 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025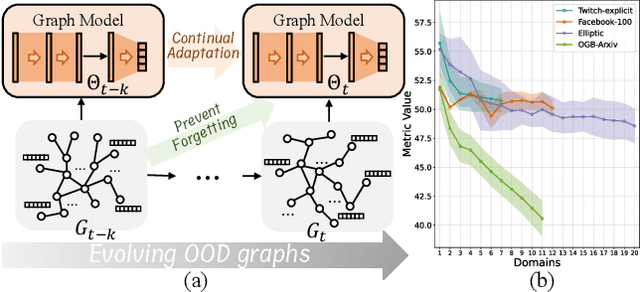
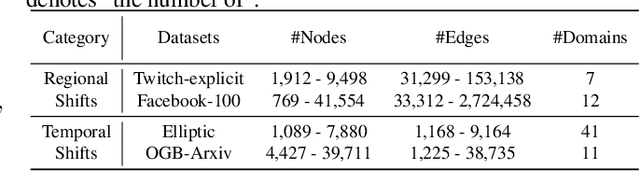
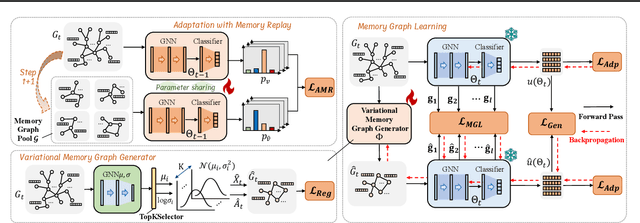
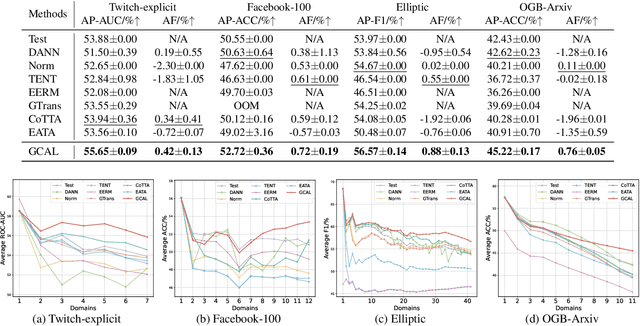
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
Multimodal 3D Genome Pre-training
Apr 12, 2025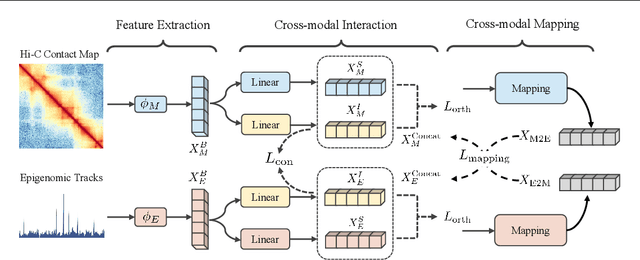
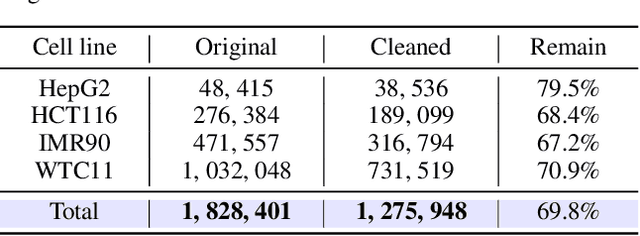
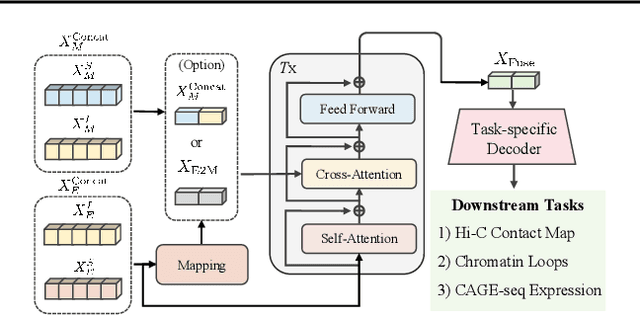
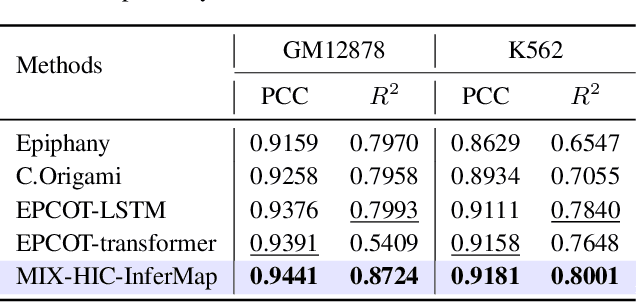
Deep learning techniques have driven significant progress in various analytical tasks within 3D genomics in computational biology. However, a holistic understanding of 3D genomics knowledge remains underexplored. Here, we propose MIX-HIC, the first multimodal foundation model of 3D genome that integrates both 3D genome structure and epigenomic tracks, which obtains unified and comprehensive semantics. For accurate heterogeneous semantic fusion, we design the cross-modal interaction and mapping blocks for robust unified representation, yielding the accurate aggregation of 3D genome knowledge. Besides, we introduce the first large-scale dataset comprising over 1 million pairwise samples of Hi-C contact maps and epigenomic tracks for high-quality pre-training, enabling the exploration of functional implications in 3D genomics. Extensive experiments show that MIX-HIC can significantly surpass existing state-of-the-art methods in diverse downstream tasks. This work provides a valuable resource for advancing 3D genomics research.
Can Large Language Models Help Experimental Design for Causal Discovery?
Mar 04, 2025



Designing proper experiments and selecting optimal intervention targets is a longstanding problem in scientific or causal discovery. Identifying the underlying causal structure from observational data alone is inherently difficult. Obtaining interventional data, on the other hand, is crucial to causal discovery, yet it is usually expensive and time-consuming to gather sufficient interventional data to facilitate causal discovery. Previous approaches commonly utilize uncertainty or gradient signals to determine the intervention targets. However, numerical-based approaches may yield suboptimal results due to the inaccurate estimation of the guiding signals at the beginning when with limited interventional data. In this work, we investigate a different approach, whether we can leverage Large Language Models (LLMs) to assist with the intervention targeting in causal discovery by making use of the rich world knowledge about the experimental design in LLMs. Specifically, we present Large Language Model Guided Intervention Targeting (LeGIT) -- a robust framework that effectively incorporates LLMs to augment existing numerical approaches for the intervention targeting in causal discovery. Across 4 realistic benchmark scales, LeGIT demonstrates significant improvements and robustness over existing methods and even surpasses humans, which demonstrates the usefulness of LLMs in assisting with experimental design for scientific discovery.
SEE: See Everything Every Time -- Adaptive Brightness Adjustment for Broad Light Range Images via Events
Feb 28, 2025Event cameras, with a high dynamic range exceeding $120dB$, significantly outperform traditional embedded cameras, robustly recording detailed changing information under various lighting conditions, including both low- and high-light situations. However, recent research on utilizing event data has primarily focused on low-light image enhancement, neglecting image enhancement and brightness adjustment across a broader range of lighting conditions, such as normal or high illumination. Based on this, we propose a novel research question: how to employ events to enhance and adaptively adjust the brightness of images captured under broad lighting conditions? To investigate this question, we first collected a new dataset, SEE-600K, consisting of 610,126 images and corresponding events across 202 scenarios, each featuring an average of four lighting conditions with over a 1000-fold variation in illumination. Subsequently, we propose a framework that effectively utilizes events to smoothly adjust image brightness through the use of prompts. Our framework captures color through sensor patterns, uses cross-attention to model events as a brightness dictionary, and adjusts the image's dynamic range to form a broad light-range representation (BLR), which is then decoded at the pixel level based on the brightness prompt. Experimental results demonstrate that our method not only performs well on the low-light enhancement dataset but also shows robust performance on broader light-range image enhancement using the SEE-600K dataset. Additionally, our approach enables pixel-level brightness adjustment, providing flexibility for post-processing and inspiring more imaging applications. The dataset and source code are publicly available at:https://github.com/yunfanLu/SEE.
Boosting Knowledge Graph-based Recommendations through Confidence-Aware Augmentation with Large Language Models
Feb 06, 2025



Knowledge Graph-based recommendations have gained significant attention due to their ability to leverage rich semantic relationships. However, constructing and maintaining Knowledge Graphs (KGs) is resource-intensive, and the accuracy of KGs can suffer from noisy, outdated, or irrelevant triplets. Recent advancements in Large Language Models (LLMs) offer a promising way to improve the quality and relevance of KGs for recommendation tasks. Despite this, integrating LLMs into KG-based systems presents challenges, such as efficiently augmenting KGs, addressing hallucinations, and developing effective joint learning methods. In this paper, we propose the Confidence-aware KG-based Recommendation Framework with LLM Augmentation (CKG-LLMA), a novel framework that combines KGs and LLMs for recommendation task. The framework includes: (1) an LLM-based subgraph augmenter for enriching KGs with high-quality information, (2) a confidence-aware message propagation mechanism to filter noisy triplets, and (3) a dual-view contrastive learning method to integrate user-item interactions and KG data. Additionally, we employ a confidence-aware explanation generation process to guide LLMs in producing realistic explanations for recommendations. Finally, extensive experiments demonstrate the effectiveness of CKG-LLMA across multiple public datasets.