 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Forcing: Joint Next-K-Token Decoding via Push-Forward Language Modeling
Jun 09, 2026Autoregressive (AR) language modeling is the dominant paradigm for text generation, yet its sequential token-by-token decoding makes inference memory-bound and inefficient. Existing acceleration approaches, such as speculative decoding and diffusion language models, can yield speedups under certain conditions but do not directly address high-load batch serving--the scenario most critical for industrial-scale deployment. We introduce K-Forcing, a push-forward language modeling paradigm for joint next-k-token decoding. K-Forcing distills an existing AR model into a conditional push-forward mapping--one that transforms independent uniform noise variables into a joint sample of multiple future tokens in a single forward pass. This design preserves fixed-length outputs, reuses the AR teacher backbone, and remains compatible with standard AR serving infrastructure. We train this mapping via progressive self-forcing distillation, which gradually expands the prediction window while enabling the student to closely match the sequence distribution of the AR teacher. We evaluate K-Forcing on LM1B and OpenWebText using a standard causal Transformer backbone. When aggressively configured to generate k = 4 tokens per forward pass, K-Forcing delivers approximately 2.4-3.5x speedup across different batch sizes, while incurring modest quality degradation relative to its AR teacher. As inference increasingly dominates the lifetime compute cost of modern LLMs, K-Forcing offers a promising route toward accelerating AR generation under real-world high-load deployment.
OmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Jun 06, 2025Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation due to the lack of joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations: 1) A unified 3D tile-wise granularity that simultaneously supports both quantization and sparsity; 2) A denoising step-aware strategy that adapts to the noise schedule, addressing the strong correlation between quantization/sparsity errors and denoising steps; 3) A native, hardware-friendly kernel that leverages FlashAttention and is implemented with optimized Hopper architecture features for highly efficient execution. Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09x kernel speedup for attention operations and a 4.96x end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution-without sacrificing generation quality.
ZipAR: Accelerating Autoregressive Image Generation through Spatial Locality
Dec 05, 2024

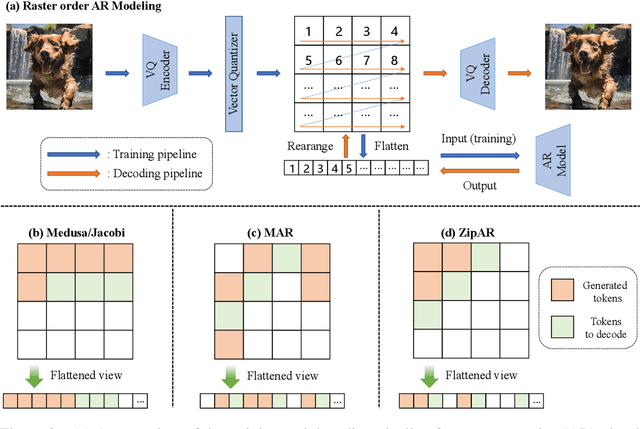

In this paper, we propose ZipAR, a training-free, plug-and-play parallel decoding framework for accelerating auto-regressive (AR) visual generation. The motivation stems from the observation that images exhibit local structures, and spatially distant regions tend to have minimal interdependence. Given a partially decoded set of visual tokens, in addition to the original next-token prediction scheme in the row dimension, the tokens corresponding to spatially adjacent regions in the column dimension can be decoded in parallel, enabling the ``next-set prediction'' paradigm. By decoding multiple tokens simultaneously in a single forward pass, the number of forward passes required to generate an image is significantly reduced, resulting in a substantial improvement in generation efficiency. Experiments demonstrate that ZipAR can reduce the number of model forward passes by up to 91% on the Emu3-Gen model without requiring any additional retraining.
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
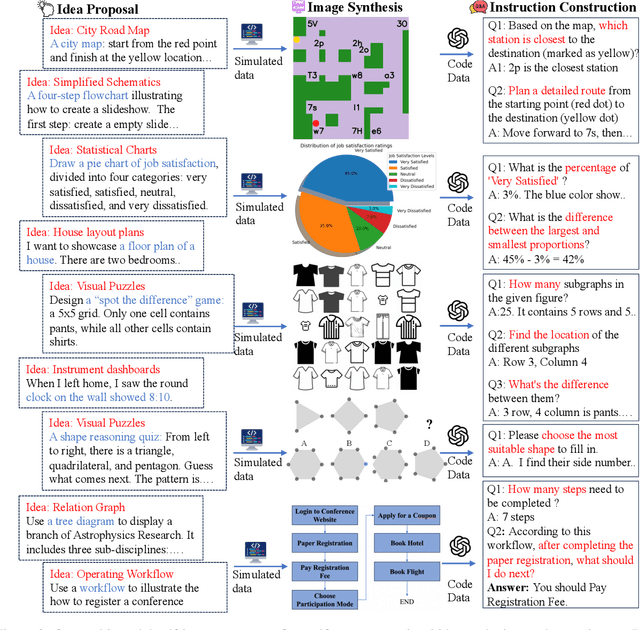
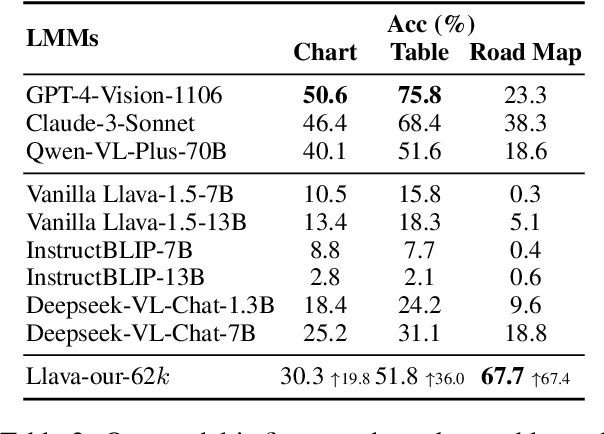
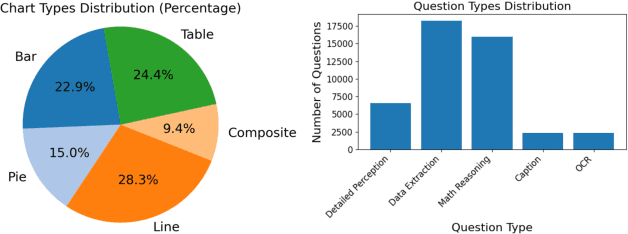
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.