 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMMs Meet Object-Centric Vision: Understanding, Segmentation, Editing and Generation
Apr 13, 2026Large Multimodal Models (LMMs) have achieved remarkable progress in general-purpose vision--language understanding, yet they remain limited in tasks requiring precise object-level grounding, fine-grained spatial reasoning, and controllable visual manipulation. In particular, existing systems often struggle to identify the correct instance, preserve object identity across interactions, and localize or modify designated regions with high precision. Object-centric vision provides a principled framework for addressing these challenges by promoting explicit representations and operations over visual entities, thereby extending multimodal systems from global scene understanding to object-level understanding, segmentation, editing, and generation. This paper presents a comprehensive review of recent advances at the convergence of LMMs and object-centric vision. We organize the literature into four major themes: object-centric visual understanding, object-centric referring segmentation, object-centric visual editing, and object-centric visual generation. We further summarize the key modeling paradigms, learning strategies, and evaluation protocols that support these capabilities. Finally, we discuss open challenges and future directions, including robust instance permanence, fine-grained spatial control, consistent multi-step interaction, unified cross-task modeling, and reliable benchmarking under distribution shift. We hope this paper provides a structured perspective on the development of scalable, precise, and trustworthy object-centric multimodal systems.
MAU-GPT: Enhancing Multi-type Industrial Anomaly Understanding via Anomaly-aware and Generalist Experts Adaptation
Jan 31, 2026As industrial manufacturing scales, automating fine-grained product image analysis has become critical for quality control. However, existing approaches are hindered by limited dataset coverage and poor model generalization across diverse and complex anomaly patterns. To address these challenges, we introduce MAU-Set, a comprehensive dataset for Multi-type industrial Anomaly Understanding. It spans multiple industrial domains and features a hierarchical task structure, ranging from binary classification to complex reasoning. Alongside this dataset, we establish a rigorous evaluation protocol to facilitate fair and comprehensive model assessment. Building upon this foundation, we further present MAU-GPT, a domain-adapted multimodal large model specifically designed for industrial anomaly understanding. It incorporates a novel AMoE-LoRA mechanism that unifies anomaly-aware and generalist experts adaptation, enhancing both understanding and reasoning across diverse defect classes. Extensive experiments show that MAU-GPT consistently outperforms prior state-of-the-art methods across all domains, demonstrating strong potential for scalable and automated industrial inspection.
Unified Personalized Understanding, Generating and Editing
Jan 11, 2026Unified large multimodal models (LMMs) have achieved remarkable progress in general-purpose multimodal understanding and generation. However, they still operate under a ``one-size-fits-all'' paradigm and struggle to model user-specific concepts (e.g., generate a photo of \texttt{<maeve>}) in a consistent and controllable manner. Existing personalization methods typically rely on external retrieval, which is inefficient and poorly integrated into unified multimodal pipelines. Recent personalized unified models introduce learnable soft prompts to encode concept information, yet they either couple understanding and generation or depend on complex multi-stage training, leading to cross-task interference and ultimately to fuzzy or misaligned personalized knowledge. We present \textbf{OmniPersona}, an end-to-end personalization framework for unified LMMs that, for the first time, integrates personalized understanding, generation, and image editing within a single architecture. OmniPersona introduces structurally decoupled concept tokens, allocating dedicated subspaces for different tasks to minimize interference, and incorporates an explicit knowledge replay mechanism that propagates personalized attribute knowledge across tasks, enabling consistent personalized behavior. To systematically evaluate unified personalization, we propose \textbf{\texttt{OmniPBench}}, extending the public UnifyBench concept set with personalized editing tasks and cross-task evaluation protocols integrating understanding, generation, and editing. Experimental results demonstrate that OmniPersona delivers competitive and robust performance across diverse personalization tasks. We hope OmniPersona will serve as a strong baseline and spur further research on controllable, unified personalization.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Run, Ruminate, and Regulate: A Dual-process Thinking System for Vision-and-Language Navigation
Nov 18, 2025Vision-and-Language Navigation (VLN) requires an agent to dynamically explore complex 3D environments following human instructions. Recent research underscores the potential of harnessing large language models (LLMs) for VLN, given their commonsense knowledge and general reasoning capabilities. Despite their strengths, a substantial gap in task completion performance persists between LLM-based approaches and domain experts, as LLMs inherently struggle to comprehend real-world spatial correlations precisely. Additionally, introducing LLMs is accompanied with substantial computational cost and inference latency. To address these issues, we propose a novel dual-process thinking framework dubbed R3, integrating LLMs' generalization capabilities with VLN-specific expertise in a zero-shot manner. The framework comprises three core modules: Runner, Ruminator, and Regulator. The Runner is a lightweight transformer-based expert model that ensures efficient and accurate navigation under regular circumstances. The Ruminator employs a powerful multimodal LLM as the backbone and adopts chain-of-thought (CoT) prompting to elicit structured reasoning. The Regulator monitors the navigation progress and controls the appropriate thinking mode according to three criteria, integrating Runner and Ruminator harmoniously. Experimental results illustrate that R3 significantly outperforms other state-of-the-art methods, exceeding 3.28% and 3.30% in SPL and RGSPL respectively on the REVERIE benchmark. This pronounced enhancement highlights the effectiveness of our method in handling challenging VLN tasks.
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .
MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance
Mar 19, 2025

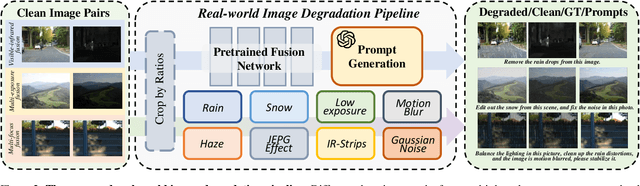
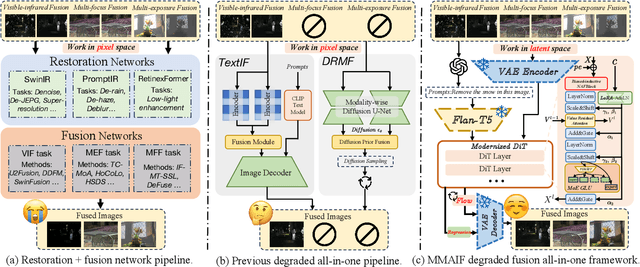
Image fusion, a fundamental low-level vision task, aims to integrate multiple image sequences into a single output while preserving as much information as possible from the input. However, existing methods face several significant limitations: 1) requiring task- or dataset-specific models; 2) neglecting real-world image degradations (\textit{e.g.}, noise), which causes failure when processing degraded inputs; 3) operating in pixel space, where attention mechanisms are computationally expensive; and 4) lacking user interaction capabilities. To address these challenges, we propose a unified framework for multi-task, multi-degradation, and language-guided image fusion. Our framework includes two key components: 1) a practical degradation pipeline that simulates real-world image degradations and generates interactive prompts to guide the model; 2) an all-in-one Diffusion Transformer (DiT) operating in latent space, which fuses a clean image conditioned on both the degraded inputs and the generated prompts. Furthermore, we introduce principled modifications to the original DiT architecture to better suit the fusion task. Based on this framework, we develop two versions of the model: Regression-based and Flow Matching-based variants. Extensive qualitative and quantitative experiments demonstrate that our approach effectively addresses the aforementioned limitations and outperforms previous restoration+fusion and all-in-one pipelines. Codes are available at https://github.com/294coder/MMAIF.
Taming Flow Matching with Unbalanced Optimal Transport into Fast Pansharpening
Mar 19, 2025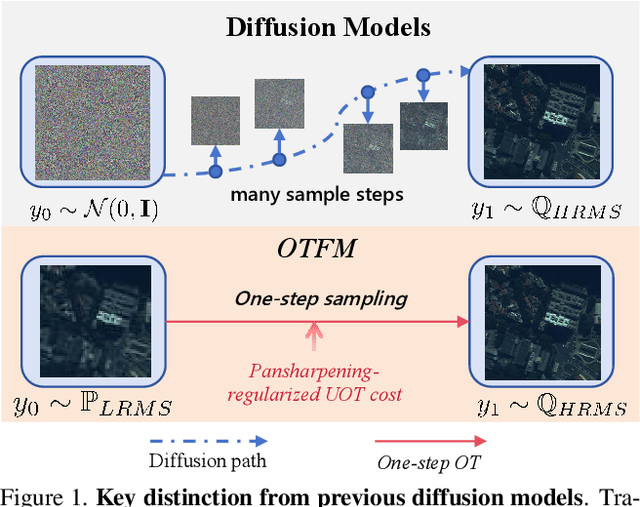
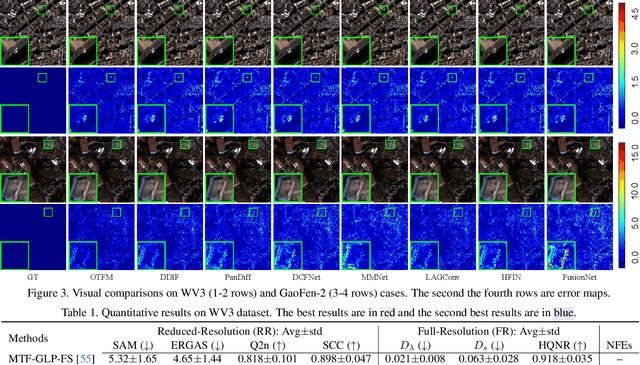
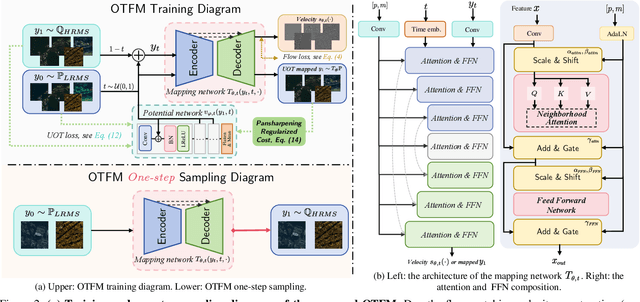
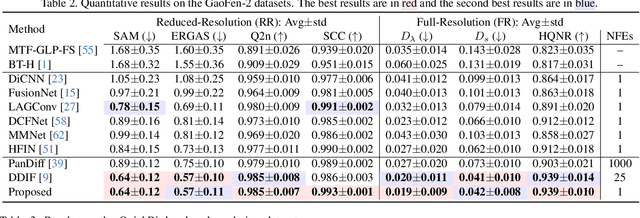
Pansharpening, a pivotal task in remote sensing for fusing high-resolution panchromatic and multispectral imagery, has garnered significant research interest. Recent advancements employing diffusion models based on stochastic differential equations (SDEs) have demonstrated state-of-the-art performance. However, the inherent multi-step sampling process of SDEs imposes substantial computational overhead, hindering practical deployment. While existing methods adopt efficient samplers, knowledge distillation, or retraining to reduce sampling steps (e.g., from 1,000 to fewer steps), such approaches often compromise fusion quality. In this work, we propose the Optimal Transport Flow Matching (OTFM) framework, which integrates the dual formulation of unbalanced optimal transport (UOT) to achieve one-step, high-quality pansharpening. Unlike conventional OT formulations that enforce rigid distribution alignment, UOT relaxes marginal constraints to enhance modeling flexibility, accommodating the intrinsic spectral and spatial disparities in remote sensing data. Furthermore, we incorporate task-specific regularization into the UOT objective, enhancing the robustness of the flow model. The OTFM framework enables simulation-free training and single-step inference while maintaining strict adherence to pansharpening constraints. Experimental evaluations across multiple datasets demonstrate that OTFM matches or exceeds the performance of previous regression-based models and leading diffusion-based methods while only needing one sampling step. Codes are available at https://github.com/294coder/PAN-OTFM.
MAKIMA: Tuning-free Multi-Attribute Open-domain Video Editing via Mask-Guided Attention Modulation
Dec 28, 2024



Diffusion-based text-to-image (T2I) models have demonstrated remarkable results in global video editing tasks. However, their focus is primarily on global video modifications, and achieving desired attribute-specific changes remains a challenging task, specifically in multi-attribute editing (MAE) in video. Contemporary video editing approaches either require extensive fine-tuning or rely on additional networks (such as ControlNet) for modeling multi-object appearances, yet they remain in their infancy, offering only coarse-grained MAE solutions. In this paper, we present MAKIMA, a tuning-free MAE framework built upon pretrained T2I models for open-domain video editing. Our approach preserves video structure and appearance information by incorporating attention maps and features from the inversion process during denoising. To facilitate precise editing of multiple attributes, we introduce mask-guided attention modulation, enhancing correlations between spatially corresponding tokens and suppressing cross-attribute interference in both self-attention and cross-attention layers. To balance video frame generation quality and efficiency, we implement consistent feature propagation, which generates frame sequences by editing keyframes and propagating their features throughout the sequence. Extensive experiments demonstrate that MAKIMA outperforms existing baselines in open-domain multi-attribute video editing tasks, achieving superior results in both editing accuracy and temporal consistency while maintaining computational efficiency.
A Decade of Deep Learning: A Survey on The Magnificent Seven
Dec 13, 2024Deep learning has fundamentally reshaped the landscape of artificial intelligence over the past decade, enabling remarkable achievements across diverse domains. At the heart of these developments lie multi-layered neural network architectures that excel at automatic feature extraction, leading to significant improvements in machine learning tasks. To demystify these advances and offer accessible guidance, we present a comprehensive overview of the most influential deep learning algorithms selected through a broad-based survey of the field. Our discussion centers on pivotal architectures, including Residual Networks, Transformers, Generative Adversarial Networks, Variational Autoencoders, Graph Neural Networks, Contrastive Language-Image Pre-training, and Diffusion models. We detail their historical context, highlight their mathematical foundations and algorithmic principles, and examine subsequent variants, extensions, and practical considerations such as training methodologies, normalization techniques, and learning rate schedules. Beyond historical and technical insights, we also address their applications, challenges, and potential research directions. This survey aims to serve as a practical manual for both newcomers seeking an entry point into cutting-edge deep learning methods and experienced researchers transitioning into this rapidly evolving domain.