 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mar 27, 2025



Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
Baichuan-Audio: A Unified Framework for End-to-End Speech Interaction
Feb 24, 2025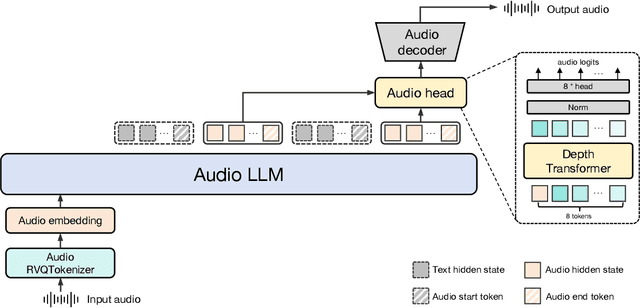
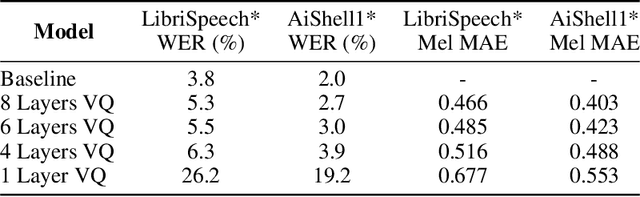
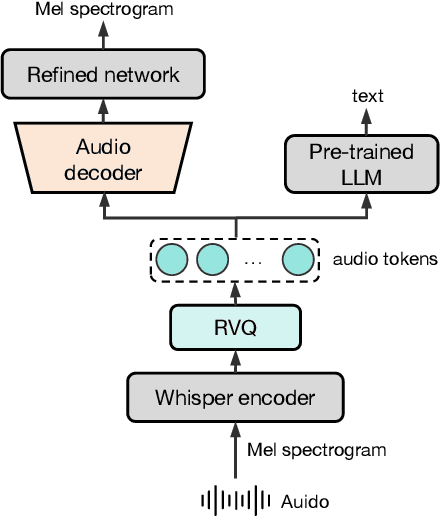
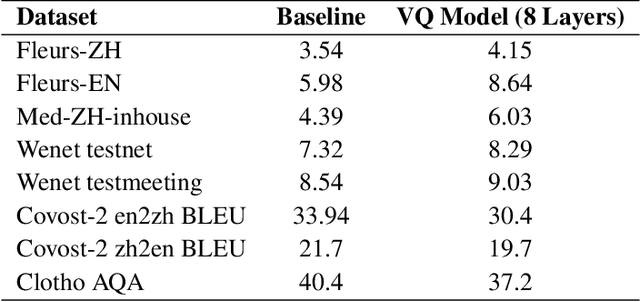
We introduce Baichuan-Audio, an end-to-end audio large language model that seamlessly integrates audio understanding and generation. It features a text-guided aligned speech generation mechanism, enabling real-time speech interaction with both comprehension and generation capabilities. Baichuan-Audio leverages a pre-trained ASR model, followed by multi-codebook discretization of speech at a frame rate of 12.5 Hz. This multi-codebook setup ensures that speech tokens retain both semantic and acoustic information. To further enhance modeling, an independent audio head is employed to process audio tokens, effectively capturing their unique characteristics. To mitigate the loss of intelligence during pre-training and preserve the original capabilities of the LLM, we propose a two-stage pre-training strategy that maintains language understanding while enhancing audio modeling. Following alignment, the model excels in real-time speech-based conversation and exhibits outstanding question-answering capabilities, demonstrating its versatility and efficiency. The proposed model demonstrates superior performance in real-time spoken dialogue and exhibits strong question-answering abilities. Our code, model and training data are available at https://github.com/baichuan-inc/Baichuan-Audio
MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification
Feb 19, 2025



According to the Test-Time Scaling, the integration of External Slow-Thinking with the Verify mechanism has been demonstrated to enhance multi-round reasoning in large language models (LLMs). However, in the multimodal (MM) domain, there is still a lack of a strong MM-Verifier. In this paper, we introduce MM-Verifier and MM-Reasoner to enhance multimodal reasoning through longer inference and more robust verification. First, we propose a two-step MM verification data synthesis method, which combines a simulation-based tree search with verification and uses rejection sampling to generate high-quality Chain-of-Thought (COT) data. This data is then used to fine-tune the verification model, MM-Verifier. Additionally, we present a more efficient method for synthesizing MMCOT data, bridging the gap between text-based and multimodal reasoning. The synthesized data is used to fine-tune MM-Reasoner. Our MM-Verifier outperforms all larger models on the MathCheck, MathVista, and MathVerse benchmarks. Moreover, MM-Reasoner demonstrates strong effectiveness and scalability, with performance improving as data size increases. Finally, our approach achieves strong performance when combining MM-Reasoner and MM-Verifier, reaching an accuracy of 65.3 on MathVista, surpassing GPT-4o (63.8) with 12 rollouts.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Baichuan Alignment Technical Report
Oct 19, 2024



We introduce Baichuan Alignment, a detailed analysis of the alignment techniques employed in the Baichuan series of models. This represents the industry's first comprehensive account of alignment methodologies, offering valuable insights for advancing AI research. We investigate the critical components that enhance model performance during the alignment process, including optimization methods, data strategies, capability enhancements, and evaluation processes. The process spans three key stages: Prompt Augmentation System (PAS), Supervised Fine-Tuning (SFT), and Preference Alignment. The problems encountered, the solutions applied, and the improvements made are thoroughly recorded. Through comparisons across well-established benchmarks, we highlight the technological advancements enabled by Baichuan Alignment. Baichuan-Instruct is an internal model, while Qwen2-Nova-72B and Llama3-PBM-Nova-70B are instruct versions of the Qwen2-72B and Llama-3-70B base models, optimized through Baichuan Alignment. Baichuan-Instruct demonstrates significant improvements in core capabilities, with user experience gains ranging from 17% to 28%, and performs exceptionally well on specialized benchmarks. In open-source benchmark evaluations, both Qwen2-Nova-72B and Llama3-PBM-Nova-70B consistently outperform their respective official instruct versions across nearly all datasets. This report aims to clarify the key technologies behind the alignment process, fostering a deeper understanding within the community. Llama3-PBM-Nova-70B model is available at https://huggingface.co/PKU-Baichuan-MLSystemLab/Llama3-PBM-Nova-70B.
Facilitating Multi-turn Function Calling for LLMs via Compositional Instruction Tuning
Oct 16, 2024



Large Language Models (LLMs) have exhibited significant potential in performing diverse tasks, including the ability to call functions or use external tools to enhance their performance. While current research on function calling by LLMs primarily focuses on single-turn interactions, this paper addresses the overlooked necessity for LLMs to engage in multi-turn function calling--critical for handling compositional, real-world queries that require planning with functions but not only use functions. To facilitate this, we introduce an approach, BUTTON, which generates synthetic compositional instruction tuning data via bottom-up instruction construction and top-down trajectory generation. In the bottom-up phase, we generate simple atomic tasks based on real-world scenarios and build compositional tasks using heuristic strategies based on atomic tasks. Corresponding functions are then developed for these compositional tasks. The top-down phase features a multi-agent environment where interactions among simulated humans, assistants, and tools are utilized to gather multi-turn function calling trajectories. This approach ensures task compositionality and allows for effective function and trajectory generation by examining atomic tasks within compositional tasks. We produce a dataset BUTTONInstruct comprising 8k data points and demonstrate its effectiveness through extensive experiments across various LLMs.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
Informative Subgraphs Aware Masked Auto-Encoder in Dynamic Graphs
Sep 14, 2024



Generative self-supervised learning (SSL), especially masked autoencoders (MAE), has greatly succeeded and garnered substantial research interest in graph machine learning. However, the research of MAE in dynamic graphs is still scant. This gap is primarily due to the dynamic graph not only possessing topological structure information but also encapsulating temporal evolution dependency. Applying a random masking strategy which most MAE methods adopt to dynamic graphs will remove the crucial subgraph that guides the evolution of dynamic graphs, resulting in the loss of crucial spatio-temporal information in node representations. To bridge this gap, in this paper, we propose a novel Informative Subgraphs Aware Masked Auto-Encoder in Dynamic Graph, namely DyGIS. Specifically, we introduce a constrained probabilistic generative model to generate informative subgraphs that guide the evolution of dynamic graphs, successfully alleviating the issue of missing dynamic evolution subgraphs. The informative subgraph identified by DyGIS will serve as the input of dynamic graph masked autoencoder (DGMAE), effectively ensuring the integrity of the evolutionary spatio-temporal information within dynamic graphs. Extensive experiments on eleven datasets demonstrate that DyGIS achieves state-of-the-art performance across multiple tasks.
BaichuanSEED: Sharing the Potential of ExtensivE Data Collection and Deduplication by Introducing a Competitive Large Language Model Baseline
Aug 27, 2024
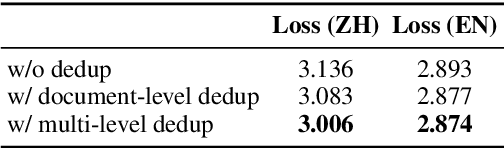

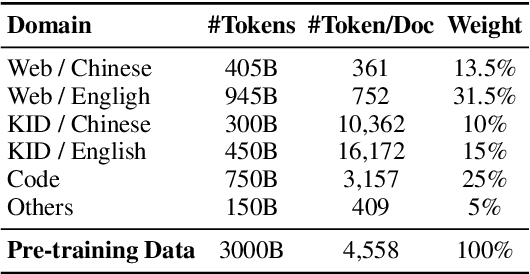
The general capabilities of Large Language Models (LLM) highly rely on the composition and selection on extensive pretraining datasets, treated as commercial secrets by several institutions. To mitigate this issue, we open-source the details of a universally applicable data processing pipeline and validate its effectiveness and potential by introducing a competitive LLM baseline. Specifically, the data processing pipeline consists of broad collection to scale up and reweighting to improve quality. We then pretrain a 7B model BaichuanSEED with 3T tokens processed by our pipeline without any deliberate downstream task-related optimization, followed by an easy but effective supervised fine-tuning stage. BaichuanSEED demonstrates consistency and predictability throughout training and achieves comparable performance on comprehensive benchmarks with several commercial advanced large language models, such as Qwen1.5 and Llama3. We also conduct several heuristic experiments to discuss the potential for further optimization of downstream tasks, such as mathematics and coding.
MathScape: Evaluating MLLMs in multimodal Math Scenarios through a Hierarchical Benchmark
Aug 15, 2024With the development of Multimodal Large Language Models (MLLMs), the evaluation of multimodal models in the context of mathematical problems has become a valuable research field. Multimodal visual-textual mathematical reasoning serves as a critical indicator for evaluating the comprehension and complex multi-step quantitative reasoning abilities of MLLMs. However, previous multimodal math benchmarks have not sufficiently integrated visual and textual information. To address this gap, we proposed MathScape, a new benchmark that emphasizes the understanding and application of combined visual and textual information. MathScape is designed to evaluate photo-based math problem scenarios, assessing the theoretical understanding and application ability of MLLMs through a categorical hierarchical approach. We conduct a multi-dimensional evaluation on 11 advanced MLLMs, revealing that our benchmark is challenging even for the most sophisticated models. By analyzing the evaluation results, we identify the limitations of MLLMs, offering valuable insights for enhancing model performance.