 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
May 28, 2026Recent work has begun to equip vision-language-action (VLA) policies with explicit intermediate reasoning. In embodied control, however, textual chain-of-thought is a poor fit: irrelevant or weakly textual information can interfere with action prediction, while autoregressive text decoding adds too much latency for real-time closed-loop execution. We present VISUALTHINK-VLA, a visual intermediate-reasoning framework for accurate, low-latency VLA policies. Our bootstrapping philosophy is to guide action with effective visual thinking: VISUALTHINK-VLA bootstraps action prediction through a compact visual-evidence interface that preserves spatial precision while avoiding decoding overhead. Besides, to further improve performance and efficiency, VISUALTHINK-VLA adopts a tailored selective routing mechanism to learn the visual evidence tokens, enabling low-latency inference while preserving high-capacity specialization. We also introduce VisualEvidence-Kit, a supervision-and-audit resource centered on a VisualEvidence-Agent that constructs a 754.7k VLA instructions VisualEvidence-Set for route supervision and counterfactual faithfulness tests. Across multiple benchmarks and real-robot evaluation, VISUALTHINK-VLA achieves the highest success rate on most benchmarks while reducing the multi-second latency of reasoning-augmented baselines to the sub-second regime. For example, on BridgeData V2, it reduces step latency from 8.377,s with ECoT to 0.367,s, achieving a 22.8 times speedup.
DeepTaxon: An Interpretable Retrieval-Augmented Multimodal Framework for Unified Species Identification and Discovery
Apr 27, 2026Identifying species in biology among tens of thousands of visually similar taxa while discovering unknown species in open-world environments remains a fundamental challenge in biodiversity research. Current methods treat identification and discovery as separate problems, with classification models assuming closed sets and discovery relying on threshold-based rejection. Here we present DeepTaxon, a retrieval-augmented multimodal framework that unifies species identification and discovery through interpretable reasoning over retrieved visual evidence. Given a query image, DeepTaxon retrieves the top-$k$ candidate species with $n$ exemplar images each from a retrieval index and performs chain-of-thought comparative reasoning. Critically, we redefine discovery as an explicit, retrieval-based decision problem rather than an implicit parametric memory problem. A sample is novel if and only if the retrieval index lacks sufficient evidence for identification, so each retrieval naturally yields a classification or discovery label without manual annotation, thereby providing automatic supervision for both tasks. We train the framework via supervised fine-tuning on synthetic retrieval-augmented data, followed by reinforcement learning on hard samples, converting high-recall retrieval into high-precision decisions that scale to massive taxonomic vocabularies. Extensive experiments on a large-scale in-distribution benchmark and six out-of-distribution datasets demonstrate consistent improvements in both identification and discovery. Ablation studies further reveal effective test-time scaling with candidate count $k$ and exemplar count $n$, strong zero-shot transfer to unseen domains, and consistent performance across retrieval encoders, establishing an interpretable solution for biodiversity research.
Semantic Trimming and Auxiliary Multi-step Prediction for Generative Recommendation
Apr 07, 2026Generative Recommendation (GR) has recently transitioned from atomic item-indexing to Semantic ID (SID)-based frameworks to capture intrinsic item relationships and enhance generalization. However, the adoption of high-granularity SIDs leads to two critical challenges: prohibitive training overhead due to sequence expansion and unstable performance reliability characterized by non-monotonic accuracy fluctuations. We identify that these disparate issues are fundamentally rooted in the Semantic Dilution Effect, where redundant tokens waste massive computation and dilute the already sparse learning signals in recommendation. To counteract this, we propose STAMP (Semantic Trimming and Auxiliary Multi-step Prediction), a framework utilizing a dual-end optimization strategy. We argue that effective SID learning requires simultaneously addressing low input information density and sparse output supervision. On the input side, Semantic Adaptive Pruning (SAP) dynamically filters redundancy during the forward pass, converting noise-laden sequences into compact, information-rich representations. On the output side, Multi-step Auxiliary Prediction (MAP) employs a multi-token objective to densify feedback, strengthening long-range dependency capture and ensuring robust learning signals despite compressed inputs. Unifying input purification and signal amplification, STAMP enhances both training efficiency and representation capability. Experiments on public Amazon and large-scale industrial datasets show STAMP achieves 1.23--1.38$\times$ speedup and 17.2\%--54.7\% VRAM reduction while maintaining or improving performance across multiple architectures.
OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
Mar 25, 2026While proprietary systems such as Seedance-2.0 have achieved remarkable success in omni-capable video generation, open-source alternatives significantly lag behind. Most academic models remain heavily fragmented, and the few existing efforts toward unified video generation still struggle to seamlessly integrate diverse tasks within a single framework. To bridge this gap, we propose OmniWeaving, an omni-level video generation model featuring powerful multimodal composition and reasoning-informed capabilities. By leveraging a massive-scale pretraining dataset that encompasses diverse compositional and reasoning-augmented scenarios, OmniWeaving learns to temporally bind interleaved text, multi-image, and video inputs while acting as an intelligent agent to infer complex user intentions for sophisticated video creation. Furthermore, we introduce IntelligentVBench, the first comprehensive benchmark designed to rigorously assess next-level intelligent unified video generation. Extensive experiments demonstrate that OmniWeaving achieves SoTA performance among open-source unified models. The codes and model will be made publicly available soon. Project Page: https://omniweaving.github.io.
CtrlCoT: Dual-Granularity Chain-of-Thought Compression for Controllable Reasoning
Jan 28, 2026Chain-of-thought (CoT) prompting improves LLM reasoning but incurs high latency and memory cost due to verbose traces, motivating CoT compression with preserved correctness. Existing methods either shorten CoTs at the semantic level, which is often conservative, or prune tokens aggressively, which can miss task-critical cues and degrade accuracy. Moreover, combining the two is non-trivial due to sequential dependency, task-agnostic pruning, and distribution mismatch. We propose \textbf{CtrlCoT}, a dual-granularity CoT compression framework that harmonizes semantic abstraction and token-level pruning through three components: Hierarchical Reasoning Abstraction produces CoTs at multiple semantic granularities; Logic-Preserving Distillation trains a logic-aware pruner to retain indispensable reasoning cues (e.g., numbers and operators) across pruning ratios; and Distribution-Alignment Generation aligns compressed traces with fluent inference-time reasoning styles to avoid fragmentation. On MATH-500 with Qwen2.5-7B-Instruct, CtrlCoT uses 30.7\% fewer tokens while achieving 7.6 percentage points higher than the strongest baseline, demonstrating more efficient and reliable reasoning. Our code will be publicly available at https://github.com/fanzhenxuan/Ctrl-CoT.
Enhancing Post-Training Quantization via Future Activation Awareness
Jan 28, 2026Post-training quantization (PTQ) is a widely used method to compress large language models (LLMs) without fine-tuning. It typically sets quantization hyperparameters (e.g., scaling factors) based on current-layer activations. Although this method is efficient, it suffers from quantization bias and error accumulation, resulting in suboptimal and unstable quantization, especially when the calibration data is biased. To overcome these issues, we propose Future-Aware Quantization (FAQ), which leverages future-layer activations to guide quantization. This allows better identification and preservation of important weights, while reducing sensitivity to calibration noise. We further introduce a window-wise preview mechanism to softly aggregate multiple future-layer activations, mitigating over-reliance on any single layer. To avoid expensive greedy search, we use a pre-searched configuration to minimize overhead. Experiments show that FAQ consistently outperforms prior methods with negligible extra cost, requiring no backward passes, data reconstruction, or tuning, making it well-suited for edge deployment.
Device-Cloud Collaborative Correction for On-Device Recommendation
Jun 15, 2025With the rapid development of recommendation models and device computing power, device-based recommendation has become an important research area due to its better real-time performance and privacy protection. Previously, Transformer-based sequential recommendation models have been widely applied in this field because they outperform Recurrent Neural Network (RNN)-based recommendation models in terms of performance. However, as the length of interaction sequences increases, Transformer-based models introduce significantly more space and computational overhead compared to RNN-based models, posing challenges for device-based recommendation. To balance real-time performance and high performance on devices, we propose Device-Cloud \underline{Co}llaborative \underline{Corr}ection Framework for On-Device \underline{Rec}ommendation (CoCorrRec). CoCorrRec uses a self-correction network (SCN) to correct parameters with extremely low time cost. By updating model parameters during testing based on the input token, it achieves performance comparable to current optimal but more complex Transformer-based models. Furthermore, to prevent SCN from overfitting, we design a global correction network (GCN) that processes hidden states uploaded from devices and provides a global correction solution. Extensive experiments on multiple datasets show that CoCorrRec outperforms existing Transformer-based and RNN-based device recommendation models in terms of performance, with fewer parameters and lower FLOPs, thereby achieving a balance between real-time performance and high efficiency.
Cuff-KT: Tackling Learners' Real-time Learning Pattern Adjustment via Tuning-Free Knowledge State Guided Model Updating
May 26, 2025



Knowledge Tracing (KT) is a core component of Intelligent Tutoring Systems, modeling learners' knowledge state to predict future performance and provide personalized learning support. Traditional KT models assume that learners' learning abilities remain relatively stable over short periods or change in predictable ways based on prior performance. However, in reality, learners' abilities change irregularly due to factors like cognitive fatigue, motivation, and external stress -- a task introduced, which we refer to as Real-time Learning Pattern Adjustment (RLPA). Existing KT models, when faced with RLPA, lack sufficient adaptability, because they fail to timely account for the dynamic nature of different learners' evolving learning patterns. Current strategies for enhancing adaptability rely on retraining, which leads to significant overfitting and high time overhead issues. To address this, we propose Cuff-KT, comprising a controller and a generator. The controller assigns value scores to learners, while the generator generates personalized parameters for selected learners. Cuff-KT controllably adapts to data changes fast and flexibly without fine-tuning. Experiments on five datasets from different subjects demonstrate that Cuff-KT significantly improves the performance of five KT models with different structures under intra- and inter-learner shifts, with an average relative increase in AUC of 10% and 4%, respectively, at a negligible time cost, effectively tackling RLPA task. Our code and datasets are fully available at https://github.com/zyy-2001/Cuff-KT.
Multimodal LLM-Guided Semantic Correction in Text-to-Image Diffusion
May 26, 2025



Diffusion models have become the mainstream architecture for text-to-image generation, achieving remarkable progress in visual quality and prompt controllability. However, current inference pipelines generally lack interpretable semantic supervision and correction mechanisms throughout the denoising process. Most existing approaches rely solely on post-hoc scoring of the final image, prompt filtering, or heuristic resampling strategies-making them ineffective in providing actionable guidance for correcting the generative trajectory. As a result, models often suffer from object confusion, spatial errors, inaccurate counts, and missing semantic elements, severely compromising prompt-image alignment and image quality. To tackle these challenges, we propose MLLM Semantic-Corrected Ping-Pong-Ahead Diffusion (PPAD), a novel framework that, for the first time, introduces a Multimodal Large Language Model (MLLM) as a semantic observer during inference. PPAD performs real-time analysis on intermediate generations, identifies latent semantic inconsistencies, and translates feedback into controllable signals that actively guide the remaining denoising steps. The framework supports both inference-only and training-enhanced settings, and performs semantic correction at only extremely few diffusion steps, offering strong generality and scalability. Extensive experiments demonstrate PPAD's significant improvements.
ThinkRec: Thinking-based recommendation via LLM
May 21, 2025
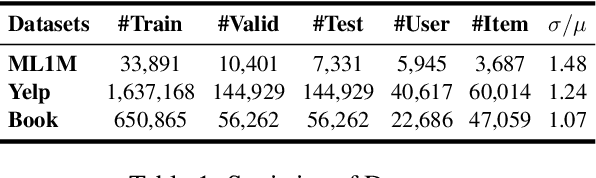


Recent advances in large language models (LLMs) have enabled more semantic-aware recommendations through natural language generation. Existing LLM for recommendation (LLM4Rec) methods mostly operate in a System 1-like manner, relying on superficial features to match similar items based on click history, rather than reasoning through deeper behavioral logic. This often leads to superficial and erroneous recommendations. Motivated by this, we propose ThinkRec, a thinking-based framework that shifts LLM4Rec from System 1 to System 2 (rational system). Technically, ThinkRec introduces a thinking activation mechanism that augments item metadata with keyword summarization and injects synthetic reasoning traces, guiding the model to form interpretable reasoning chains that consist of analyzing interaction histories, identifying user preferences, and making decisions based on target items. On top of this, we propose an instance-wise expert fusion mechanism to reduce the reasoning difficulty. By dynamically assigning weights to expert models based on users' latent features, ThinkRec adapts its reasoning path to individual users, thereby enhancing precision and personalization. Extensive experiments on real-world datasets demonstrate that ThinkRec significantly improves the accuracy and interpretability of recommendations. Our implementations are available in anonymous Github: https://anonymous.4open.science/r/ThinkRec_LLM.