 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grained Vision-Language Alignment for Domain Generalized Person Re-Identification
Mar 14, 2026Domain Generalized person Re-identification (DG Re-ID) is a challenging task, where models are trained on source domains but tested on unseen target domains. Although previous pure vision-based models have achieved significant progress, the performance remains further improved. Recently, Vision-Language Models (VLMs) present outstanding generalization capabilities in various visual applications. However, directly adapting a VLM to Re-ID shows limited generalization improvement. This is because the VLM only produces with global features that are insensitive to ID nuances. To tacle this problem, we propose a CLIP-based multi-grained vision-language alignment framework in this work. Specifically, several multi-grained prompts are introduced in language modality to describe different body parts and align with their counterparts in vision modality. To obtain fine-grained visual information, an adaptively masked multi-head self-attention module is employed to precisely extract specific part features. To train the proposed module, an MLLM-based visual grounding expert is employed to automatically generate pseudo labels of body parts for supervision. Extensive experiments conducted on both single- and multi-source generalization protocols demonstrate the superior performance of our approach. The implementation code will be released at https://github.com/RikoLi/MUVA.
Calibrating Uncertainty for Zero-Shot Adversarial CLIP
Dec 15, 2025CLIP delivers strong zero-shot classification but remains highly vulnerable to adversarial attacks. Previous work of adversarial fine-tuning largely focuses on matching the predicted logits between clean and adversarial examples, which overlooks uncertainty calibration and may degrade the zero-shot generalization. A common expectation in reliable uncertainty estimation is that predictive uncertainty should increase as inputs become more difficult or shift away from the training distribution. However, we frequently observe the opposite in the adversarial setting: perturbations not only degrade accuracy but also suppress uncertainty, leading to severe miscalibration and unreliable over-confidence. This overlooked phenomenon highlights a critical reliability gap beyond robustness. To bridge this gap, we propose a novel adversarial fine-tuning objective for CLIP considering both prediction accuracy and uncertainty alignments. By reparameterizing the output of CLIP as the concentration parameter of a Dirichlet distribution, we propose a unified representation that captures relative semantic structure and the magnitude of predictive confidence. Our objective aligns these distributions holistically under perturbations, moving beyond single-logit anchoring and restoring calibrated uncertainty. Experiments on multiple zero-shot classification benchmarks demonstrate that our approach effectively restores calibrated uncertainty and achieves competitive adversarial robustness while maintaining clean accuracy.
MoA: Heterogeneous Mixture of Adapters for Parameter-Efficient Fine-Tuning of Large Language Models
Jun 06, 2025Recent studies integrate Low-Rank Adaptation (LoRA) and Mixture-of-Experts (MoE) to further enhance the performance of parameter-efficient fine-tuning (PEFT) methods in Large Language Model (LLM) applications. Existing methods employ \emph{homogeneous} MoE-LoRA architectures composed of LoRA experts with either similar or identical structures and capacities. However, these approaches often suffer from representation collapse and expert load imbalance, which negatively impact the potential of LLMs. To address these challenges, we propose a \emph{heterogeneous} \textbf{Mixture-of-Adapters (MoA)} approach. This method dynamically integrates PEFT adapter experts with diverse structures, leveraging their complementary representational capabilities to foster expert specialization, thereby enhancing the effective transfer of pre-trained knowledge to downstream tasks. MoA supports two variants: \textbf{(i)} \textit{Soft MoA} achieves fine-grained integration by performing a weighted fusion of all expert outputs; \textbf{(ii)} \textit{Sparse MoA} activates adapter experts sparsely based on their contribution, achieving this with negligible performance degradation. Experimental results demonstrate that heterogeneous MoA outperforms homogeneous MoE-LoRA methods in both performance and parameter efficiency. Our project is available at https://github.com/DCDmllm/MoA.
MAKIMA: Tuning-free Multi-Attribute Open-domain Video Editing via Mask-Guided Attention Modulation
Dec 28, 2024



Diffusion-based text-to-image (T2I) models have demonstrated remarkable results in global video editing tasks. However, their focus is primarily on global video modifications, and achieving desired attribute-specific changes remains a challenging task, specifically in multi-attribute editing (MAE) in video. Contemporary video editing approaches either require extensive fine-tuning or rely on additional networks (such as ControlNet) for modeling multi-object appearances, yet they remain in their infancy, offering only coarse-grained MAE solutions. In this paper, we present MAKIMA, a tuning-free MAE framework built upon pretrained T2I models for open-domain video editing. Our approach preserves video structure and appearance information by incorporating attention maps and features from the inversion process during denoising. To facilitate precise editing of multiple attributes, we introduce mask-guided attention modulation, enhancing correlations between spatially corresponding tokens and suppressing cross-attribute interference in both self-attention and cross-attention layers. To balance video frame generation quality and efficiency, we implement consistent feature propagation, which generates frame sequences by editing keyframes and propagating their features throughout the sequence. Extensive experiments demonstrate that MAKIMA outperforms existing baselines in open-domain multi-attribute video editing tasks, achieving superior results in both editing accuracy and temporal consistency while maintaining computational efficiency.
Boundary feature fusion network for tooth image segmentation
Sep 06, 2024



Tooth segmentation is a critical technology in the field of medical image segmentation, with applications ranging from orthodontic treatment to human body identification and dental pathology assessment. Despite the development of numerous tooth image segmentation models by researchers, a common shortcoming is the failure to account for the challenges of blurred tooth boundaries. Dental diagnostics require precise delineation of tooth boundaries. This paper introduces an innovative tooth segmentation network that integrates boundary information to address the issue of indistinct boundaries between teeth and adjacent tissues. This network's core is its boundary feature extraction module, which is designed to extract detailed boundary information from high-level features. Concurrently, the feature cross-fusion module merges detailed boundary and global semantic information in a synergistic way, allowing for stepwise layer transfer of feature information. This method results in precise tooth segmentation. In the most recent STS Data Challenge, our methodology was rigorously tested and received a commendable overall score of 0.91. When compared to other existing approaches, this score demonstrates our method's significant superiority in segmenting tooth boundaries.
Evaluating the Utility of Conformal Prediction Sets for AI-Advised Image Labeling
Jan 30, 2024



As deep neural networks are more commonly deployed in high-stakes domains, their lack of interpretability makes uncertainty quantification challenging. We investigate the effects of presenting conformal prediction sets$\unicode{x2013}$a method for generating valid confidence sets in distribution-free uncertainty quantification$\unicode{x2013}$to express uncertainty in AI-advised decision-making. Through a large online experiment, we compare the utility of conformal prediction sets to displays of Top-$1$ and Top-$k$ predictions for AI-advised image labeling. We find that the utility of prediction sets for accuracy varies with the difficulty of the task: while they result in accuracy on par with or less than Top-$1$ and Top-$k$ displays for easy images, prediction sets excel at assisting humans in labeling out-of-distribution (OOD) images especially when the set size is small. Our results empirically pinpoint the practical challenges of conformal prediction sets and provide implications on how to incorporate them for real-world decision-making.
A positive feedback method based on F-measure value for Salient Object Detection
Apr 28, 2023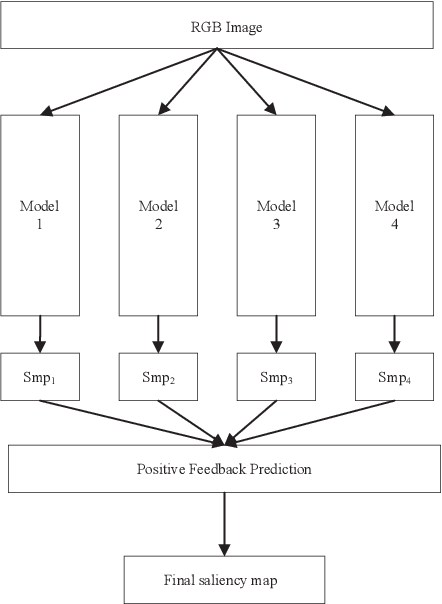


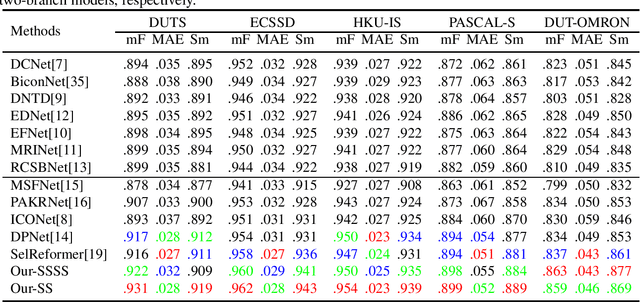
The majority of current salient object detection (SOD) models are focused on designing a series of decoders based on fully convolutional networks (FCNs) or Transformer architectures and integrating them in a skillful manner. These models have achieved remarkable high performance and made significant contributions to the development of SOD. Their primary research objective is to develop novel algorithms that can outperform state-of-the-art models, a task that is extremely difficult and time-consuming. In contrast, this paper proposes a positive feedback method based on F-measure value for SOD, aiming to improve the accuracy of saliency prediction using existing methods. Specifically, our proposed method takes an image to be detected and inputs it into several existing models to obtain their respective prediction maps. These prediction maps are then fed into our positive feedback method to generate the final prediction result, without the need for careful decoder design or model training. Moreover, our method is adaptive and can be implemented based on existing models without any restrictions. Experimental results on five publicly available datasets show that our proposed positive feedback method outperforms the latest 12 methods in five evaluation metrics for saliency map prediction. Additionally, we conducted a robustness experiment, which shows that when at least one good prediction result exists in the selected existing model, our proposed approach can ensure that the prediction result is not worse. Our approach achieves a prediction speed of 20 frames per second (FPS) when evaluated on a low configuration host and after removing the prediction time overhead of inserted models. These results highlight the effectiveness, efficiency, and robustness of our proposed approach for salient object detection.