 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstract2Appendix: Academic Reviews Enhance LLM Long-Context Capabilities
Nov 07, 2024



Large language models (LLMs) have shown remarkable performance across various tasks, yet their ability to handle long-context reading remains challenging. This study explores the effectiveness of leveraging high-quality academic peer review data for fine-tuning LLMs to enhance their long-context capabilities. We compare the Direct Preference Optimization (DPO) method with the Supervised Fine-Tuning (SFT) method, demonstrating DPO's superiority and data efficiency. Our experiments show that the fine-tuned model achieves a 4.04-point improvement over phi-3 and a 2.6\% increase on the Qasper benchmark using only 2000 samples. Despite facing limitations in data scale and processing costs, this study underscores the potential of DPO and high-quality data in advancing LLM performance. Additionally, the zero-shot benchmark results indicate that aggregated high-quality human reviews are overwhelmingly preferred over LLM-generated responses, even for the most capable models like GPT-4o. This suggests that high-quality human reviews are extremely rich in information, reasoning, and long-context retrieval, capabilities that even the most advanced models have not fully captured. These findings highlight the high utility of leveraging human reviews to further advance the field.
Zero-Shot Relational Learning for Multimodal Knowledge Graphs
Apr 09, 2024Relational learning is an essential task in the domain of knowledge representation, particularly in knowledge graph completion (KGC).While relational learning in traditional single-modal settings has been extensively studied, exploring it within a multimodal KGC context presents distinct challenges and opportunities. One of the major challenges is inference on newly discovered relations without any associated training data. This zero-shot relational learning scenario poses unique requirements for multimodal KGC, i.e., utilizing multimodality to facilitate relational learning. However, existing works fail to support the leverage of multimodal information and leave the problem unexplored. In this paper, we propose a novel end-to-end framework, consisting of three components, i.e., multimodal learner, structure consolidator, and relation embedding generator, to integrate diverse multimodal information and knowledge graph structures to facilitate the zero-shot relational learning. Evaluation results on two multimodal knowledge graphs demonstrate the superior performance of our proposed method.
Multi-modal preference alignment remedies regression of visual instruction tuning on language model
Feb 16, 2024



In production, multi-modal large language models (MLLMs) are expected to support multi-turn queries of interchanging image and text modalities. However, the current MLLMs trained with visual-question-answering (VQA) datasets could suffer from degradation, as VQA datasets lack the diversity and complexity of the original text instruction datasets which the underlying language model had been trained with. To address this challenging degradation, we first collect a lightweight (6k entries) VQA preference dataset where answers were annotated by Gemini for 5 quality metrics in a granular fashion, and investigate standard Supervised Fine-tuning, rejection sampling, Direct Preference Optimization (DPO), and SteerLM. Our findings indicate that the with DPO we are able to surpass instruction-following capabilities of the language model, achieving a 6.73 score on MT-Bench, compared to Vicuna's 6.57 and LLaVA's 5.99 despite small data scale. This enhancement in textual instruction proficiency correlates with boosted visual instruction performance (+4.9\% on MM-Vet, +6\% on LLaVA-Bench), with minimal alignment tax on visual knowledge benchmarks compared to previous RLHF approach. In conclusion, we propose a distillation-based multi-modal alignment model with fine-grained annotations on a small dataset that reconciles the textual and visual performance of MLLMs, restoring and boosting language capability after visual instruction tuning.
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Jan 21, 2024



Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
Modeling non-uniform uncertainty in Reaction Prediction via Boosting and Dropout
Oct 07, 2023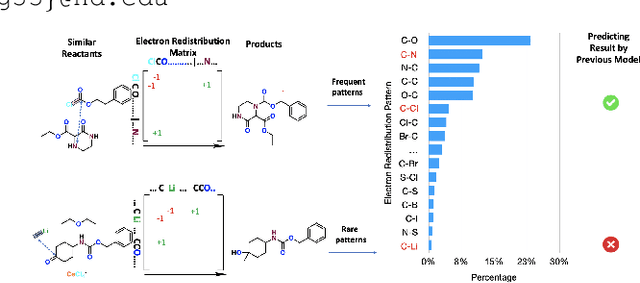
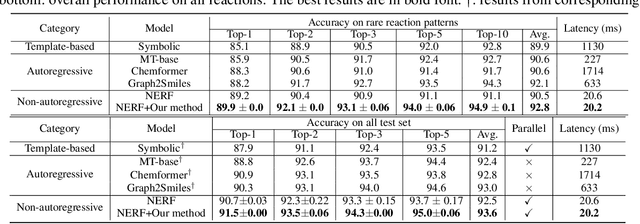
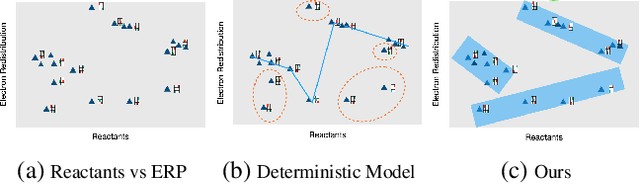
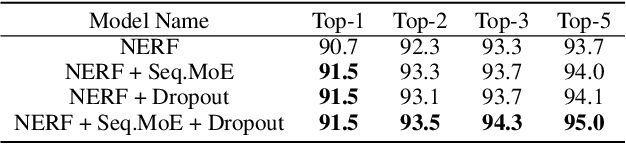
Reaction prediction has been recognized as a critical task in synthetic chemistry, where the goal is to predict the outcome of a reaction based on the given reactants. With the widespread adoption of generative models, the Variational Autoencoder(VAE) framework has typically been employed to tackle challenges in reaction prediction, where the reactants are encoded as a condition for the decoder, which then generates the product. Despite effectiveness, these conditional VAE (CVAE) models still fail to adequately account for the inherent uncertainty in reaction prediction, which primarily stems from the stochastic reaction process. The principal limitations are twofold. Firstly, in these CVAE models, the prior is independent of the reactants, leading to a default wide and assumed uniform distribution variance of the generated product. Secondly, reactants with analogous molecular representations are presumed to undergo similar electronic transition processes, thereby producing similar products. This hinders the ability to model diverse reaction mechanisms effectively. Since the variance in outcomes is inherently non-uniform, we are thus motivated to develop a framework that generates reaction products with non-uniform uncertainty. Firstly, we eliminate the latent variable in previous CVAE models to mitigate uncontrol-label noise. Instead, we introduce randomness into product generation via boosting to ensemble diverse models and cover the range of potential outcomes, and through dropout to secure models with minor variations. Additionally, we design a ranking method to union the predictions from boosting and dropout, prioritizing the most plausible products. Experimental results on the largest reaction prediction benchmark USPTO-MIT show the superior performance of our proposed method in modeling the non-uniform uncertainty compared to baselines.
LogicRec: Recommendation with Users' Logical Requirements
Apr 23, 2023



Users may demand recommendations with highly personalized requirements involving logical operations, e.g., the intersection of two requirements, where such requirements naturally form structured logical queries on knowledge graphs (KGs). To date, existing recommender systems lack the capability to tackle users' complex logical requirements. In this work, we formulate the problem of recommendation with users' logical requirements (LogicRec) and construct benchmark datasets for LogicRec. Furthermore, we propose an initial solution for LogicRec based on logical requirement retrieval and user preference retrieval, where we face two challenges. First, KGs are incomplete in nature. Therefore, there are always missing true facts, which entails that the answers to logical requirements can not be completely found in KGs. In this case, item selection based on the answers to logical queries is not applicable. We thus resort to logical query embedding (LQE) to jointly infer missing facts and retrieve items based on logical requirements. Second, answer sets are under-exploited. Existing LQE methods can only deal with query-answer pairs, where queries in our case are the intersected user preferences and logical requirements. However, the logical requirements and user preferences have different answer sets, offering us richer knowledge about the requirements and preferences by providing requirement-item and preference-item pairs. Thus, we design a multi-task knowledge-sharing mechanism to exploit these answer sets collectively. Extensive experimental results demonstrate the significance of the LogicRec task and the effectiveness of our proposed method.
Knowledge Distillation on Graphs: A Survey
Feb 01, 2023Graph Neural Networks (GNNs) have attracted tremendous attention by demonstrating their capability to handle graph data. However, they are difficult to be deployed in resource-limited devices due to model sizes and scalability constraints imposed by the multi-hop data dependency. In addition, real-world graphs usually possess complex structural information and features. Therefore, to improve the applicability of GNNs and fully encode the complicated topological information, knowledge distillation on graphs (KDG) has been introduced to build a smaller yet effective model and exploit more knowledge from data, leading to model compression and performance improvement. Recently, KDG has achieved considerable progress with many studies proposed. In this survey, we systematically review these works. Specifically, we first introduce KDG challenges and bases, then categorize and summarize existing works of KDG by answering the following three questions: 1) what to distillate, 2) who to whom, and 3) how to distillate. Finally, we share our thoughts on future research directions.
Joint Abductive and Inductive Neural Logical Reasoning
May 29, 2022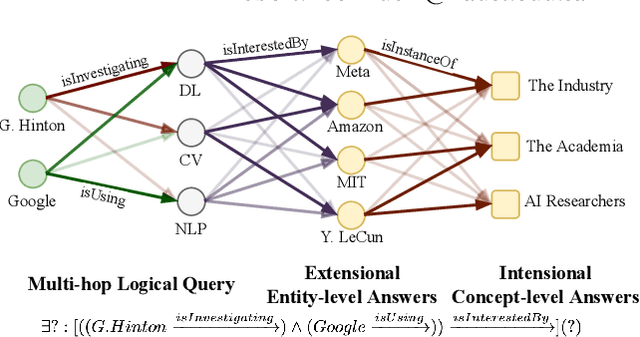



Neural logical reasoning (NLR) is a fundamental task in knowledge discovery and artificial intelligence. NLR aims at answering multi-hop queries with logical operations on structured knowledge bases based on distributed representations of queries and answers. While previous neural logical reasoners can give specific entity-level answers, i.e., perform inductive reasoning from the perspective of logic theory, they are not able to provide descriptive concept-level answers, i.e., perform abductive reasoning, where each concept is a summary of a set of entities. In particular, the abductive reasoning task attempts to infer the explanations of each query with descriptive concepts, which make answers comprehensible to users and is of great usefulness in the field of applied ontology. In this work, we formulate the problem of the joint abductive and inductive neural logical reasoning (AI-NLR), solving which needs to address challenges in incorporating, representing, and operating on concepts. We propose an original solution named ABIN for AI-NLR. Firstly, we incorporate description logic-based ontological axioms to provide the source of concepts. Then, we represent concepts and queries as fuzzy sets, i.e., sets whose elements have degrees of membership, to bridge concepts and queries with entities. Moreover, we design operators involving concepts on top of the fuzzy set representation of concepts and queries for optimization and inference. Extensive experimental results on two real-world datasets demonstrate the effectiveness of ABIN for AI-NLR.
Positive-Unlabeled Learning with Adversarial Data Augmentation for Knowledge Graph Completion
May 02, 2022



Most real-world knowledge graphs (KG) are far from complete and comprehensive. This problem has motivated efforts in predicting the most plausible missing facts to complete a given KG, i.e., knowledge graph completion (KGC). However, existing KGC methods suffer from two main issues, 1) the false negative issue, i.e., the candidates for sampling negative training instances include potential true facts; and 2) the data sparsity issue, i.e., true facts account for only a tiny part of all possible facts. To this end, we propose positive-unlabeled learning with adversarial data augmentation (PUDA) for KGC. In particular, PUDA tailors positive-unlabeled risk estimator for the KGC task to deal with the false negative issue. Furthermore, to address the data sparsity issue, PUDA achieves a data augmentation strategy by unifying adversarial training and positive-unlabeled learning under the positive-unlabeled minimax game. Extensive experimental results demonstrate its effectiveness and compatibility.
A Generic Knowledge Based Medical Diagnosis Expert System
Oct 26, 2021
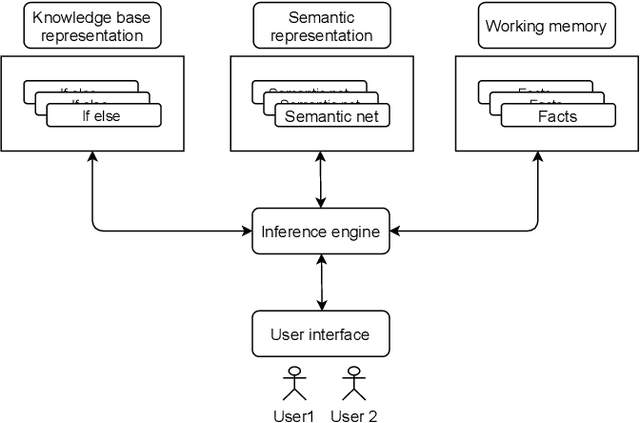
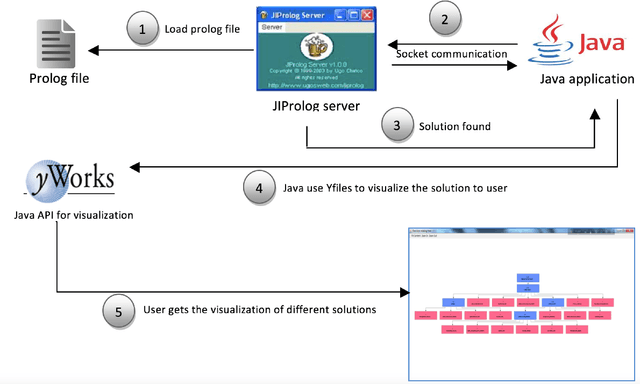
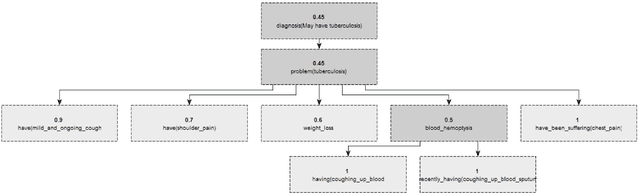
In this paper, we design and implement a generic medical knowledge based system (MKBS) for identifying diseases from several symptoms. In this system, some important aspects like knowledge bases system, knowledge representation, inference engine have been addressed. The system asks users different questions and inference engines will use the certainty factor to prune out low possible solutions. The proposed disease diagnosis system also uses a graphical user interface (GUI) to facilitate users to interact with the expert system. Our expert system is generic and flexible, which can be integrated with any rule bases system in disease diagnosis.