 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal 3D Genome Pre-training
Apr 12, 2025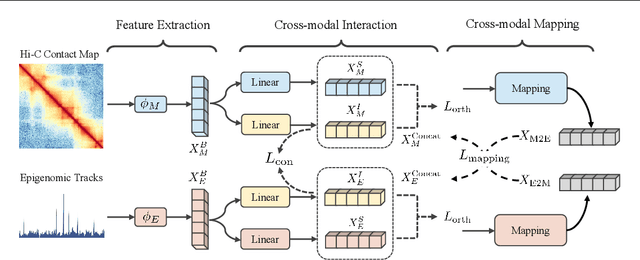
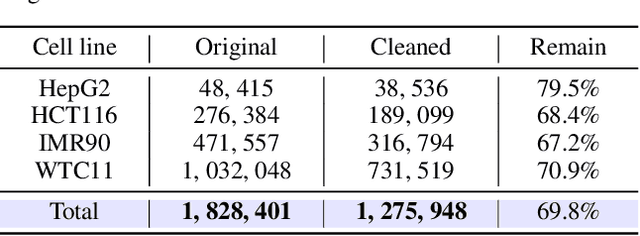
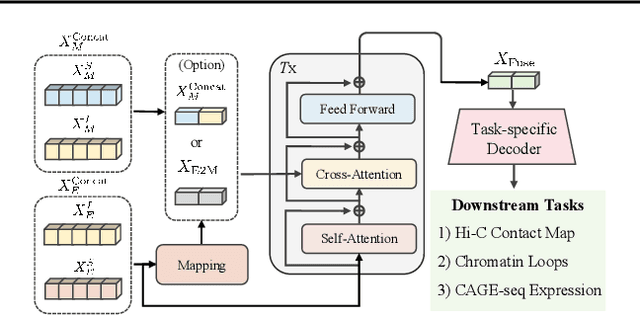
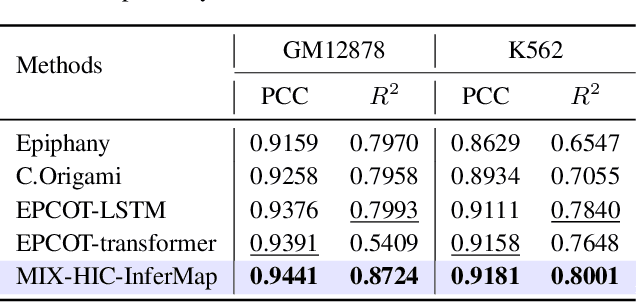
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
Rene: A Pre-trained Multi-modal Architecture for Auscultation of Respiratory Diseases
May 13, 2024

This study presents a novel methodology utilizing a pre-trained speech recognition model for processing respiratory sound data. By incorporating medical record information, we introduce an innovative multi-modal deep-learning architecture, named Rene, which addresses the challenges of poor interpretability and underperformance in real-time clinical diagnostic response observed in previous respiratory disease-focused models. The proposed Rene architecture demonstrated significant improvements of 10.24%, 16.15%, 15.29%, and 18.90% respectively, compared to the baseline across four tasks related to respiratory event detection and audio record classification on the SPRSound database. In patient disease prediction tests on the ICBHI database, the architecture exhibited improvements of 23% in the mean of average score and harmonic score compared to the baseline. Furthermore, we developed a real-time respiratory sound discrimination system based on the Rene architecture, featuring a dual-thread design and compressed model parameters for simultaneous microphone recording and real-time dynamic decoding. Employing state-of-the-art Edge AI technology, this system enables rapid and accurate responses for respiratory sound auscultation, facilitating deployment on wearable clinical detection devices to capture incremental data, which can be synergistically evolved with large-scale models deployed on cloud servers for downstream tasks.