 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight for Right Reasons: Large Language Models for Verifiable Commonsense Knowledge Graph Question Answering
Mar 03, 2024

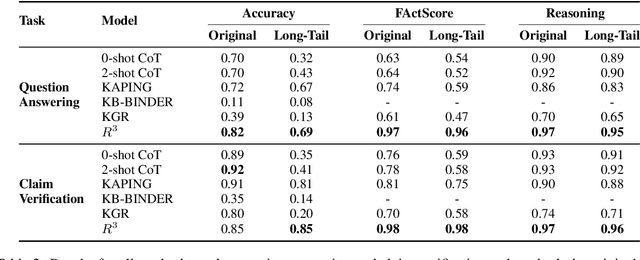

Knowledge Graph Question Answering (KGQA) methods seek to answer Natural Language questions using the relational information stored in Knowledge Graphs (KGs). With the recent advancements of Large Language Models (LLMs) and their remarkable reasoning abilities, there is a growing trend to leverage them for KGQA. However, existing methodologies have only focused on answering factual questions, e.g., "In which city was Silvio Berlusconi's first wife born?", leaving questions involving commonsense reasoning that real-world users may pose more often, e.g., "Do I need separate visas to see the Venus of Willendorf and attend the Olympics this summer?" unaddressed. In this work, we first observe that existing LLM-based methods for KGQA struggle with hallucination on such questions, especially on queries targeting long-tail entities (e.g., non-mainstream and recent entities), thus hindering their applicability in real-world applications especially since their reasoning processes are not easily verifiable. In response, we propose Right for Right Reasons (R3), a commonsense KGQA methodology that allows for a verifiable reasoning procedure by axiomatically surfacing intrinsic commonsense knowledge of LLMs and grounding every factual reasoning step on KG triples. Through experimental evaluations across three different tasks--question answering, claim verification, and preference matching--our findings showcase R3 as a superior approach, outperforming existing methodologies and notably reducing instances of hallucination and reasoning errors.
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.
DiffuDetox: A Mixed Diffusion Model for Text Detoxification
Jun 14, 2023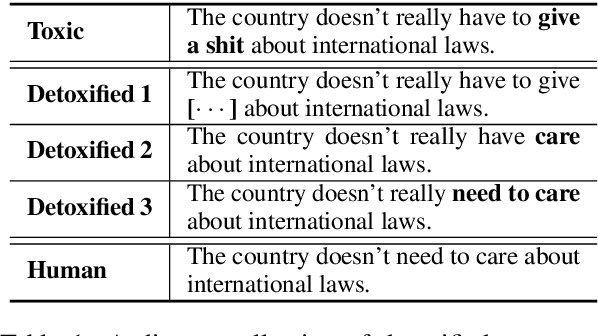
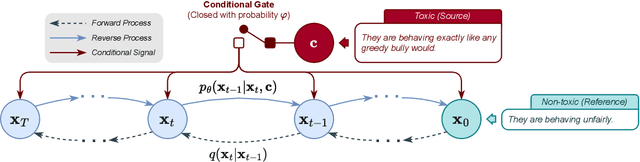
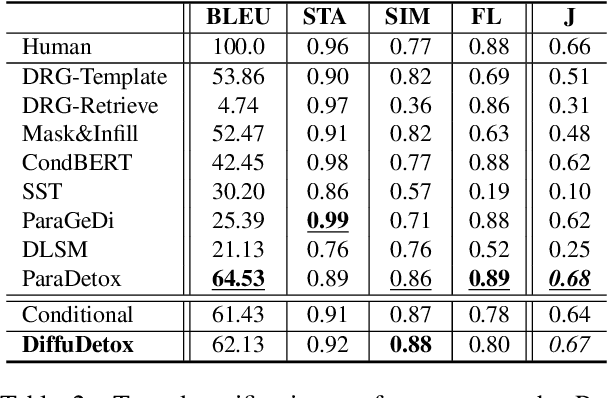
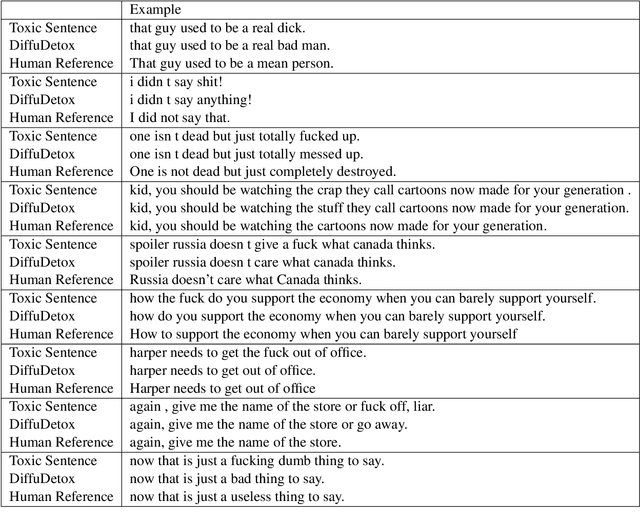
Text detoxification is a conditional text generation task aiming to remove offensive content from toxic text. It is highly useful for online forums and social media, where offensive content is frequently encountered. Intuitively, there are diverse ways to detoxify sentences while preserving their meanings, and we can select from detoxified sentences before displaying text to users. Conditional diffusion models are particularly suitable for this task given their demonstrated higher generative diversity than existing conditional text generation models based on language models. Nonetheless, text fluency declines when they are trained with insufficient data, which is the case for this task. In this work, we propose DiffuDetox, a mixed conditional and unconditional diffusion model for text detoxification. The conditional model takes toxic text as the condition and reduces its toxicity, yielding a diverse set of detoxified sentences. The unconditional model is trained to recover the input text, which allows the introduction of additional fluent text for training and thus ensures text fluency. Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed DiffuDetox.