 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipAR: Accelerating Autoregressive Image Generation through Spatial Locality
Paper and Code
Dec 05, 2024

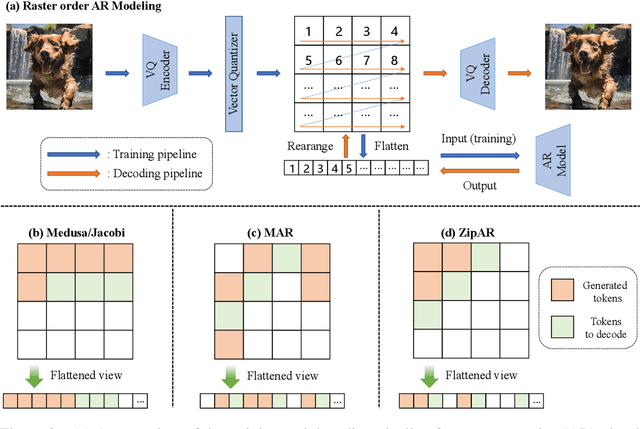

In this paper, we propose ZipAR, a training-free, plug-and-play parallel decoding framework for accelerating auto-regressive (AR) visual generation. The motivation stems from the observation that images exhibit local structures, and spatially distant regions tend to have minimal interdependence. Given a partially decoded set of visual tokens, in addition to the original next-token prediction scheme in the row dimension, the tokens corresponding to spatially adjacent regions in the column dimension can be decoded in parallel, enabling the ``next-set prediction'' paradigm. By decoding multiple tokens simultaneously in a single forward pass, the number of forward passes required to generate an image is significantly reduced, resulting in a substantial improvement in generation efficiency. Experiments demonstrate that ZipAR can reduce the number of model forward passes by up to 91% on the Emu3-Gen model without requiring any additional retraining.