 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCI-DiffCom: Longitudinal Consistency-Informed Diffusion Model for 3D Infant Brain Image Completion
May 17, 2024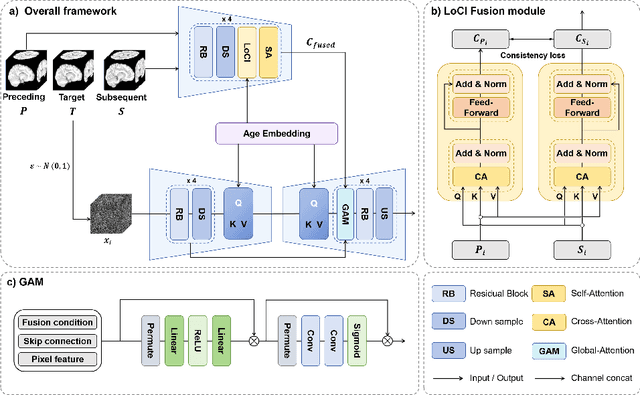
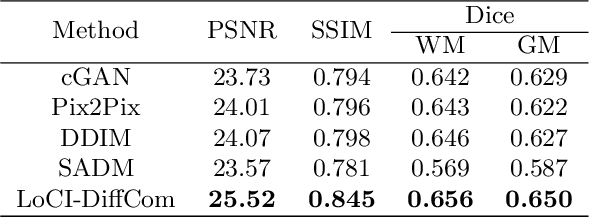
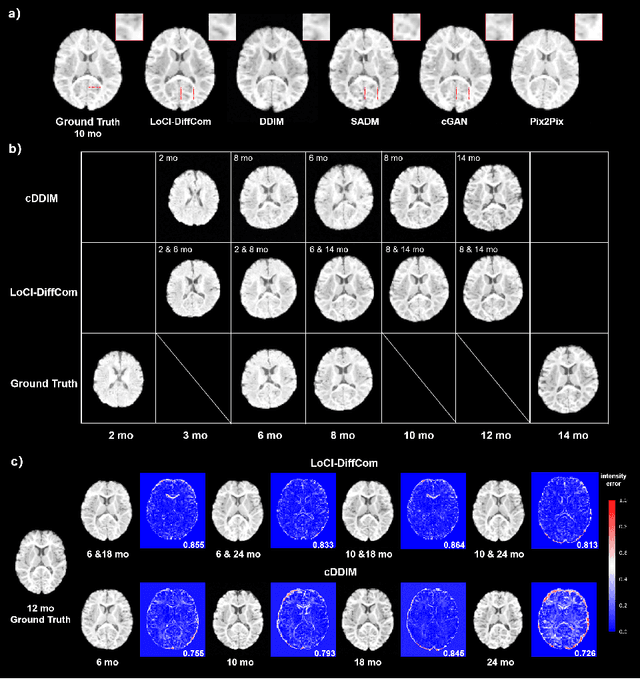
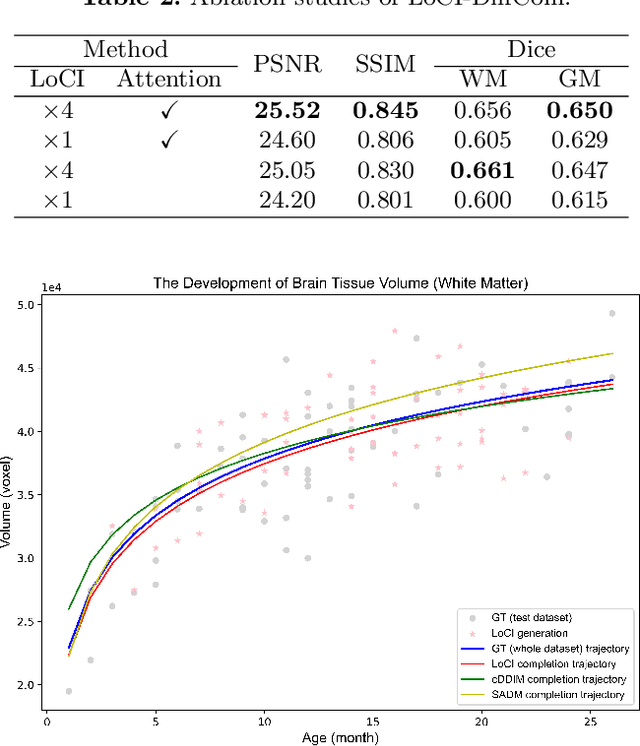
The infant brain undergoes rapid development in the first few years after birth.Compared to cross-sectional studies, longitudinal studies can depict the trajectories of infants brain development with higher accuracy, statistical power and flexibility.However, the collection of infant longitudinal magnetic resonance (MR) data suffers a notorious dropout problem, resulting in incomplete datasets with missing time points. This limitation significantly impedes subsequent neuroscience and clinical modeling. Yet, existing deep generative models are facing difficulties in missing brain image completion, due to sparse data and the nonlinear, dramatic contrast/geometric variations in the developing brain. We propose LoCI-DiffCom, a novel Longitudinal Consistency-Informed Diffusion model for infant brain image Completion,which integrates the images from preceding and subsequent time points to guide a diffusion model for generating high-fidelity missing data. Our designed LoCI module can work on highly sparse sequences, relying solely on data from two temporal points. Despite wide separation and diversity between age time points, our approach can extract individualized developmental features while ensuring context-aware consistency. Our experiments on a large infant brain MR dataset demonstrate its effectiveness with consistent performance on missing infant brain MR completion even in big gap scenarios, aiding in better delineation of early developmental trajectories.
Memory-based Cross-modal Semantic Alignment Network for Radiology Report Generation
Mar 31, 2024Generating radiology reports automatically reduces the workload of radiologists and helps the diagnoses of specific diseases. Many existing methods take this task as modality transfer process. However, since the key information related to disease accounts for a small proportion in both image and report, it is hard for the model to learn the latent relation between the radiology image and its report, thus failing to generate fluent and accurate radiology reports. To tackle this problem, we propose a memory-based cross-modal semantic alignment model (MCSAM) following an encoder-decoder paradigm. MCSAM includes a well initialized long-term clinical memory bank to learn disease-related representations as well as prior knowledge for different modalities to retrieve and use the retrieved memory to perform feature consolidation. To ensure the semantic consistency of the retrieved cross modal prior knowledge, a cross-modal semantic alignment module (SAM) is proposed. SAM is also able to generate semantic visual feature embeddings which can be added to the decoder and benefits report generation. More importantly, to memorize the state and additional information while generating reports with the decoder, we use learnable memory tokens which can be seen as prompts. Extensive experiments demonstrate the promising performance of our proposed method which generates state-of-the-art performance on the MIMIC-CXR dataset.
Revolutionizing Disease Diagnosis with simultaneous functional PET/MR and Deeply Integrated Brain Metabolic, Hemodynamic, and Perfusion Networks
Mar 29, 2024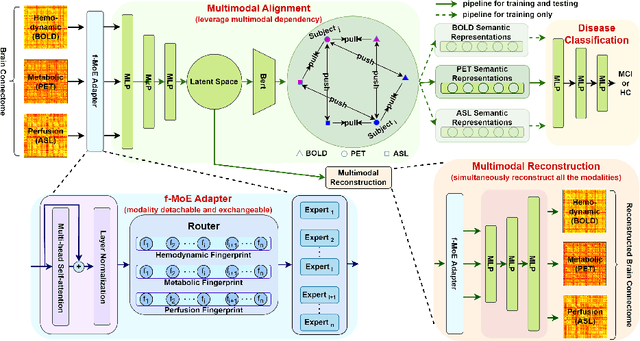
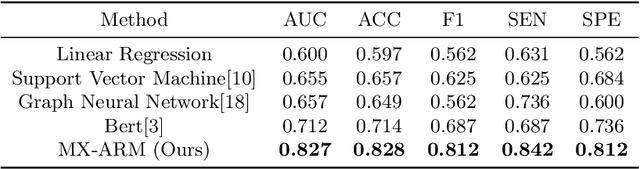
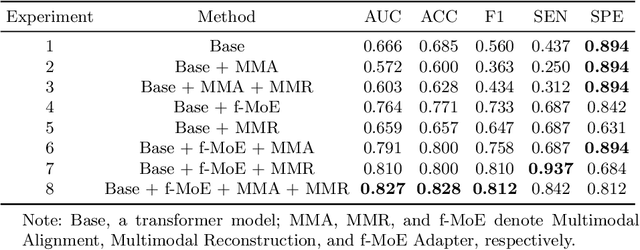
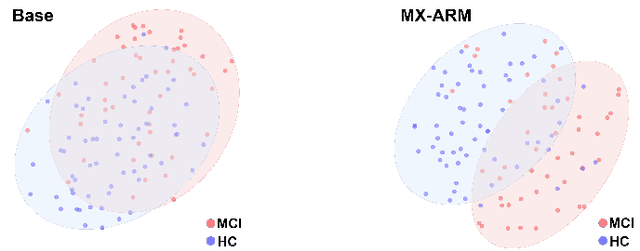
Simultaneous functional PET/MR (sf-PET/MR) presents a cutting-edge multimodal neuroimaging technique. It provides an unprecedented opportunity for concurrently monitoring and integrating multifaceted brain networks built by spatiotemporally covaried metabolic activity, neural activity, and cerebral blood flow (perfusion). Albeit high scientific/clinical values, short in hardware accessibility of PET/MR hinders its applications, let alone modern AI-based PET/MR fusion models. Our objective is to develop a clinically feasible AI-based disease diagnosis model trained on comprehensive sf-PET/MR data with the power of, during inferencing, allowing single modality input (e.g., PET only) as well as enforcing multimodal-based accuracy. To this end, we propose MX-ARM, a multimodal MiXture-of-experts Alignment and Reconstruction Model. It is modality detachable and exchangeable, allocating different multi-layer perceptrons dynamically ("mixture of experts") through learnable weights to learn respective representations from different modalities. Such design will not sacrifice model performance in uni-modal situation. To fully exploit the inherent complex and nonlinear relation among modalities while producing fine-grained representations for uni-modal inference, we subsequently add a modal alignment module to line up a dominant modality (e.g., PET) with representations of auxiliary modalities (MR). We further adopt multimodal reconstruction to promote the quality of learned features. Experiments on precious multimodal sf-PET/MR data for Mild Cognitive Impairment diagnosis showcase the efficacy of our model toward clinically feasible precision medicine.