 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccKV: Towards Efficient Audio-Video LLMs Inference via Adaptive-Focusing and Cross-Calibration KV Cache Optimization
Nov 14, 2025

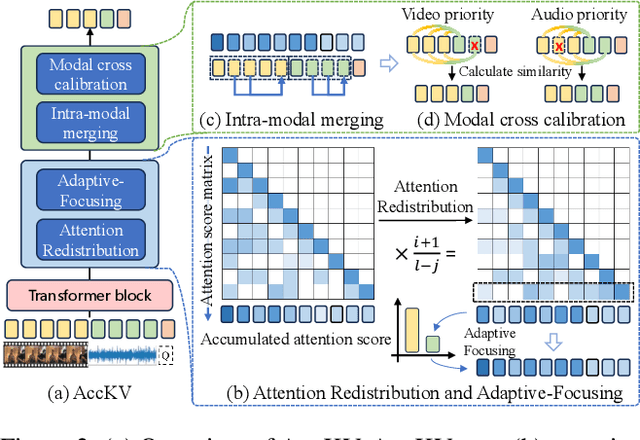

Recent advancements in Audio-Video Large Language Models (AV-LLMs) have enhanced their capabilities in tasks like audio-visual question answering and multimodal dialog systems. Video and audio introduce an extended temporal dimension, resulting in a larger key-value (KV) cache compared to static image embedding. A naive optimization strategy is to selectively focus on and retain KV caches of audio or video based on task. However, in the experiment, we observed that the attention of AV-LLMs to various modalities in the high layers is not strictly dependent on the task. In higher layers, the attention of AV-LLMs shifts more towards the video modality. In addition, we also found that directly integrating temporal KV of audio and spatial-temporal KV of video may lead to information confusion and significant performance degradation of AV-LLMs. If audio and video are processed indiscriminately, it may also lead to excessive compression or reservation of a certain modality, thereby disrupting the alignment between modalities. To address these challenges, we propose AccKV, an Adaptive-Focusing and Cross-Calibration KV cache optimization framework designed specifically for efficient AV-LLMs inference. Our method is based on layer adaptive focusing technology, selectively focusing on key modalities according to the characteristics of different layers, and enhances the recognition of heavy hitter tokens through attention redistribution. In addition, we propose a Cross-Calibration technique that first integrates inefficient KV caches within the audio and video modalities, and then aligns low-priority modalities with high-priority modalities to selectively evict KV cache of low-priority modalities. The experimental results show that AccKV can significantly improve the computational efficiency of AV-LLMs while maintaining accuracy.
Collaborative Representation Learning for Alignment of Tactile, Language, and Vision Modalities
Nov 14, 2025Tactile sensing offers rich and complementary information to vision and language, enabling robots to perceive fine-grained object properties. However, existing tactile sensors lack standardization, leading to redundant features that hinder cross-sensor generalization. Moreover, existing methods fail to fully integrate the intermediate communication among tactile, language, and vision modalities. To address this, we propose TLV-CoRe, a CLIP-based Tactile-Language-Vision Collaborative Representation learning method. TLV-CoRe introduces a Sensor-Aware Modulator to unify tactile features across different sensors and employs tactile-irrelevant decoupled learning to disentangle irrelevant tactile features. Additionally, a Unified Bridging Adapter is introduced to enhance tri-modal interaction within the shared representation space. To fairly evaluate the effectiveness of tactile models, we further propose the RSS evaluation framework, focusing on Robustness, Synergy, and Stability across different methods. Experimental results demonstrate that TLV-CoRe significantly improves sensor-agnostic representation learning and cross-modal alignment, offering a new direction for multimodal tactile representation.
Cuff-KT: Tackling Learners' Real-time Learning Pattern Adjustment via Tuning-Free Knowledge State Guided Model Updating
May 26, 2025



Knowledge Tracing (KT) is a core component of Intelligent Tutoring Systems, modeling learners' knowledge state to predict future performance and provide personalized learning support. Traditional KT models assume that learners' learning abilities remain relatively stable over short periods or change in predictable ways based on prior performance. However, in reality, learners' abilities change irregularly due to factors like cognitive fatigue, motivation, and external stress -- a task introduced, which we refer to as Real-time Learning Pattern Adjustment (RLPA). Existing KT models, when faced with RLPA, lack sufficient adaptability, because they fail to timely account for the dynamic nature of different learners' evolving learning patterns. Current strategies for enhancing adaptability rely on retraining, which leads to significant overfitting and high time overhead issues. To address this, we propose Cuff-KT, comprising a controller and a generator. The controller assigns value scores to learners, while the generator generates personalized parameters for selected learners. Cuff-KT controllably adapts to data changes fast and flexibly without fine-tuning. Experiments on five datasets from different subjects demonstrate that Cuff-KT significantly improves the performance of five KT models with different structures under intra- and inter-learner shifts, with an average relative increase in AUC of 10% and 4%, respectively, at a negligible time cost, effectively tackling RLPA task. Our code and datasets are fully available at https://github.com/zyy-2001/Cuff-KT.
CoLA: Collaborative Low-Rank Adaptation
May 21, 2025The scaling law of Large Language Models (LLMs) reveals a power-law relationship, showing diminishing return on performance as model scale increases. While training LLMs from scratch is resource-intensive, fine-tuning a pre-trained model for specific tasks has become a practical alternative. Full fine-tuning (FFT) achieves strong performance; however, it is computationally expensive and inefficient. Parameter-efficient fine-tuning (PEFT) methods, like LoRA, have been proposed to address these challenges by freezing the pre-trained model and adding lightweight task-specific modules. LoRA, in particular, has proven effective, but its application to multi-task scenarios is limited by interference between tasks. Recent approaches, such as Mixture-of-Experts (MOE) and asymmetric LoRA, have aimed to mitigate these issues but still struggle with sample scarcity and noise interference due to their fixed structure. In response, we propose CoLA, a more flexible LoRA architecture with an efficient initialization scheme, and introduces three collaborative strategies to enhance performance by better utilizing the quantitative relationships between matrices $A$ and $B$. Our experiments demonstrate the effectiveness and robustness of CoLA, outperforming existing PEFT methods, especially in low-sample scenarios. Our data and code are fully publicly available at https://github.com/zyy-2001/CoLA.
Enhancing Security and Strengthening Defenses in Automated Short-Answer Grading Systems
Apr 30, 2025This study examines vulnerabilities in transformer-based automated short-answer grading systems used in medical education, with a focus on how these systems can be manipulated through adversarial gaming strategies. Our research identifies three main types of gaming strategies that exploit the system's weaknesses, potentially leading to false positives. To counteract these vulnerabilities, we implement several adversarial training methods designed to enhance the systems' robustness. Our results indicate that these methods significantly reduce the susceptibility of grading systems to such manipulations, especially when combined with ensemble techniques like majority voting and ridge regression, which further improve the system's defense against sophisticated adversarial inputs. Additionally, employing large language models such as GPT-4 with varied prompting techniques has shown promise in recognizing and scoring gaming strategies effectively. The findings underscore the importance of continuous improvements in AI-driven educational tools to ensure their reliability and fairness in high-stakes settings.
Disentangled Knowledge Tracing for Alleviating Cognitive Bias
Mar 04, 2025In the realm of Intelligent Tutoring System (ITS), the accurate assessment of students' knowledge states through Knowledge Tracing (KT) is crucial for personalized learning. However, due to data bias, $\textit{i.e.}$, the unbalanced distribution of question groups ($\textit{e.g.}$, concepts), conventional KT models are plagued by cognitive bias, which tends to result in cognitive underload for overperformers and cognitive overload for underperformers. More seriously, this bias is amplified with the exercise recommendations by ITS. After delving into the causal relations in the KT models, we identify the main cause as the confounder effect of students' historical correct rate distribution over question groups on the student representation and prediction score. Towards this end, we propose a Disentangled Knowledge Tracing (DisKT) model, which separately models students' familiar and unfamiliar abilities based on causal effects and eliminates the impact of the confounder in student representation within the model. Additionally, to shield the contradictory psychology ($\textit{e.g.}$, guessing and mistaking) in the students' biased data, DisKT introduces a contradiction attention mechanism. Furthermore, DisKT enhances the interpretability of the model predictions by integrating a variant of Item Response Theory. Experimental results on 11 benchmarks and 3 synthesized datasets with different bias strengths demonstrate that DisKT significantly alleviates cognitive bias and outperforms 16 baselines in evaluation accuracy.
Revisiting Applicable and Comprehensive Knowledge Tracing in Large-Scale Data
Jan 24, 2025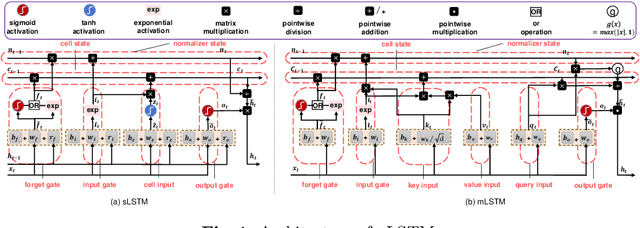

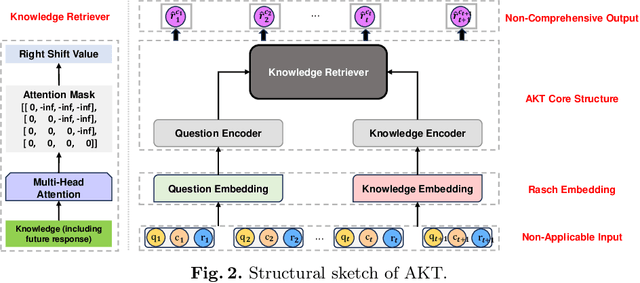
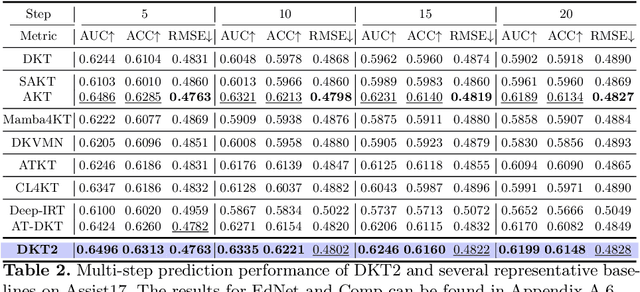
Knowledge Tracing (KT) is a fundamental component of Intelligent Tutoring Systems (ITS), enabling the modeling of students' knowledge states to predict future performance. The introduction of Deep Knowledge Tracing (DKT), the first deep learning-based KT (DLKT) model, has brought significant advantages in terms of applicability and comprehensiveness. However, recent DLKT models, such as Attentive Knowledge Tracing (AKT), have often prioritized predictive performance at the expense of these benefits. While deep sequential models like DKT have shown potential, they face challenges related to parallel computing, storage decision modification, and limited storage capacity. To address these limitations, we propose DKT2, a novel KT model that leverages the recently developed xLSTM architecture. DKT2 enhances input representation using the Rasch model and incorporates Item Response Theory (IRT) for interpretability, allowing for the decomposition of learned knowledge into familiar and unfamiliar knowledge. By integrating this knowledge with predicted questions, DKT2 generates comprehensive knowledge states. Extensive experiments conducted across three large-scale datasets demonstrate that DKT2 consistently outperforms 17 baseline models in various prediction tasks, underscoring its potential for real-world educational applications. This work bridges the gap between theoretical advancements and practical implementation in KT.Our code and datasets will be available at https://github.com/codebase-2025/DKT2.