 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Aug 10, 2025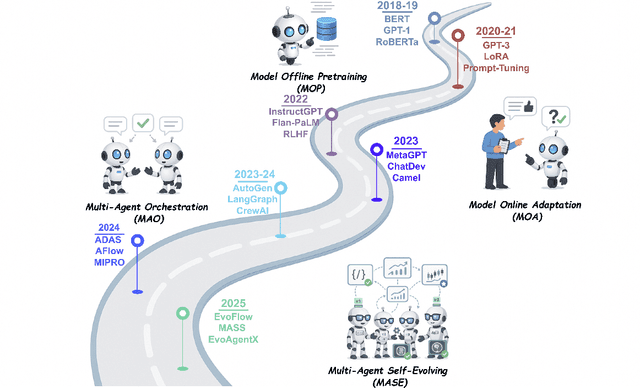
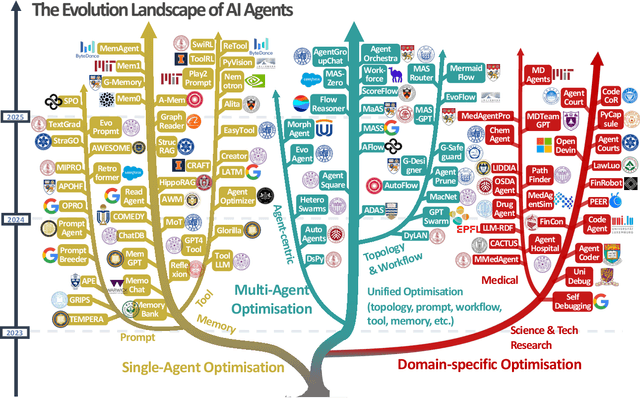
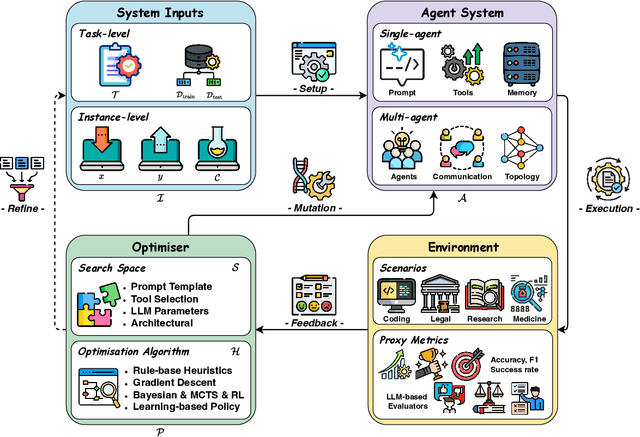
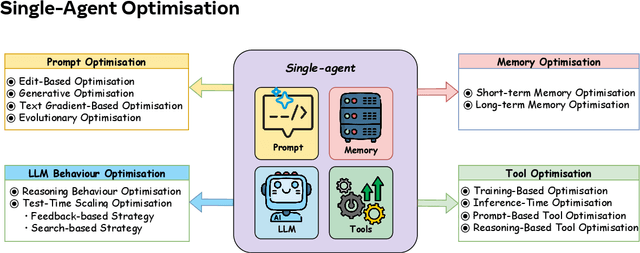
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.
Dynamically Adaptive Reasoning via LLM-Guided MCTS for Efficient and Context-Aware KGQA
Aug 01, 2025
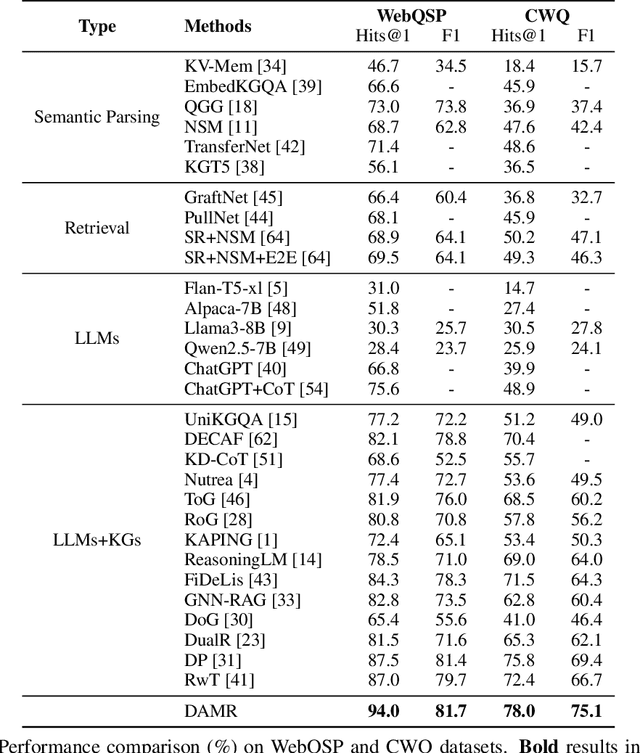


Knowledge Graph Question Answering (KGQA) aims to interpret natural language queries and perform structured reasoning over knowledge graphs by leveraging their relational and semantic structures to retrieve accurate answers. Recent KGQA methods primarily follow either retrieve-then-reason paradigm, relying on GNNs or heuristic rules for static paths extraction, or dynamic path generation strategies that use large language models (LLMs) with prompting to jointly perform retrieval and reasoning. However, the former suffers from limited adaptability due to static path extraction and lack of contextual refinement, while the latter incurs high computational costs and struggles with accurate path evaluation due to reliance on fixed scoring functions and extensive LLM calls. To address these issues, this paper proposes Dynamically Adaptive MCTS-based Reasoning (DAMR), a novel framework that integrates symbolic search with adaptive path evaluation for efficient and context-aware KGQA. DAMR employs a Monte Carlo Tree Search (MCTS) backbone guided by an LLM-based planner, which selects top-$k$ relevant relations at each step to reduce search space. To improve path evaluation accuracy, we introduce a lightweight Transformer-based scorer that performs context-aware plausibility estimation by jointly encoding the question and relation sequence through cross-attention, enabling the model to capture fine-grained semantic shifts during multi-hop reasoning. Furthermore, to alleviate the scarcity of high-quality supervision, DAMR incorporates a dynamic pseudo-path refinement mechanism that periodically generates training signals from partial paths explored during search, allowing the scorer to continuously adapt to the evolving distribution of reasoning trajectories. Extensive experiments on multiple KGQA benchmarks show that DAMR significantly outperforms state-of-the-art methods.
SEW: Self-Evolving Agentic Workflows for Automated Code Generation
May 24, 2025Large Language Models (LLMs) have demonstrated effectiveness in code generation tasks. To enable LLMs to address more complex coding challenges, existing research has focused on crafting multi-agent systems with agentic workflows, where complex coding tasks are decomposed into sub-tasks, assigned to specialized agents. Despite their effectiveness, current approaches heavily rely on hand-crafted agentic workflows, with both agent topologies and prompts manually designed, which limits their ability to automatically adapt to different types of coding problems. To address these limitations and enable automated workflow design, we propose \textbf{S}elf-\textbf{E}volving \textbf{W}orkflow (\textbf{SEW}), a novel self-evolving framework that automatically generates and optimises multi-agent workflows. Extensive experiments on three coding benchmark datasets, including the challenging LiveCodeBench, demonstrate that our SEW can automatically design agentic workflows and optimise them through self-evolution, bringing up to 33\% improvement on LiveCodeBench compared to using the backbone LLM only. Furthermore, by investigating different representation schemes of workflow, we provide insights into the optimal way to encode workflow information with text.
REOBench: Benchmarking Robustness of Earth Observation Foundation Models
May 22, 2025Earth observation foundation models have shown strong generalization across multiple Earth observation tasks, but their robustness under real-world perturbations remains underexplored. To bridge this gap, we introduce REOBench, the first comprehensive benchmark for evaluating the robustness of Earth observation foundation models across six tasks and twelve types of image corruptions, including both appearance-based and geometric perturbations. To ensure realistic and fine-grained evaluation, our benchmark focuses on high-resolution optical remote sensing images, which are widely used in critical applications such as urban planning and disaster response. We conduct a systematic evaluation of a broad range of models trained using masked image modeling, contrastive learning, and vision-language pre-training paradigms. Our results reveal that (1) existing Earth observation foundation models experience significant performance degradation when exposed to input corruptions. (2) The severity of degradation varies across tasks, model architectures, backbone sizes, and types of corruption, with performance drop varying from less than 1% to over 20%. (3) Vision-language models show enhanced robustness, particularly in multimodal tasks. REOBench underscores the vulnerability of current Earth observation foundation models to real-world corruptions and provides actionable insights for developing more robust and reliable models.
Three mechanistically different variability and noise sources in the trial-to-trial fluctuations of responses to brain stimulation
Dec 22, 2024



Motor-evoked potentials (MEPs) are among the few directly observable responses to external brain stimulation and serve a variety of applications, often in the form of input-output (IO) curves. Previous statistical models with two variability sources inherently consider the small MEPs at the low-side plateau as part of the neural recruitment properties. However, recent studies demonstrated that small MEP responses under resting conditions are contaminated and over-shadowed by background noise of mostly technical quality, e.g., caused by the amplifier, and suggested that the neural recruitment curve should continue below this noise level. This work intends to separate physiological variability from background noise and improve the description of recruitment behaviour. We developed a triple-variability-source model around a logarithmic logistic function without a lower plateau and incorporated an additional source for background noise. Compared to models with two or fewer variability sources, our approach better described IO characteristics, evidenced by lower Bayesian Information Criterion scores across all subjects and pulse shapes. The model independently extracted hidden variability information across the stimulated neural system and isolated it from background noise, which led to an accurate estimation of the IO curve parameters. This new model offers a robust tool to analyse brain stimulation IO curves in clinical and experimental neuroscience and reduces the risk of spurious results from inappropriate statistical methods. The presented model together with the corresponding calibration method provides a more accurate representation of MEP responses and variability sources, advances our understanding of cortical excitability, and may improve the assessment of neuromodulation effects.
SGAC: A Graph Neural Network Framework for Imbalanced and Structure-Aware AMP Classification
Dec 20, 2024



Classifying antimicrobial peptides(AMPs) from the vast array of peptides mined from metagenomic sequencing data is a significant approach to addressing the issue of antibiotic resistance. However, current AMP classification methods, primarily relying on sequence-based data, neglect the spatial structure of peptides, thereby limiting the accurate classification of AMPs. Additionally, the number of known AMPs is significantly lower than that of non-AMPs, leading to imbalanced datasets that reduce predictive accuracy for AMPs. To alleviate these two limitations, we first employ Omegafold to predict the three-dimensional spatial structures of AMPs and non-AMPs, constructing peptide graphs based on the amino acids' C$_\alpha$ positions. Building upon this, we propose a novel classification model named Spatial GNN-based AMP Classifier (SGAC). Our SGAC model employs a graph encoder based on Graph Neural Networks (GNNs) to process peptide graphs, generating high-dimensional representations that capture essential features from the three-dimensional spatial structure of amino acids. Then, to address the inherent imbalanced datasets, SGAC first incorporates Weight-enhanced Contrastive Learning, which clusters similar peptides while ensuring separation between dissimilar ones, using weighted contributions to emphasize AMP-specific features. Furthermore, SGAC employs Weight-enhanced Pseudo-label Distillation to dynamically generate high-confidence pseudo labels for ambiguous peptides, further refining predictions and promoting balanced learning between AMPs and non-AMPs. Experiments on publicly available AMP and non-AMP datasets demonstrate that SGAC significantly outperforms traditional sequence-based methods and achieves state-of-the-art performance among graph-based models, validating its effectiveness in AMP classification.
On the Structural Memory of LLM Agents
Dec 17, 2024
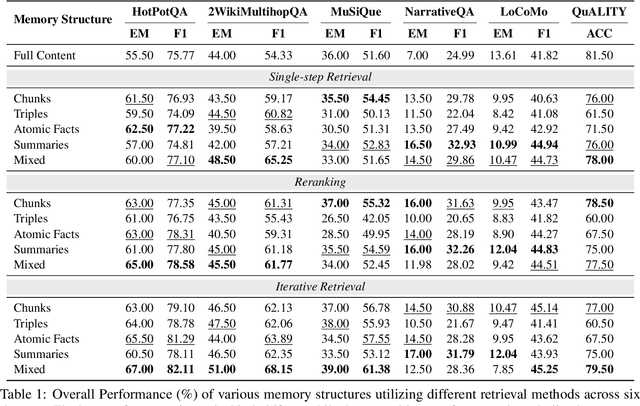


Memory plays a pivotal role in enabling large language model~(LLM)-based agents to engage in complex and long-term interactions, such as question answering (QA) and dialogue systems. While various memory modules have been proposed for these tasks, the impact of different memory structures across tasks remains insufficiently explored. This paper investigates how memory structures and memory retrieval methods affect the performance of LLM-based agents. Specifically, we evaluate four types of memory structures, including chunks, knowledge triples, atomic facts, and summaries, along with mixed memory that combines these components. In addition, we evaluate three widely used memory retrieval methods: single-step retrieval, reranking, and iterative retrieval. Extensive experiments conducted across four tasks and six datasets yield the following key insights: (1) Different memory structures offer distinct advantages, enabling them to be tailored to specific tasks; (2) Mixed memory structures demonstrate remarkable resilience in noisy environments; (3) Iterative retrieval consistently outperforms other methods across various scenarios. Our investigation aims to inspire further research into the design of memory systems for LLM-based agents.
A Decade of Deep Learning: A Survey on The Magnificent Seven
Dec 13, 2024Deep learning has fundamentally reshaped the landscape of artificial intelligence over the past decade, enabling remarkable achievements across diverse domains. At the heart of these developments lie multi-layered neural network architectures that excel at automatic feature extraction, leading to significant improvements in machine learning tasks. To demystify these advances and offer accessible guidance, we present a comprehensive overview of the most influential deep learning algorithms selected through a broad-based survey of the field. Our discussion centers on pivotal architectures, including Residual Networks, Transformers, Generative Adversarial Networks, Variational Autoencoders, Graph Neural Networks, Contrastive Language-Image Pre-training, and Diffusion models. We detail their historical context, highlight their mathematical foundations and algorithmic principles, and examine subsequent variants, extensions, and practical considerations such as training methodologies, normalization techniques, and learning rate schedules. Beyond historical and technical insights, we also address their applications, challenges, and potential research directions. This survey aims to serve as a practical manual for both newcomers seeking an entry point into cutting-edge deep learning methods and experienced researchers transitioning into this rapidly evolving domain.
DuSEGO: Dual Second-order Equivariant Graph Ordinary Differential Equation
Nov 15, 2024
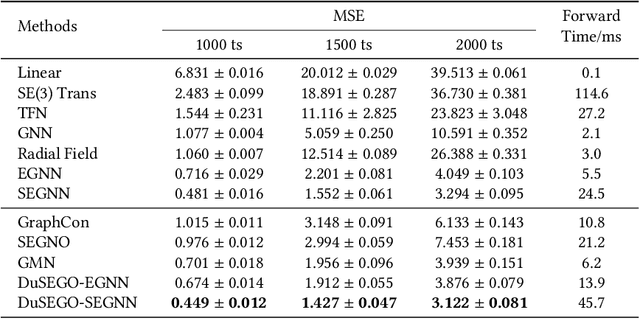
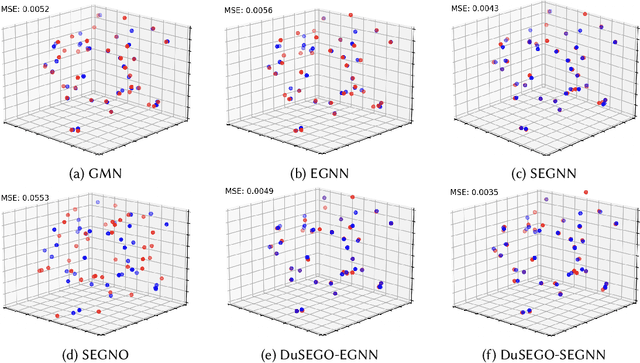
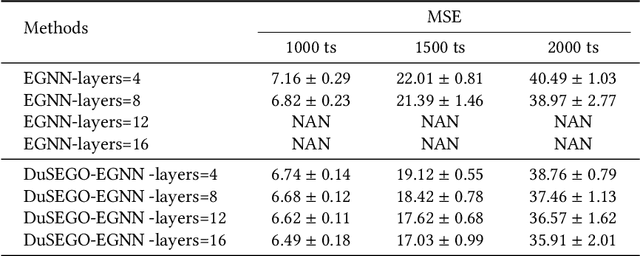
Graph Neural Networks (GNNs) with equivariant properties have achieved significant success in modeling complex dynamic systems and molecular properties. However, their expressiveness ability is limited by: (1) Existing methods often overlook the over-smoothing issue caused by traditional GNN models, as well as the gradient explosion or vanishing problems in deep GNNs. (2) Most models operate on first-order information, neglecting that the real world often consists of second-order systems, which further limits the model's representation capabilities. To address these issues, we propose the \textbf{Du}al \textbf{S}econd-order \textbf{E}quivariant \textbf{G}raph \textbf{O}rdinary Differential Equation (\method{}) for equivariant representation. Specifically, \method{} apply the dual second-order equivariant graph ordinary differential equations (Graph ODEs) on graph embeddings and node coordinates, simultaneously. Theoretically, we first prove that \method{} maintains the equivariant property. Furthermore, we provide theoretical insights showing that \method{} effectively alleviates the over-smoothing problem in both feature representation and coordinate update. Additionally, we demonstrate that the proposed \method{} mitigates the exploding and vanishing gradients problem, facilitating the training of deep multi-layer GNNs. Extensive experiments on benchmark datasets validate the superiority of the proposed \method{} compared to baselines.
Degree Distribution based Spiking Graph Networks for Domain Adaptation
Oct 10, 2024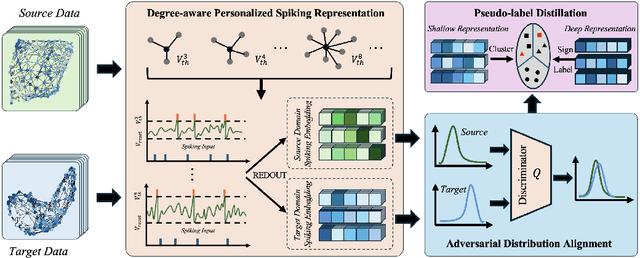
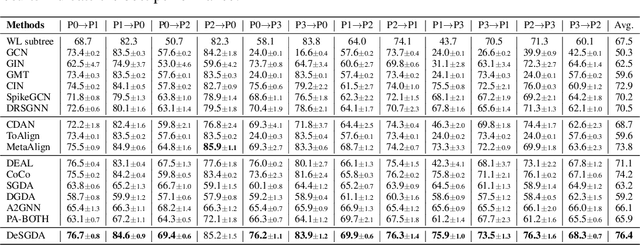

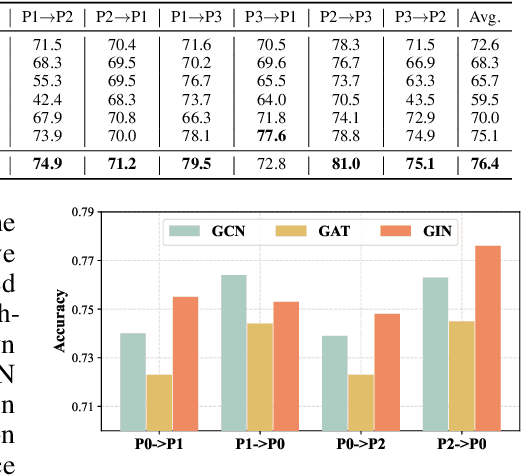
Spiking Graph Networks (SGNs) have garnered significant attraction from both researchers and industry due to their ability to address energy consumption challenges in graph classification. However, SGNs are only effective for in-distribution data and cannot tackle out-of-distribution data. In this paper, we first propose the domain adaptation problem in SGNs, and introduce a novel framework named Degree-aware Spiking Graph Domain Adaptation for Classification. The proposed DeSGDA addresses the spiking graph domain adaptation problem by three aspects: node degree-aware personalized spiking representation, adversarial feature distribution alignment, and pseudo-label distillation. First, we introduce the personalized spiking representation method for generating degree-dependent spiking signals. Specifically, the threshold of triggering a spike is determined by the node degree, allowing this personalized approach to capture more expressive information for classification. Then, we propose the graph feature distribution alignment module that is adversarially trained using membrane potential against a domain discriminator. Such an alignment module can efficiently maintain high performance and low energy consumption in the case of inconsistent distribution. Additionally, we extract consistent predictions across two spaces to create reliable pseudo-labels, effectively leveraging unlabeled data to enhance graph classification performance. Extensive experiments on benchmark datasets validate the superiority of the proposed DeSGDA compared with competitive baselines.