 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Jun 06, 2025Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation due to the lack of joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations: 1) A unified 3D tile-wise granularity that simultaneously supports both quantization and sparsity; 2) A denoising step-aware strategy that adapts to the noise schedule, addressing the strong correlation between quantization/sparsity errors and denoising steps; 3) A native, hardware-friendly kernel that leverages FlashAttention and is implemented with optimized Hopper architecture features for highly efficient execution. Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09x kernel speedup for attention operations and a 4.96x end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution-without sacrificing generation quality.
Q-ViT: Fully Differentiable Quantization for Vision Transformer
Jan 19, 2022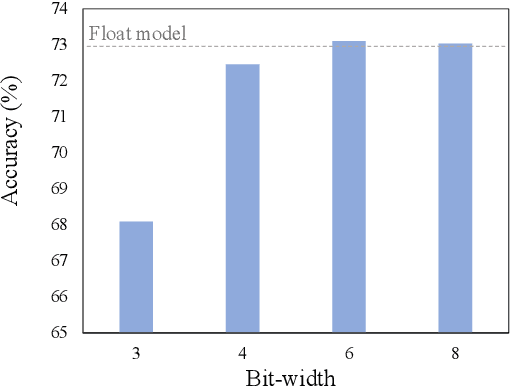
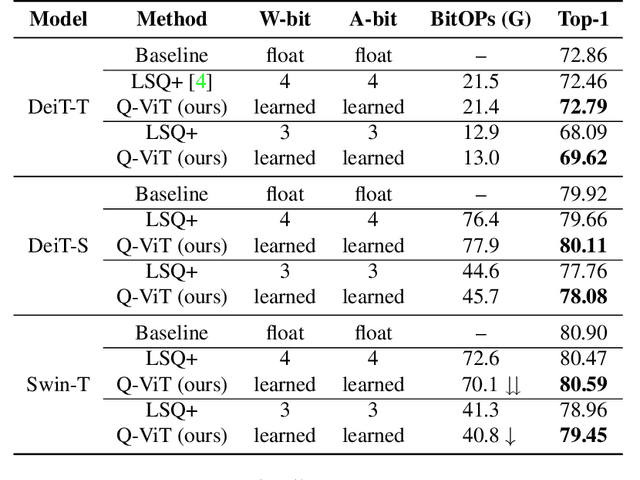
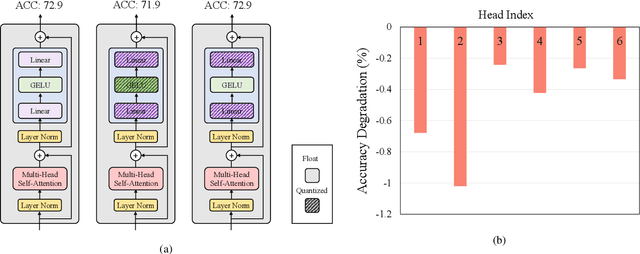

In this paper, we propose a fully differentiable quantization method for vision transformer (ViT) named as Q-ViT, in which both of the quantization scales and bit-widths are learnable parameters. Specifically, based on our observation that heads in ViT display different quantization robustness, we leverage head-wise bit-width to squeeze the size of Q-ViT while preserving performance. In addition, we propose a novel technique named switchable scale to resolve the convergence problem in the joint training of quantization scales and bit-widths. In this way, Q-ViT pushes the limits of ViT quantization to 3-bit without heavy performance drop. Moreover, we analyze the quantization robustness of every architecture component of ViT and show that the Multi-head Self-Attention (MSA) and the Gaussian Error Linear Units (GELU) are the key aspects for ViT quantization. This study provides some insights for further research about ViT quantization. Extensive experiments on different ViT models, such as DeiT and Swin Transformer show the effectiveness of our quantization method. In particular, our method outperforms the state-of-the-art uniform quantization method by 1.5% on DeiT-Tiny.