 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach for Pose Estimation from Volumetric OCT Data
Paper and Code
Mar 10, 2018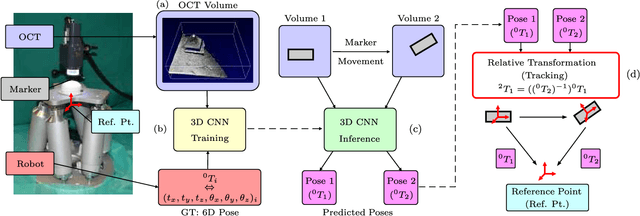
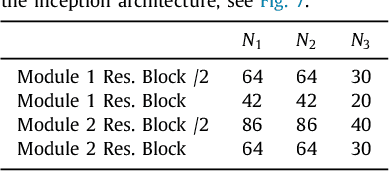
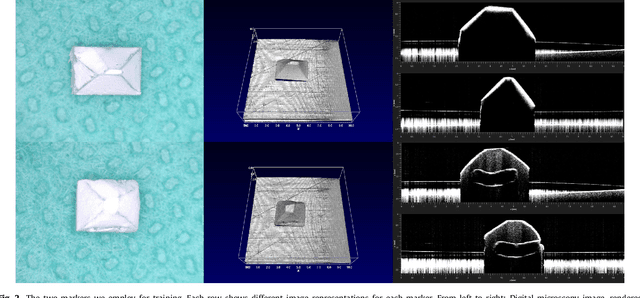
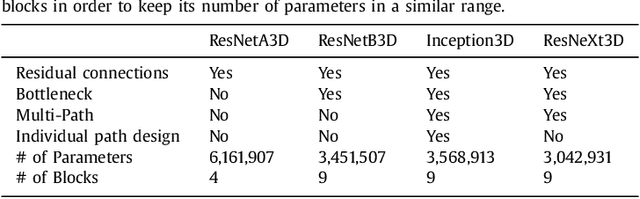
Tracking the pose of instruments is a central problem in image-guided surgery. For microscopic scenarios, optical coherence tomography (OCT) is increasingly used as an imaging modality. OCT is suitable for accurate pose estimation due to its micrometer range resolution and volumetric field of view. However, OCT image processing is challenging due to speckle noise and reflection artifacts in addition to the images' 3D nature. We address pose estimation from OCT volume data with a new deep learning-based tracking framework. For this purpose, we design a new 3D convolutional neural network (CNN) architecture to directly predict the 6D pose of a small marker geometry from OCT volumes. We use a hexapod robot to automatically acquire labeled data points which we use to train 3D CNN architectures for multi-output regression. We use this setup to provide an in-depth analysis on deep learning-based pose estimation from volumes. Specifically, we demonstrate that exploiting volume information for pose estimation yields higher accuracy than relying on 2D representations with depth information. Supporting this observation, we provide quantitative and qualitative results that 3D CNNs effectively exploit the depth structure of marker objects. Regarding the deep learning aspect, we present efficient design principles for 3D CNNs, making use of insights from the 2D deep learning community. In particular, we present Inception3D as a new architecture which performs best for our application. We show that our deep learning approach reaches errors at our ground-truth label's resolution. We achieve a mean average error of $\SI{14.89 \pm 9.3}{\micro\metre}$ and $\SI{0.096 \pm 0.072}{\degree}$ for position and orientation learning, respectively.