 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-ViT: Fully Differentiable Quantization for Vision Transformer
Paper and Code
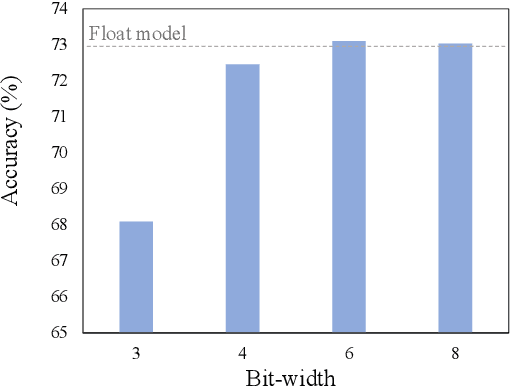
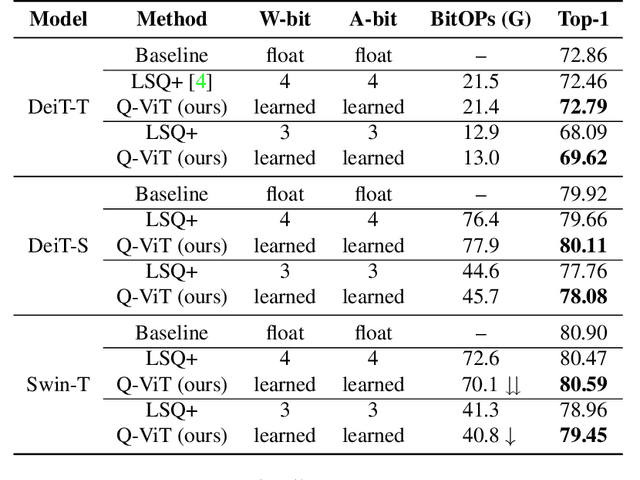
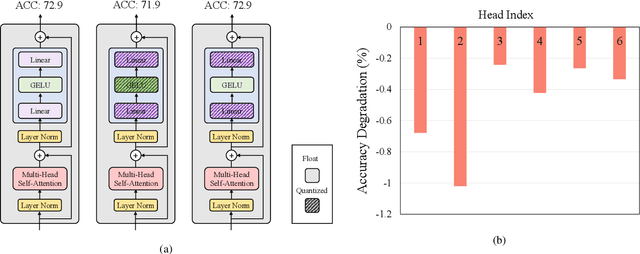

In this paper, we propose a fully differentiable quantization method for vision transformer (ViT) named as Q-ViT, in which both of the quantization scales and bit-widths are learnable parameters. Specifically, based on our observation that heads in ViT display different quantization robustness, we leverage head-wise bit-width to squeeze the size of Q-ViT while preserving performance. In addition, we propose a novel technique named switchable scale to resolve the convergence problem in the joint training of quantization scales and bit-widths. In this way, Q-ViT pushes the limits of ViT quantization to 3-bit without heavy performance drop. Moreover, we analyze the quantization robustness of every architecture component of ViT and show that the Multi-head Self-Attention (MSA) and the Gaussian Error Linear Units (GELU) are the key aspects for ViT quantization. This study provides some insights for further research about ViT quantization. Extensive experiments on different ViT models, such as DeiT and Swin Transformer show the effectiveness of our quantization method. In particular, our method outperforms the state-of-the-art uniform quantization method by 1.5% on DeiT-Tiny.