3D convolutional neural network (CNN) architecture that takes two volumes with an object to be tracked as its input and predicts the necessary motor input parameters to compensate the object's movement. In this way, we learn the calibration between object movement and system parameters for motion compensation with arbitrary objects. Thus, we avoid error-prone hand-eye calibration and handcrafted feature tracking from classical approaches. We achieve an average correlation coefficient of 0.998 between predicted and ground-truth motor parameters which leads to sub-voxel accuracy. Furthermore, we show that our deep learning model is real-time capable for use with the system's high volume acquisition frequency.
A Deep Learning Approach for Pose Estimation from Volumetric OCT Data
Mar 10, 2018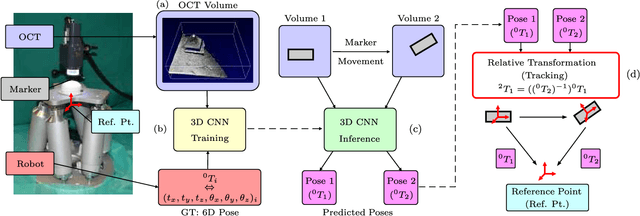
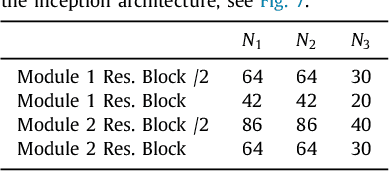
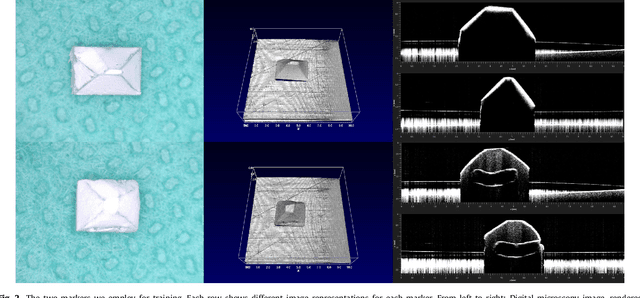
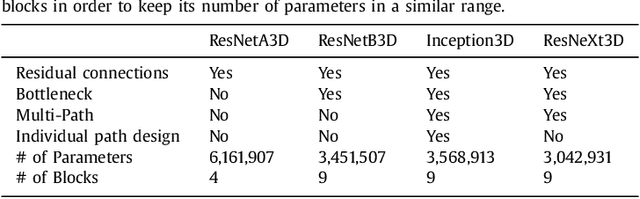
Tracking the pose of instruments is a central problem in image-guided surgery. For microscopic scenarios, optical coherence tomography (OCT) is increasingly used as an imaging modality. OCT is suitable for accurate pose estimation due to its micrometer range resolution and volumetric field of view. However, OCT image processing is challenging due to speckle noise and reflection artifacts in addition to the images' 3D nature. We address pose estimation from OCT volume data with a new deep learning-based tracking framework. For this purpose, we design a new 3D convolutional neural network (CNN) architecture to directly predict the 6D pose of a small marker geometry from OCT volumes. We use a hexapod robot to automatically acquire labeled data points which we use to train 3D CNN architectures for multi-output regression. We use this setup to provide an in-depth analysis on deep learning-based pose estimation from volumes. Specifically, we demonstrate that exploiting volume information for pose estimation yields higher accuracy than relying on 2D representations with depth information. Supporting this observation, we provide quantitative and qualitative results that 3D CNNs effectively exploit the depth structure of marker objects. Regarding the deep learning aspect, we present efficient design principles for 3D CNNs, making use of insights from the 2D deep learning community. In particular, we present Inception3D as a new architecture which performs best for our application. We show that our deep learning approach reaches errors at our ground-truth label's resolution. We achieve a mean average error of $\SI{14.89 \pm 9.3}{\micro\metre}$ and $\SI{0.096 \pm 0.072}{\degree}$ for position and orientation learning, respectively.