 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA: Efficient Model Adaptation for Learning-based Systems
May 13, 2026Machine learning (ML) is increasingly applied to optimize system performance in tasks such as resource management and network simulation. Unlike traditional ML tasks (e.g., image classification), networked systems often operate in heterogeneous, long-running, and dynamic environment states, where input conditions (e.g., network loads) and operational objectives can shift over time and across settings. Existing learning-based systems offer little support for adaptation, resulting in costly model training, extensive data collection, degraded system performance, and slow responsiveness. This paper presents EMA, the first model adaptation system supporting learning-based systems to adapt to evolving environments with minimal operational overhead. EMA takes a system-driven, data-centric approach that accommodates diverse system and model designs while addressing two key deployment challenges. First, it reduces expensive model training by introducing state transformers that align the input state of a new environment with previously similar states, allowing models to warm-start adaptation. Second, it addresses the often-overlooked yet costly process of data labeling--collecting ground truth for exploring and training on various system decisions--by prioritizing labeling high-utility data while balancing the tradeoff between training and labeling cost. Evaluations on eight representative learning-based systems show that EMA reduces adaptation costs (e.g., GPU training time) by 14.9-42.4% while improving system performance (e.g., network throughput) by 6.9-31.3%.
Trust the Unreliability: Inward Backward Dynamic Unreliability Driven Coreset Selection for Medical Image Classification
Mar 18, 2026Efficiently managing and utilizing large-scale medical imaging datasets with limited resources presents significant challenges. While coreset selection helps reduce computational costs, its effectiveness in medical data remains limited due to inherent complexity, such as large intra-class variation and high inter-class similarity. To address this, we revisit the training process and observe that neural networks consistently produce stable confidence predictions and better remember samples near class centers in training. However, concentrating on these samples may complicate the modeling of decision boundaries. Hence, we argue that the more unreliable samples are, in fact, the more informative in helping build the decision boundary. Based on this, we propose the Dynamic Unreliability-Driven Coreset Selection(DUCS) strategy. Specifically, we introduce an inward-backward unreliability assessment perspective: 1) Inward Self-Awareness: The model introspects its behavior by analyzing the evolution of confidence during training, thereby quantifying uncertainty of each sample. 2) Backward Memory Tracking: The model reflects on its training tracking by tracking the frequency of forgetting samples, thus evaluating its retention ability for each sample. Next, we select unreliable samples that exhibit substantial confidence fluctuations and are repeatedly forgotten during training. This selection process ensures that the chosen samples are near the decision boundary, thereby aiding the model in refining the boundary. Extensive experiments on public medical datasets demonstrate our superior performance compared to state-of-the-art(SOTA) methods, particularly at high compression rates.
Joint Deblurring and 3D Reconstruction for Macrophotography
Oct 02, 2025
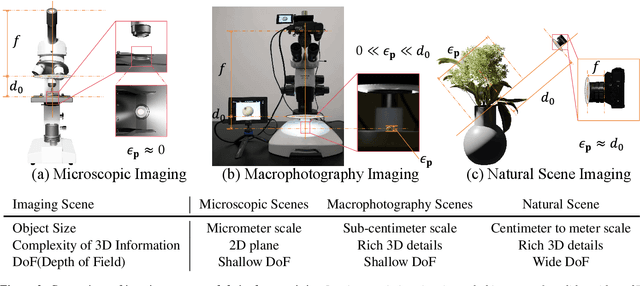
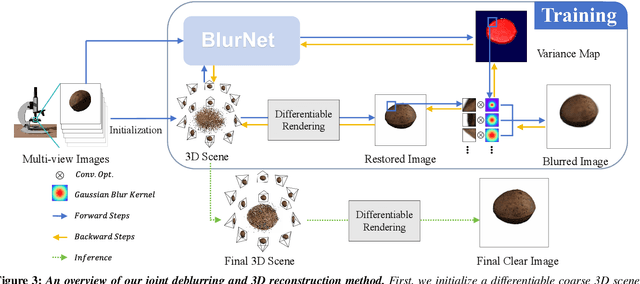

Macro lens has the advantages of high resolution and large magnification, and 3D modeling of small and detailed objects can provide richer information. However, defocus blur in macrophotography is a long-standing problem that heavily hinders the clear imaging of the captured objects and high-quality 3D reconstruction of them. Traditional image deblurring methods require a large number of images and annotations, and there is currently no multi-view 3D reconstruction method for macrophotography. In this work, we propose a joint deblurring and 3D reconstruction method for macrophotography. Starting from multi-view blurry images captured, we jointly optimize the clear 3D model of the object and the defocus blur kernel of each pixel. The entire framework adopts a differentiable rendering method to self-supervise the optimization of the 3D model and the defocus blur kernel. Extensive experiments show that from a small number of multi-view images, our proposed method can not only achieve high-quality image deblurring but also recover high-fidelity 3D appearance.
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Aug 07, 2025Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) techniques have exhibited remarkable performance across a wide range of domains. However, existing RAG approaches primarily operate on unstructured data and demonstrate limited capability in handling structured knowledge such as knowledge graphs. Meanwhile, current graph retrieval methods fundamentally struggle to capture holistic graph structures while simultaneously facing precision control challenges that manifest as either critical information gaps or excessive redundant connections, collectively undermining reasoning performance. To address this challenge, we propose GRAIL: Graph-Retrieval Augmented Interactive Learning, a framework designed to interact with large-scale graphs for retrieval-augmented reasoning. Specifically, GRAIL integrates LLM-guided random exploration with path filtering to establish a data synthesis pipeline, where a fine-grained reasoning trajectory is automatically generated for each task. Based on the synthesized data, we then employ a two-stage training process to learn a policy that dynamically decides the optimal actions at each reasoning step. The overall objective of precision-conciseness balance in graph retrieval is decoupled into fine-grained process-supervised rewards to enhance data efficiency and training stability. In practical deployment, GRAIL adopts an interactive retrieval paradigm, enabling the model to autonomously explore graph paths while dynamically balancing retrieval breadth and precision. Extensive experiments have shown that GRAIL achieves an average accuracy improvement of 21.01% and F1 improvement of 22.43% on three knowledge graph question-answering datasets. Our source code and datasets is available at https://github.com/Changgeww/GRAIL.
Time's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025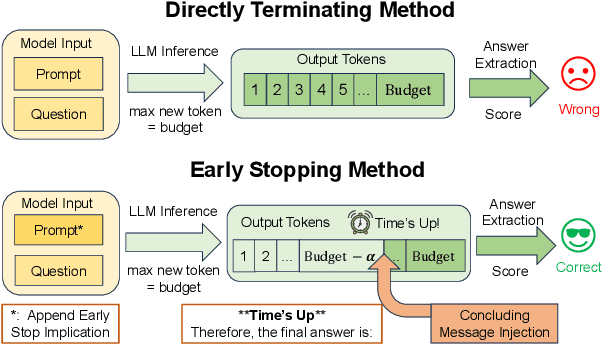
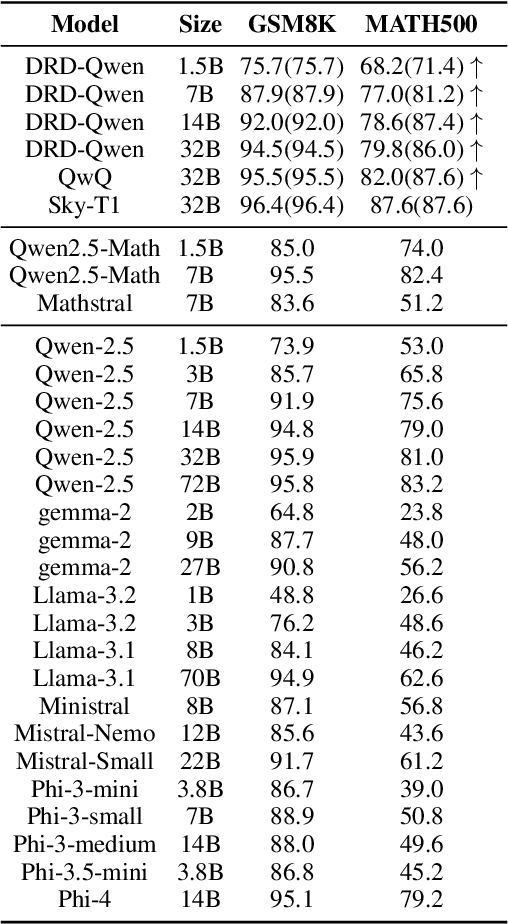
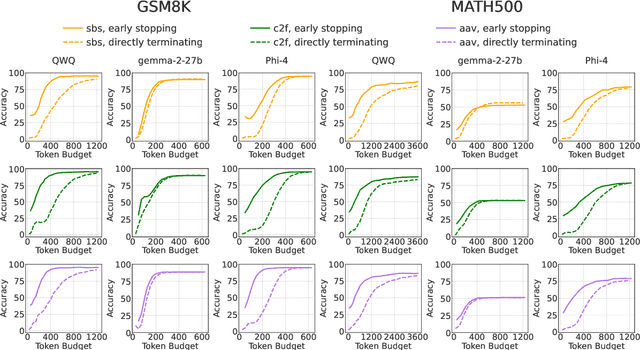
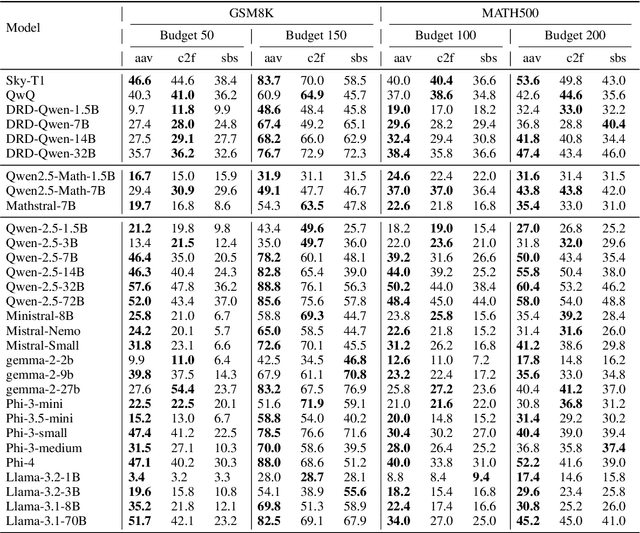
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
Multimodal 3D Genome Pre-training
Apr 12, 2025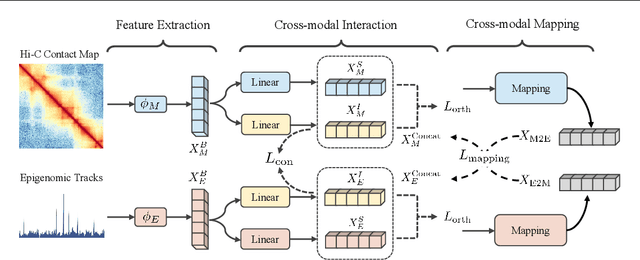
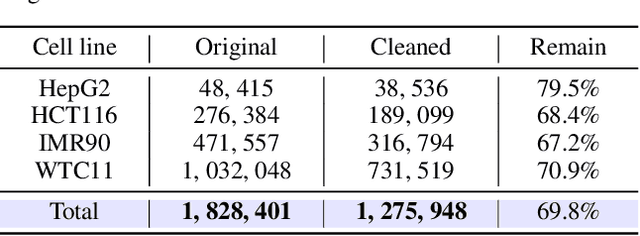
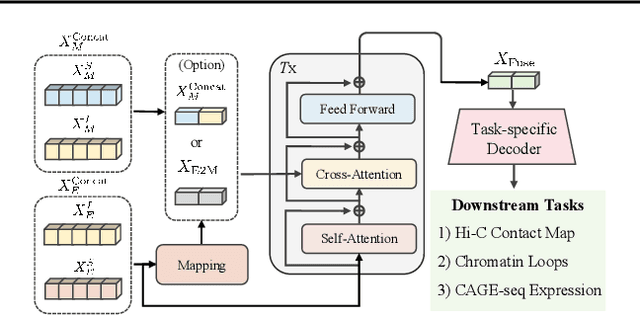
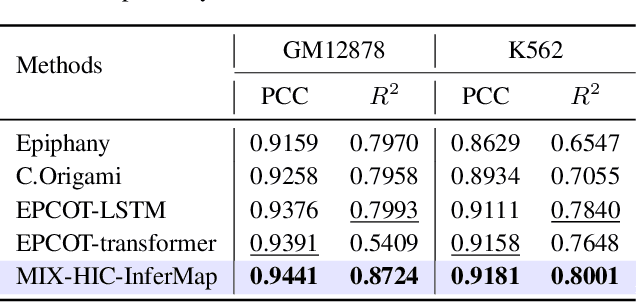
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
Guaranteeing consistency in evidence fusion: A novel perspective on credibility
Apr 05, 2025It is explored that available credible evidence fusion schemes suffer from the potential inconsistency because credibility calculation and Dempster's combination rule-based fusion are sequentially performed in an open-loop style. This paper constructs evidence credibility from the perspective of the degree of support for events within the framework of discrimination (FOD) and proposes an iterative credible evidence fusion (ICEF) to overcome the inconsistency in view of close-loop control. On one hand, the ICEF introduces the fusion result into credibility assessment to establish the correlation between credibility and the fusion result. On the other hand, arithmetic-geometric divergence is promoted based on the exponential normalization of plausibility and belief functions to measure evidence conflict, called plausibility-belief arithmetic-geometric divergence (PBAGD), which is superior in capturing the correlation and difference of FOD subsets, identifying abnormal sources, and reducing their fusion weights. The ICEF is compared with traditional methods by combining different evidence difference measure forms via numerical examples to verify its performance. Simulations on numerical examples and benchmark datasets reflect the adaptability of PBAGD to the proposed fusion strategy.
Data Center Cooling System Optimization Using Offline Reinforcement Learning
Jan 25, 2025



The recent advances in information technology and artificial intelligence have fueled a rapid expansion of the data center (DC) industry worldwide, accompanied by an immense appetite for electricity to power the DCs. In a typical DC, around 30~40% of the energy is spent on the cooling system rather than on computer servers, posing a pressing need for developing new energy-saving optimization technologies for DC cooling systems. However, optimizing such real-world industrial systems faces numerous challenges, including but not limited to a lack of reliable simulation environments, limited historical data, and stringent safety and control robustness requirements. In this work, we present a novel physics-informed offline reinforcement learning (RL) framework for energy efficiency optimization of DC cooling systems. The proposed framework models the complex dynamical patterns and physical dependencies inside a server room using a purposely designed graph neural network architecture that is compliant with the fundamental time-reversal symmetry. Because of its well-behaved and generalizable state-action representations, the model enables sample-efficient and robust latent space offline policy learning using limited real-world operational data. Our framework has been successfully deployed and verified in a large-scale production DC for closed-loop control of its air-cooling units (ACUs). We conducted a total of 2000 hours of short and long-term experiments in the production DC environment. The results show that our method achieves 14~21% energy savings in the DC cooling system, without any violation of the safety or operational constraints. Our results have demonstrated the significant potential of offline RL in solving a broad range of data-limited, safety-critical real-world industrial control problems.
A privacy-preserving distributed credible evidence fusion algorithm for collective decision-making
Dec 03, 2024



The theory of evidence reasoning has been applied to collective decision-making in recent years. However, existing distributed evidence fusion methods lead to participants' preference leakage and fusion failures as they directly exchange raw evidence and do not assess evidence credibility like centralized credible evidence fusion (CCEF) does. To do so, a privacy-preserving distributed credible evidence fusion method with three-level consensus (PCEF) is proposed in this paper. In evidence difference measure (EDM) neighbor consensus, an evidence-free equivalent expression of EDM among neighbored agents is derived with the shared dot product protocol for pignistic probability and the identical judgment of two events with maximal subjective probabilities, so that evidence privacy is guaranteed due to such irreversible evidence transformation. In EDM network consensus, the non-neighbored EDMs are inferred and neighbored EDMs reach uniformity via interaction between linear average consensus (LAC) and low-rank matrix completion with rank adaptation to guarantee EDM consensus convergence and no solution of inferring raw evidence in numerical iteration style. In fusion network consensus, a privacy-preserving LAC with a self-cancelling differential privacy term is proposed, where each agent adds its randomness to the sharing content and step-by-step cancels such randomness in consensus iterations. Besides, the sufficient condition of the convergence to the CCEF is explored, and it is proven that raw evidence is impossibly inferred in such an iterative consensus. The simulations show that PCEF is close to CCEF both in credibility and fusion results and obtains higher decision accuracy with less time-comsuming than existing methods.
Polar-Coded Tensor-Based Unsourced Random Access with Soft Decoding
Jun 24, 2024



The unsourced random access (URA) has emerged as a viable scheme for supporting the massive machine-type communications (mMTC) in the sixth generation (6G) wireless networks. Notably, the tensor-based URA (TURA), with its inherent tensor structure, stands out by simultaneously enhancing performance and reducing computational complexity for the multi-user separation, especially in mMTC networks with a large numer of active devices. However, current TURA scheme lacks the soft decoder, thus precluding the incorporation of existing advanced coding techniques. In order to fully explore the potential of the TURA, this paper investigates the Polarcoded TURA (PTURA) scheme and develops the corresponding iterative Bayesian receiver with feedback (IBR-FB). Specifically, in the IBR-FB, we propose the Grassmannian modulation-aided Bayesian tensor decomposition (GM-BTD) algorithm under the variational Bayesian learning (VBL) framework, which leverages the property of the Grassmannian modulation to facilitate the convergence of the VBL process, and has the ability to generate the required soft information without the knowledge of the number of active devices. Furthermore, based on the soft information produced by the GM-BTD, we design the soft Grassmannian demodulator in the IBR-FB. Extensive simulation results demonstrate that the proposed PTURA in conjunction with the IBR-FB surpasses the existing state-of-the-art unsourced random access scheme in terms of accuracy and computational complexity.