 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLoTa: A Dataset for Entity-based Commonsense Reasoning over Long-Tail Knowledge
Apr 20, 2025The rise of Large Language Models (LLMs) has redefined the AI landscape, particularly due to their ability to encode factual and commonsense knowledge, and their outstanding performance in tasks requiring reasoning. Despite these advances, hallucinations and reasoning errors remain a significant barrier to their deployment in high-stakes settings. In this work, we observe that even the most prominent LLMs, such as OpenAI-o1, suffer from high rates of reasoning errors and hallucinations on tasks requiring commonsense reasoning over obscure, long-tail entities. To investigate this limitation, we present a new dataset for Commonsense reasoning over Long-Tail entities (CoLoTa), that consists of 3,300 queries from question answering and claim verification tasks and covers a diverse range of commonsense reasoning skills. We remark that CoLoTa can also serve as a Knowledge Graph Question Answering (KGQA) dataset since the support of knowledge required to answer its queries is present in the Wikidata knowledge graph. However, as opposed to existing KGQA benchmarks that merely focus on factoid questions, our CoLoTa queries also require commonsense reasoning. Our experiments with strong LLM-based KGQA methodologies indicate their severe inability to answer queries involving commonsense reasoning. Hence, we propose CoLoTa as a novel benchmark for assessing both (i) LLM commonsense reasoning capabilities and their robustness to hallucinations on long-tail entities and (ii) the commonsense reasoning capabilities of KGQA methods.
CR-LT-KGQA: A Knowledge Graph Question Answering Dataset Requiring Commonsense Reasoning and Long-Tail Knowledge
Mar 03, 2024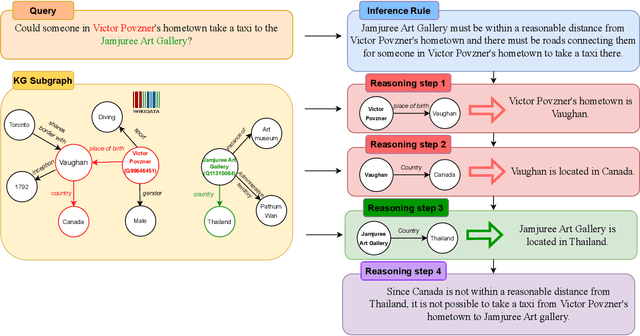

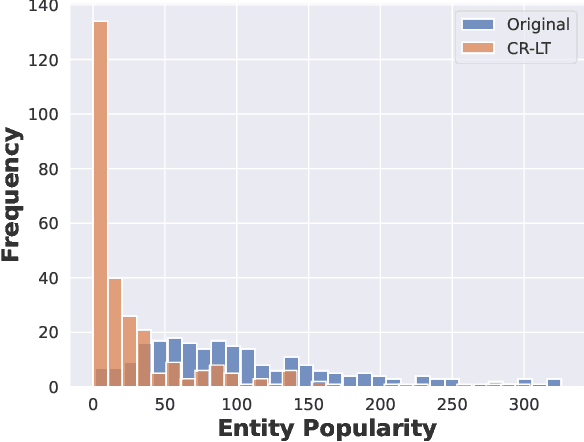

Knowledge graph question answering (KGQA) is a well-established field that seeks to provide factual answers to natural language (NL) questions by leveraging knowledge graphs (KGs). However, existing KGQA datasets suffer from two significant limitations: (1) no existing KGQA dataset requires commonsense reasoning to arrive at an answer and (2) existing KGQA datasets focus on popular entities for which large language models (LLMs) can directly answer without hallucinating and without leveraging the KG. In this work, we seek a novel KGQA dataset that supports commonsense reasoning and focuses on long-tail entities (e.g., non-mainstream and recent entities) where LLMs frequently hallucinate, and thus create the need for novel methodologies that leverage the KG for factual and attributable commonsense inference. We create a novel Commonsense Reasoning (CR) and Long-Tail (LT) KGQA dataset with two subtasks -- question answering and claim verification -- that address both limitations (1) and (2). We construct CR-LT-KGQA by building extensions to existing reasoning datasets StrategyQA and CREAK over Wikidata. While existing KGQA methods are not applicable due to their lack of commonsense inference support, baseline evaluation of LLMs on CR-LT KGQA demonstrate a high rate of hallucination. Thus, CR-LT KGQA poses significant challenges for hallucination-prone LLMs, hence paving the way for future commonsense KGQA research to provide accurate and factual answers for long-tail entities in the era of LLMs.
Right for Right Reasons: Large Language Models for Verifiable Commonsense Knowledge Graph Question Answering
Mar 03, 2024

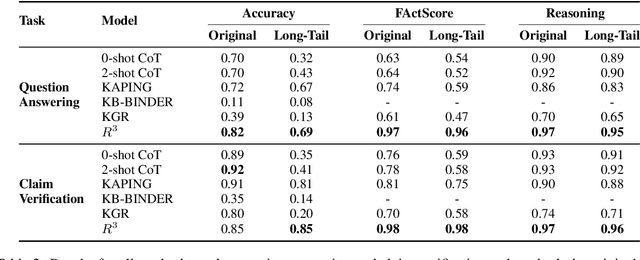

Knowledge Graph Question Answering (KGQA) methods seek to answer Natural Language questions using the relational information stored in Knowledge Graphs (KGs). With the recent advancements of Large Language Models (LLMs) and their remarkable reasoning abilities, there is a growing trend to leverage them for KGQA. However, existing methodologies have only focused on answering factual questions, e.g., "In which city was Silvio Berlusconi's first wife born?", leaving questions involving commonsense reasoning that real-world users may pose more often, e.g., "Do I need separate visas to see the Venus of Willendorf and attend the Olympics this summer?" unaddressed. In this work, we first observe that existing LLM-based methods for KGQA struggle with hallucination on such questions, especially on queries targeting long-tail entities (e.g., non-mainstream and recent entities), thus hindering their applicability in real-world applications especially since their reasoning processes are not easily verifiable. In response, we propose Right for Right Reasons (R3), a commonsense KGQA methodology that allows for a verifiable reasoning procedure by axiomatically surfacing intrinsic commonsense knowledge of LLMs and grounding every factual reasoning step on KG triples. Through experimental evaluations across three different tasks--question answering, claim verification, and preference matching--our findings showcase R3 as a superior approach, outperforming existing methodologies and notably reducing instances of hallucination and reasoning errors.