 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriaging Threats to Specialized Guardrails
May 29, 2026Building robust safety guardrails is essential for deploying Large Language Models across diverse real-world applications. However, this goal remains challenging because safety risks span heterogeneous threat domains, while existing datasets cover only fragmented risk subsets and rely on inconsistent taxonomies. Consequently, it remains unclear whether current guardrails can generalize beyond narrow evaluation settings. To better understand the robustness of guardrail models, we first introduce GuardZoo, a unified human-annotated benchmark with 32,460 samples covering 15 distinct unsafe categories. Evaluation on GuardZoo reveals that monolithic guardrails suffer from task interference: different threat domains require distinct decision boundaries that are difficult to compress into a single model. We therefore propose RouteGuard, a router-expert framework that triages each conversation to specialized expert guardrails for threat-specific detection. Experiments show that RouteGuard improves fine-grained threat detection over strong guardrail baselines, generalizes better under out-of-domain evaluation, and supports flexible modular expansion to emerging threats.
Personalized RewardBench: Evaluating Reward Models with Human Aligned Personalization
Apr 08, 2026Pluralistic alignment has emerged as a critical frontier in the development of Large Language Models (LLMs), with reward models (RMs) serving as a central mechanism for capturing diverse human values. While benchmarks for general response quality are prevalent, evaluating how well reward models account for individual user preferences remains an open challenge. To bridge this gap, we introduce Personalized RewardBench, a novel benchmark designed to rigorously assess reward models' capacity to model personalized preferences. We construct chosen and rejected response pairs based on strict adherence to (or violation of) user-specific rubrics, ensuring that preference distinctions are uniquely tailored to the individual. In particular, human evaluations confirm that the primary discriminative factor between pairs is strictly personal preference, with both responses maintaining high general quality (e.g., correctness, relevance and helpfulness). Extensive testing reveals that existing state-of-the-art reward models struggle significantly with personalization, peaking at an accuracy of just 75.94%. Crucially, because an effective reward model benchmark should predict a reward model's performance on downstream tasks, we conduct experiments demonstrating that our benchmark exhibits a significantly higher correlation with downstream performance in both Best-of-N (BoN) sampling and Proximal Policy Optimization (PPO) compared to existing baselines. These findings establish Personalized RewardBench as a robust and accurate proxy for evaluating reward models' performance in downstream applications.
Your Agent is More Brittle Than You Think: Uncovering Indirect Injection Vulnerabilities in Agentic LLMs
Apr 04, 2026The rapid deployment of open-source frameworks has significantly advanced the development of modern multi-agent systems. However, expanded action spaces, including uncontrolled privilege exposure and hidden inter-system interactions, pose severe security challenges. Specifically, Indirect Prompt Injections (IPI), which conceal malicious instructions within third-party content, can trigger unauthorized actions such as data exfiltration during normal operations. While current security evaluations predominantly rely on isolated single-turn benchmarks, the systemic vulnerabilities of these agents within complex dynamic environments remain critically underexplored. To bridge this gap, we systematically evaluate six defense strategies against four sophisticated IPI attack vectors across nine LLM backbones. Crucially, we conduct our evaluation entirely within dynamic multi-step tool-calling environments to capture the true attack surface of modern autonomous agents. Moving beyond binary success rates, our multidimensional analysis reveals a pronounced fragility. Advanced injections successfully bypass nearly all baseline defenses, and some surface-level mitigations even produce counterproductive side effects. Furthermore, while agents execute malicious instructions almost instantaneously, their internal states exhibit abnormally high decision entropy. Motivated by this latent hesitation, we investigate Representation Engineering (RepE) as a robust detection strategy. By extracting hidden states at the tool-input position, we revealed that the RepE-based circuit breaker successfully identifies and intercepts unauthorized actions before the agent commits to them, achieving high detection accuracy across diverse LLM backbones. This study exposes the limitations of current IPI defenses and provides a highly practical paradigm for building resilient multi-agent architectures.
Grounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
GRMLR: Knowledge-Enhanced Small-Data Learning for Deep-Sea Cold Seep Stage Inference
Mar 25, 2026Deep-sea cold seep stage assessment has traditionally relied on costly, high-risk manned submersible operations and visual surveys of macrofauna. Although microbial communities provide a promising and more cost-effective alternative, reliable inference remains challenging because the available deep-sea dataset is extremely small ($n = 13$) relative to the microbial feature dimension ($p = 26$), making purely data-driven models highly prone to overfitting. To address this, we propose a knowledge-enhanced classification framework that incorporates an ecological knowledge graph as a structural prior. By fusing macro-microbe coupling and microbial co-occurrence patterns, the framework internalizes established ecological logic into a \underline{\textbf{G}}raph-\underline{\textbf{R}}egularized \underline{\textbf{M}}ultinomial \underline{\textbf{L}}ogistic \underline{\textbf{R}}egression (GRMLR) model, effectively constraining the feature space through a manifold penalty to ensure biologically consistent classification. Importantly, the framework removes the need for macrofauna observations at inference time: macro-microbe associations are used only to guide training, whereas prediction relies solely on microbial abundance profiles. Experimental results demonstrate that our approach significantly outperforms standard baselines, highlighting its potential as a robust and scalable framework for deep-sea ecological assessment.
Summarize Before You Speak with ARACH: A Training-Free Inference-Time Plug-In for Enhancing LLMs via Global Attention Reallocation
Mar 10, 2026Large language models (LLMs) achieve remarkable performance, yet further gains often require costly training. This has motivated growing interest in post-training techniques-especially training-free approaches that improve models at inference time without updating weights. Most training-free methods treat the model as a black box and improve outputs via input/output-level interventions, such as prompt design and test-time scaling through repeated sampling, reranking/verification, or search. In contrast, they rarely offer a plug-and-play mechanism to intervene in a model's internal computation. We propose ARACH(Attention Reallocation via an Adaptive Context Hub), a training-free inference-time plug-in that augments LLMs with an adaptive context hub to aggregate context and reallocate attention. Extensive experiments across multiple language modeling tasks show consistent improvements with modest inference overhead and no parameter updates. Attention analyses further suggest that ARACH mitigates the attention sink phenomenon. These results indicate that engineering a model's internal computation offers a distinct inference-time strategy, fundamentally different from both prompt-based test-time methods and training-based post-training approaches.
Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
Feb 13, 2026In this report, we introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on large-scale cross-embodiment robot trajectories and vision-language data, endowing it with broad and generalizable action-generation capabilities while avoiding catastrophic forgetting of the visual-semantic knowledge of the underlying pre-trained VLM. During post-training, we propose several techniques for training the VLA model for asynchronous execution to address the inference latency during real-robot rollouts. During deployment, we carefully align the timesteps of consecutive predicted action chunks to ensure continuous and seamless real-time rollouts. We evaluate Xiaomi-Robotics-0 extensively in simulation benchmarks and on two challenging real-robot tasks that require precise and dexterous bimanual manipulation. Results show that our method achieves state-of-the-art performance across all simulation benchmarks. Moreover, Xiaomi-Robotics-0 can roll out fast and smoothly on real robots using a consumer-grade GPU, achieving high success rates and throughput on both real-robot tasks. To facilitate future research, code and model checkpoints are open-sourced at https://xiaomi-robotics-0.github.io
CARPE: Context-Aware Image Representation Prioritization via Ensemble for Large Vision-Language Models
Jan 20, 2026Recent advancements in Large Vision-Language Models (LVLMs) have pushed them closer to becoming general-purpose assistants. Despite their strong performance, LVLMs still struggle with vision-centric tasks such as image classification, underperforming compared to their base vision encoders, which are often CLIP-based models. To address this limitation, we propose Context-Aware Image Representation Prioritization via Ensemble (CARPE), a novel, model-agnostic framework which introduces vision-integration layers and a context-aware ensemble strategy to identify when to prioritize image representations or rely on the reasoning capabilities of the language model. This design enhances the model's ability to adaptively weight visual and textual modalities and enables the model to capture various aspects of image representations, leading to consistent improvements in generalization across classification and vision-language benchmarks. Extensive experiments demonstrate that CARPE not only improves performance on image classification benchmarks but also enhances results across various vision-language benchmarks. Finally, CARPE is designed to be effectively integrated with most open-source LVLMs that consist of a vision encoder and a language model, ensuring its adaptability across diverse architectures.
Diagnosing and Mitigating Modality Interference in Multimodal Large Language Models
May 26, 2025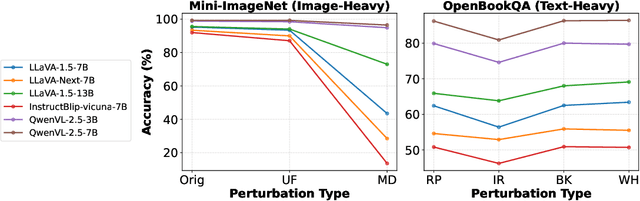
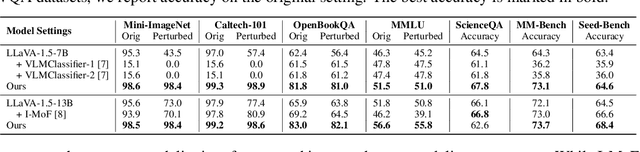
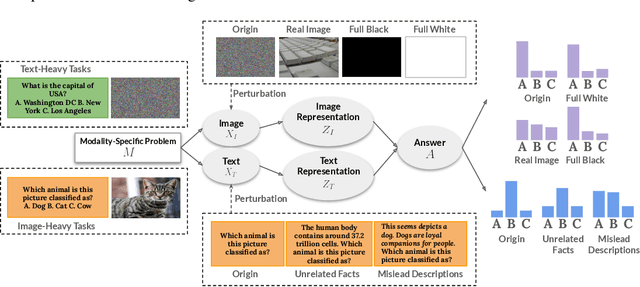
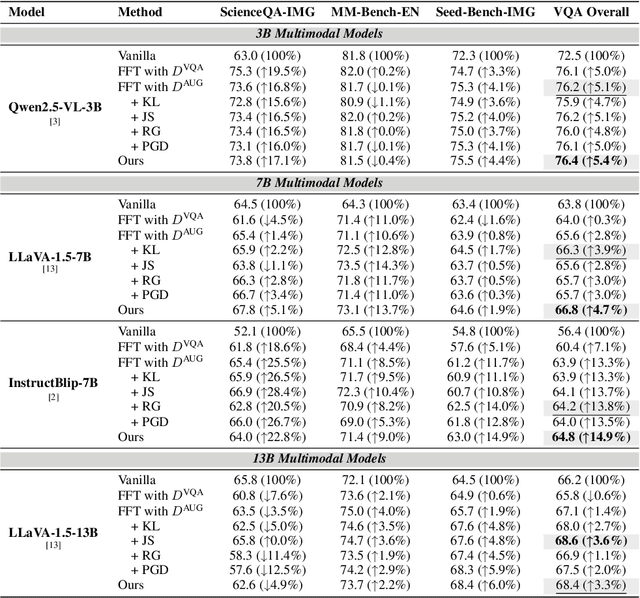
Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across tasks, yet they often exhibit difficulty in distinguishing task-relevant from irrelevant signals, particularly in tasks like Visual Question Answering (VQA), which can lead to susceptibility to misleading or spurious inputs. We refer to this broader limitation as the Cross-Modality Competency Problem: the model's inability to fairly evaluate all modalities. This vulnerability becomes more evident in modality-specific tasks such as image classification or pure text question answering, where models are expected to rely solely on one modality. In such tasks, spurious information from irrelevant modalities often leads to significant performance degradation. We refer to this failure as Modality Interference, which serves as a concrete and measurable instance of the cross-modality competency problem. We further design a perturbation-based causal diagnostic experiment to verify and quantify this problem. To mitigate modality interference, we propose a novel framework to fine-tune MLLMs, including perturbation-based data augmentations with both heuristic perturbations and adversarial perturbations via Projected Gradient Descent (PGD), and a consistency regularization strategy applied to model outputs with original and perturbed inputs. Experiments on multiple benchmark datasets (image-heavy, text-heavy, and VQA tasks) and multiple model families with different scales demonstrate significant improvements in robustness and cross-modality competency, indicating our method's effectiveness in boosting unimodal reasoning ability while enhancing performance on multimodal tasks.
Boosting Knowledge Graph-based Recommendations through Confidence-Aware Augmentation with Large Language Models
Feb 06, 2025



Knowledge Graph-based recommendations have gained significant attention due to their ability to leverage rich semantic relationships. However, constructing and maintaining Knowledge Graphs (KGs) is resource-intensive, and the accuracy of KGs can suffer from noisy, outdated, or irrelevant triplets. Recent advancements in Large Language Models (LLMs) offer a promising way to improve the quality and relevance of KGs for recommendation tasks. Despite this, integrating LLMs into KG-based systems presents challenges, such as efficiently augmenting KGs, addressing hallucinations, and developing effective joint learning methods. In this paper, we propose the Confidence-aware KG-based Recommendation Framework with LLM Augmentation (CKG-LLMA), a novel framework that combines KGs and LLMs for recommendation task. The framework includes: (1) an LLM-based subgraph augmenter for enriching KGs with high-quality information, (2) a confidence-aware message propagation mechanism to filter noisy triplets, and (3) a dual-view contrastive learning method to integrate user-item interactions and KG data. Additionally, we employ a confidence-aware explanation generation process to guide LLMs in producing realistic explanations for recommendations. Finally, extensive experiments demonstrate the effectiveness of CKG-LLMA across multiple public datasets.