 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion on the Probability Simplex
Sep 12, 2023Diffusion models learn to reverse the progressive noising of a data distribution to create a generative model. However, the desired continuous nature of the noising process can be at odds with discrete data. To deal with this tension between continuous and discrete objects, we propose a method of performing diffusion on the probability simplex. Using the probability simplex naturally creates an interpretation where points correspond to categorical probability distributions. Our method uses the softmax function applied to an Ornstein-Unlenbeck Process, a well-known stochastic differential equation. We find that our methodology also naturally extends to include diffusion on the unit cube which has applications for bounded image generation.
DiffuDetox: A Mixed Diffusion Model for Text Detoxification
Jun 14, 2023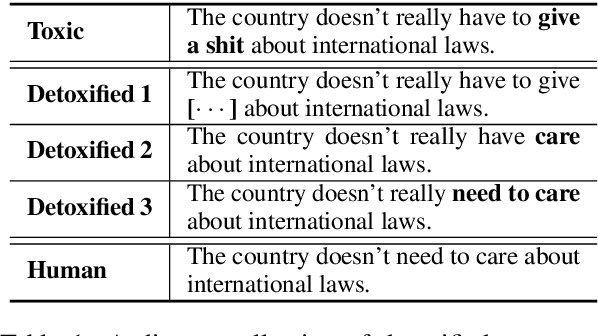
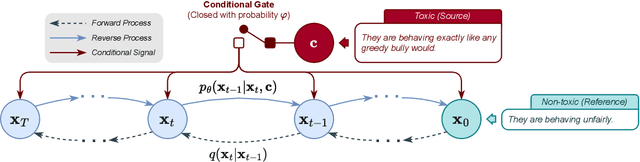
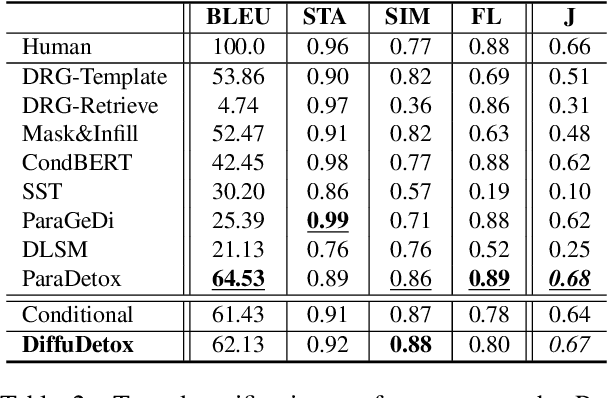
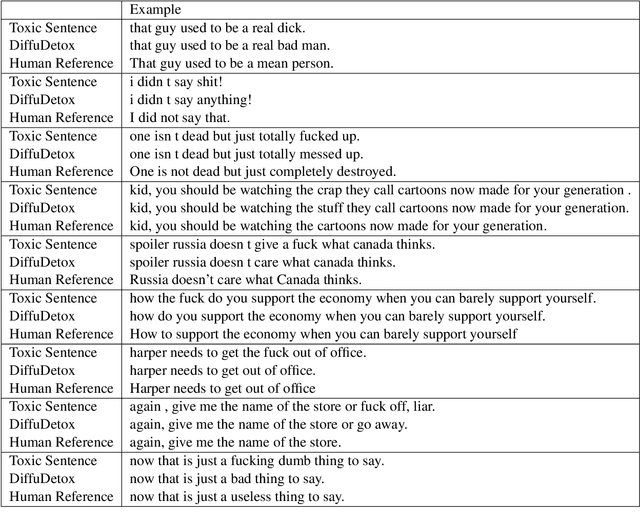
Text detoxification is a conditional text generation task aiming to remove offensive content from toxic text. It is highly useful for online forums and social media, where offensive content is frequently encountered. Intuitively, there are diverse ways to detoxify sentences while preserving their meanings, and we can select from detoxified sentences before displaying text to users. Conditional diffusion models are particularly suitable for this task given their demonstrated higher generative diversity than existing conditional text generation models based on language models. Nonetheless, text fluency declines when they are trained with insufficient data, which is the case for this task. In this work, we propose DiffuDetox, a mixed conditional and unconditional diffusion model for text detoxification. The conditional model takes toxic text as the condition and reduces its toxicity, yielding a diverse set of detoxified sentences. The unconditional model is trained to recover the input text, which allows the introduction of additional fluent text for training and thus ensures text fluency. Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed DiffuDetox.
Bayesian Knowledge-driven Critiquing with Indirect Evidence
Jun 09, 2023



Conversational recommender systems (CRS) enhance the expressivity and personalization of recommendations through multiple turns of user-system interaction. Critiquing is a well-known paradigm for CRS that allows users to iteratively refine recommendations by providing feedback about attributes of recommended items. While existing critiquing methodologies utilize direct attributes of items to address user requests such as 'I prefer Western movies', the opportunity of incorporating richer contextual and side information about items stored in Knowledge Graphs (KG) into the critiquing paradigm has been overlooked. Employing this substantial knowledge together with a well-established reasoning methodology paves the way for critique-based recommenders to allow for complex knowledge-based feedback (e.g., 'I like movies featuring war side effects on veterans') which may arise in natural user-system conversations. In this work, we aim to increase the flexibility of critique-based recommendation by integrating KGs and propose a novel Bayesian inference framework that enables reasoning with relational knowledge-based feedback. We study and formulate the framework considering a Gaussian likelihood and evaluate it on two well-known recommendation datasets with KGs. Our evaluations demonstrate the effectiveness of our framework in leveraging indirect KG-based feedback (i.e., preferred relational properties of items rather than preferred items themselves), often improving personalized recommendations over a one-shot recommender by more than 15%. This work enables a new paradigm for using rich knowledge content and reasoning over indirect evidence as a mechanism for critiquing interactions with CRS.
LogicRec: Recommendation with Users' Logical Requirements
Apr 23, 2023



Users may demand recommendations with highly personalized requirements involving logical operations, e.g., the intersection of two requirements, where such requirements naturally form structured logical queries on knowledge graphs (KGs). To date, existing recommender systems lack the capability to tackle users' complex logical requirements. In this work, we formulate the problem of recommendation with users' logical requirements (LogicRec) and construct benchmark datasets for LogicRec. Furthermore, we propose an initial solution for LogicRec based on logical requirement retrieval and user preference retrieval, where we face two challenges. First, KGs are incomplete in nature. Therefore, there are always missing true facts, which entails that the answers to logical requirements can not be completely found in KGs. In this case, item selection based on the answers to logical queries is not applicable. We thus resort to logical query embedding (LQE) to jointly infer missing facts and retrieve items based on logical requirements. Second, answer sets are under-exploited. Existing LQE methods can only deal with query-answer pairs, where queries in our case are the intersected user preferences and logical requirements. However, the logical requirements and user preferences have different answer sets, offering us richer knowledge about the requirements and preferences by providing requirement-item and preference-item pairs. Thus, we design a multi-task knowledge-sharing mechanism to exploit these answer sets collectively. Extensive experimental results demonstrate the significance of the LogicRec task and the effectiveness of our proposed method.
Exponentially Tilted Gaussian Prior for Variational Autoencoder
Nov 30, 2021


An important propertyfor deep neural networks to possess is the ability to perform robust out of distribution detection (OOD) on previously unseen data. This property is essential for safety purposes when deploying models for real world applications. Recent studies show that probabilistic generative models can perform poorly on this task, which is surprising given that they seek to estimate the likelihood of training data. To alleviate this issue, we propose the exponentially tilted Gaussian prior distribution for the Variational Autoencoder (VAE). With this prior, we are able to achieve state-of-the art results using just the negative log likelihood that the VAE naturally assigns, while being orders of magnitude faster than some competitive methods. We also show that our model produces high quality image samples which are more crisp than that of a standard Gaussian VAE. The new prior distribution has a very simple implementation which uses a Kullback Leibler divergence that compares the difference between a latent vector's length, and the radius of a sphere.