 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSparse: Training-Aware Fine-Grained Sparse Attention for Long-Video MLLMs
Nov 18, 2025Existing sparse attention methods primarily target inference-time acceleration by selecting critical tokens under predefined sparsity patterns. However, they often fail to bridge the training-inference gap and lack the capacity for fine-grained token selection across multiple dimensions such as queries, key-values (KV), and heads, leading to suboptimal performance and limited acceleration gains. In this paper, we introduce OmniSparse, a training-aware fine-grained sparse attention framework for long-video MLLMs, which operates in both training and inference with dynamic token budget allocation. Specifically, OmniSparse contains three adaptive and complementary mechanisms: (1) query selection via lazy-active classification, retaining active queries that capture broad semantic similarity while discarding most lazy ones that focus on limited local context and exhibit high functional redundancy; (2) KV selection with head-level dynamic budget allocation, where a shared budget is determined based on the flattest head and applied uniformly across all heads to ensure attention recall; and (3) KV cache slimming to reduce head-level redundancy by selectively fetching visual KV cache according to the head-level decoding query pattern. Experimental results show that OmniSparse matches the performance of full attention while achieving up to 2.7x speedup during prefill and 2.4x memory reduction during decoding.
ZipAR: Accelerating Autoregressive Image Generation through Spatial Locality
Dec 05, 2024

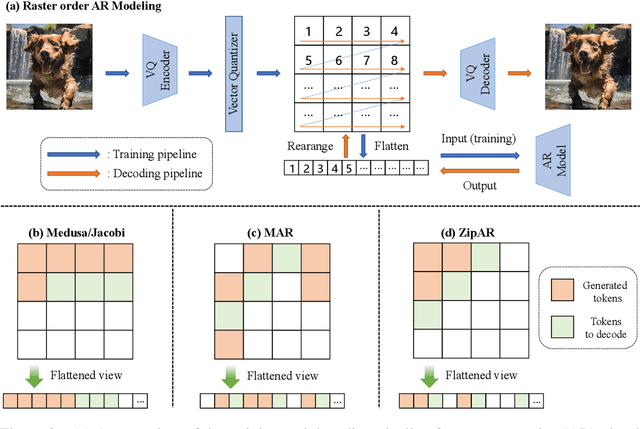

In this paper, we propose ZipAR, a training-free, plug-and-play parallel decoding framework for accelerating auto-regressive (AR) visual generation. The motivation stems from the observation that images exhibit local structures, and spatially distant regions tend to have minimal interdependence. Given a partially decoded set of visual tokens, in addition to the original next-token prediction scheme in the row dimension, the tokens corresponding to spatially adjacent regions in the column dimension can be decoded in parallel, enabling the ``next-set prediction'' paradigm. By decoding multiple tokens simultaneously in a single forward pass, the number of forward passes required to generate an image is significantly reduced, resulting in a substantial improvement in generation efficiency. Experiments demonstrate that ZipAR can reduce the number of model forward passes by up to 91% on the Emu3-Gen model without requiring any additional retraining.
Semantic Codebook Learning for Dynamic Recommendation Models
Jul 31, 2024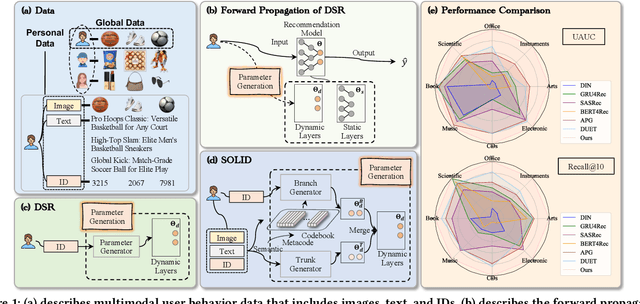
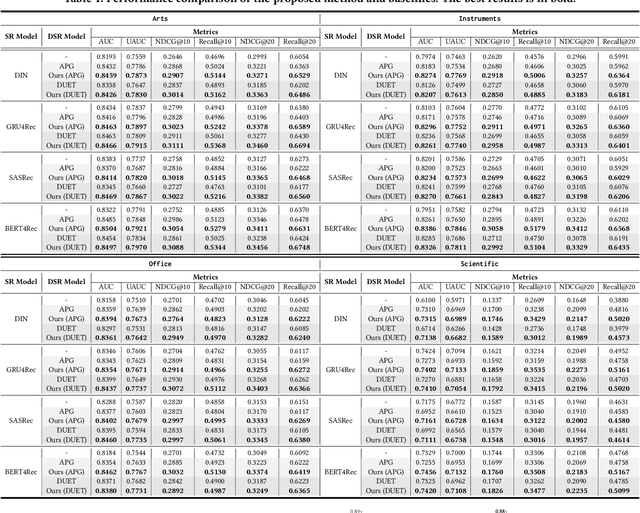
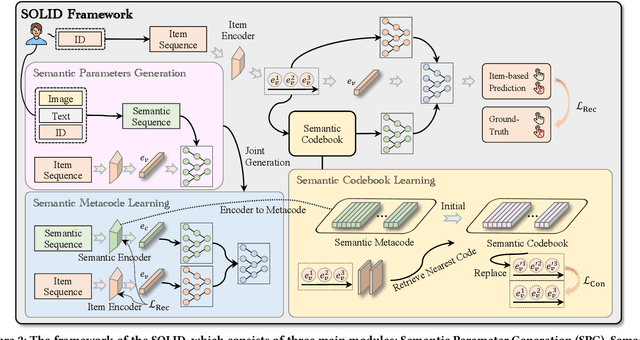

Dynamic sequential recommendation (DSR) can generate model parameters based on user behavior to improve the personalization of sequential recommendation under various user preferences. However, it faces the challenges of large parameter search space and sparse and noisy user-item interactions, which reduces the applicability of the generated model parameters. The Semantic Codebook Learning for Dynamic Recommendation Models (SOLID) framework presents a significant advancement in DSR by effectively tackling these challenges. By transforming item sequences into semantic sequences and employing a dual parameter model, SOLID compresses the parameter generation search space and leverages homogeneity within the recommendation system. The introduction of the semantic metacode and semantic codebook, which stores disentangled item representations, ensures robust and accurate parameter generation. Extensive experiments demonstrates that SOLID consistently outperforms existing DSR, delivering more accurate, stable, and robust recommendations.