 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling with Explicit Memory
Dec 11, 2024



Recent studies indicate that the denoising process in deep generative diffusion models implicitly learns and memorizes semantic information from the data distribution. These findings suggest that capturing more complex data distributions requires larger neural networks, leading to a substantial increase in computational demands, which in turn become the primary bottleneck in both training and inference of diffusion models. To this end, we introduce \textbf{G}enerative \textbf{M}odeling with \textbf{E}xplicit \textbf{M}emory (GMem), leveraging an external memory bank in both training and sampling phases of diffusion models. This approach preserves semantic information from data distributions, reducing reliance on neural network capacity for learning and generalizing across diverse datasets. The results are significant: our GMem enhances both training, sampling efficiency, and generation quality. For instance, on ImageNet at $256 \times 256$ resolution, GMem accelerates SiT training by over $46.7\times$, achieving the performance of a SiT model trained for $7M$ steps in fewer than $150K$ steps. Compared to the most efficient existing method, REPA, GMem still offers a $16\times$ speedup, attaining an FID score of 5.75 within $250K$ steps, whereas REPA requires over $4M$ steps. Additionally, our method achieves state-of-the-art generation quality, with an FID score of {3.56} without classifier-free guidance on ImageNet $256\times256$. Our code is available at \url{https://github.com/LINs-lab/GMem}.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
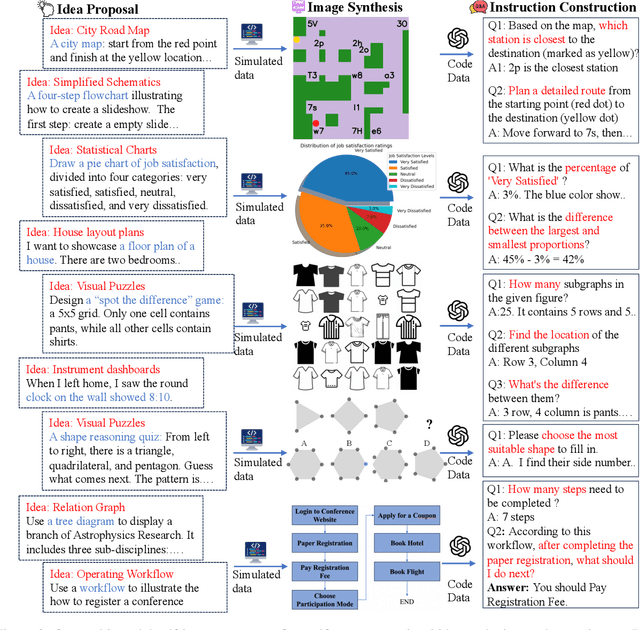
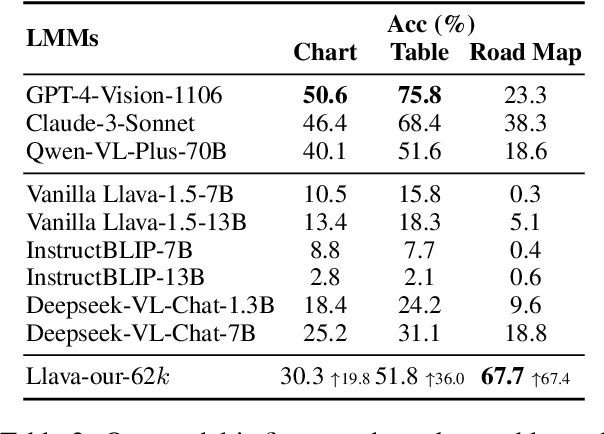
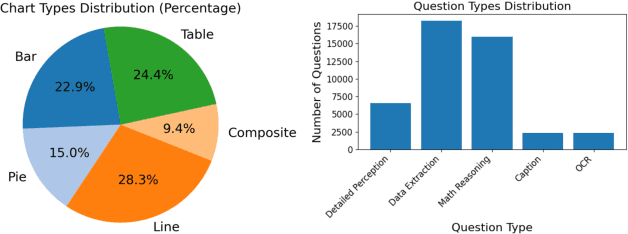
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
May 23, 2024The Sparse Mixture of Experts (SMoE) has been widely employed to enhance the efficiency of training and inference for Transformer-based foundational models, yielding promising results. However, the performance of SMoE heavily depends on the choice of hyper-parameters, such as the number of experts and the number of experts to be activated (referred to as top-k), resulting in significant computational overhead due to the extensive model training by searching over various hyper-parameter configurations. As a remedy, we introduce the Dynamic Mixture of Experts (DynMoE) technique. DynMoE incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training. Extensive numerical results across Vision, Language, and Vision-Language tasks demonstrate the effectiveness of our approach to achieve competitive performance compared to GMoE for vision and language tasks, and MoE-LLaVA for vision-language tasks, while maintaining efficiency by activating fewer parameters. Our code is available at https://github.com/LINs-lab/DynMoE.