 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Order Matters for Agentic Memory: Segment Trees for Long-Horizon Agents
Jun 03, 2026Long-horizon conversational agents need to interact with users through evolving events, tasks, and goals. Such histories are naturally temporal, yet many existing memory systems organize information primarily by topical similarity and may ignore the order in which events occur. We introduce Segment Tree Memory, or SegTreeMem, a memory architecture that represents conversation history as a temporally ordered Segment Tree over utterances. SegTreeMem incrementally inserts new utterances through an online rightmost-frontier update rule, preserving chronological order while forming hierarchical memory segments. For retrieval, SegTreeMem propagates relevance scores through the tree to combine local semantic matching with hierarchical temporal context. Across three long-horizon memory benchmarks and two LLM backbones, SegTreeMem improves answer quality over flat retrieval, graph-structured memory, and tree-structured memory baselines. Additional temporal-order permutation analysis shows that the performance gain depends on preserving temporal order during memory construction, supporting the claim that temporal order is a key structure for agentic memory.
CommonWhy: A Dataset for Evaluating Entity-Based Causal Commonsense Reasoning in Large Language Models
May 13, 2026To effectively interact with the real world, Large Language Models (LLMs) require entity-based commonsense reasoning, a challenging task that necessitates integrating factual knowledge about specific entities with commonsense inference. Existing datasets for evaluating LLM entity-based commonsense reasoning have largely focused on True/False or multiple-choice questions, leaving the explicit assessment of the model's ability in abductive reasoning about causes and effects and generating explanations largely unexamined. In this work, we introduce CommonWhy, a dataset of 15,000 why questions designed to evaluate entity-based commonsense reasoning about causal relationships in LLMs. CommonWhy also serves as a Knowledge Graph Question Answering (KGQA) benchmark, as all supporting knowledge required to answer its queries is available in the Wikidata knowledge graph. Unlike existing KGQA datasets, which primarily test fact retrieval, CommonWhy targets causal commonsense reasoning, establishing a new paradigm for KGQA evaluation. Experiments with state-of-the-art LLMs and LLM-based KGQA methods reveal their significant shortcomings, including frequent factual hallucinations and failures in causal reasoning.
Goal-Oriented Reasoning for RAG-based Memory in Conversational Agentic LLM Systems
May 12, 2026LLM-based conversational AI agents struggle to maintain coherent behavior over long horizons due to limited context. While RAG-based approaches are increasingly adopted to overcome this limitation by storing interactions in external memory modules and performing retrieval from them, their effectiveness in answering challenging questions (e.g., multi-hop, commonsense) ultimately depends on the agent's ability to reason over the retrieved information. However, existing methods typically retrieve memory based on semantic similarity to the raw user utterance, which lacks explicit reasoning about missing intermediate facts and often returns evidence that is irrelevant or insufficient for grounded reasoning. In this work, we introduce Goal-Mem, a goal-oriented reasoning framework for RAG-based agentic memory that performs explicit backward chaining from the user's utterance as a goal. Rather than progressively expanding from retrieved context, Goal-Mem decomposes each goal into atomic subgoals, performs targeted memory retrieval to satisfy each subgoal, and iteratively identifies what information from memory should be retrieved when intermediate goals cannot be resolved. We formalize this process in Natural Language Logic, a logical system that combines the verifiability of reasoning provided by FOL with the expressivity of natural language. Through extensive experiments on two datasets and comparing to nine strong memory baselines, we show that Goal-Mem consistently improves performance, particularly on tasks requiring multi-hop reasoning and implicit inference.
Semantic XPath: Structured Agentic Memory Access for Conversational AI
Mar 01, 2026Conversational AI (ConvAI) agents increasingly maintain structured memory to support long-term, task-oriented interactions. In-context memory approaches append the growing history to the model input, which scales poorly under context-window limits. RAG-based methods retrieve request-relevant information, but most assume flat memory collections and ignore structure. We propose Semantic XPath, a tree-structured memory module to access and update structured conversational memory. Semantic XPath improves performance over flat-RAG baselines by 176.7% while using only 9.1% of the tokens required by in-context memory. We also introduce SemanticXPath Chat, an end-to-end ConvAI demo system that visualizes the structured memory and query execution details. Overall, this paper demonstrates a candidate for the next generation of long-term, task-oriented ConvAI systems built on structured memory.
CoLoTa: A Dataset for Entity-based Commonsense Reasoning over Long-Tail Knowledge
Apr 20, 2025The rise of Large Language Models (LLMs) has redefined the AI landscape, particularly due to their ability to encode factual and commonsense knowledge, and their outstanding performance in tasks requiring reasoning. Despite these advances, hallucinations and reasoning errors remain a significant barrier to their deployment in high-stakes settings. In this work, we observe that even the most prominent LLMs, such as OpenAI-o1, suffer from high rates of reasoning errors and hallucinations on tasks requiring commonsense reasoning over obscure, long-tail entities. To investigate this limitation, we present a new dataset for Commonsense reasoning over Long-Tail entities (CoLoTa), that consists of 3,300 queries from question answering and claim verification tasks and covers a diverse range of commonsense reasoning skills. We remark that CoLoTa can also serve as a Knowledge Graph Question Answering (KGQA) dataset since the support of knowledge required to answer its queries is present in the Wikidata knowledge graph. However, as opposed to existing KGQA benchmarks that merely focus on factoid questions, our CoLoTa queries also require commonsense reasoning. Our experiments with strong LLM-based KGQA methodologies indicate their severe inability to answer queries involving commonsense reasoning. Hence, we propose CoLoTa as a novel benchmark for assessing both (i) LLM commonsense reasoning capabilities and their robustness to hallucinations on long-tail entities and (ii) the commonsense reasoning capabilities of KGQA methods.
A Comprehensive Review of Recommender Systems: Transitioning from Theory to Practice
Jul 18, 2024



Recommender Systems (RS) play an integral role in enhancing user experiences by providing personalized item suggestions. This survey reviews the progress in RS inclusively from 2017 to 2024, effectively connecting theoretical advances with practical applications. We explore the development from traditional RS techniques like content-based and collaborative filtering to advanced methods involving deep learning, graph-based models, reinforcement learning, and large language models. We also discuss specialized systems such as context-aware, review-based, and fairness-aware RS. The primary goal of this survey is to bridge theory with practice. It addresses challenges across various sectors, including e-commerce, healthcare, and finance, emphasizing the need for scalable, real-time, and trustworthy solutions. Through this survey, we promote stronger partnerships between academic research and industry practices. The insights offered by this survey aim to guide industry professionals in optimizing RS deployment and to inspire future research directions, especially in addressing emerging technological and societal trends
Bayesian Optimization with LLM-Based Acquisition Functions for Natural Language Preference Elicitation
May 02, 2024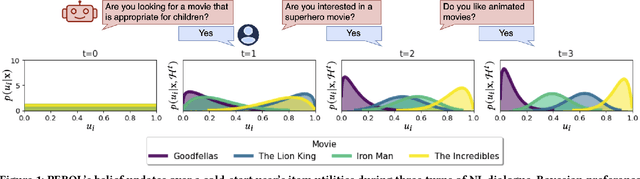
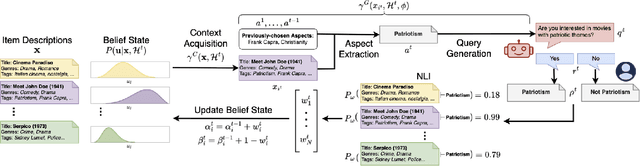
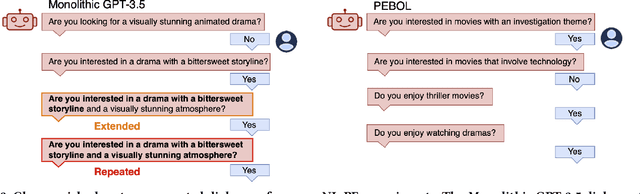

Designing preference elicitation (PE) methodologies that can quickly ascertain a user's top item preferences in a cold-start setting is a key challenge for building effective and personalized conversational recommendation (ConvRec) systems. While large language models (LLMs) constitute a novel technology that enables fully natural language (NL) PE dialogues, we hypothesize that monolithic LLM NL-PE approaches lack the multi-turn, decision-theoretic reasoning required to effectively balance the NL exploration and exploitation of user preferences towards an arbitrary item set. In contrast, traditional Bayesian optimization PE methods define theoretically optimal PE strategies, but fail to use NL item descriptions or generate NL queries, unrealistically assuming users can express preferences with direct item ratings and comparisons. To overcome the limitations of both approaches, we formulate NL-PE in a Bayesian Optimization (BO) framework that seeks to generate NL queries which actively elicit natural language feedback to reduce uncertainty over item utilities to identify the best recommendation. We demonstrate our framework in a novel NL-PE algorithm, PEBOL, which uses Natural Language Inference (NLI) between user preference utterances and NL item descriptions to maintain preference beliefs and BO strategies such as Thompson Sampling (TS) and Upper Confidence Bound (UCB) to guide LLM query generation. We numerically evaluate our methods in controlled experiments, finding that PEBOL achieves up to 131% improvement in MAP@10 after 10 turns of cold start NL-PE dialogue compared to monolithic GPT-3.5, despite relying on a much smaller 400M parameter NLI model for preference inference.
CR-LT-KGQA: A Knowledge Graph Question Answering Dataset Requiring Commonsense Reasoning and Long-Tail Knowledge
Mar 03, 2024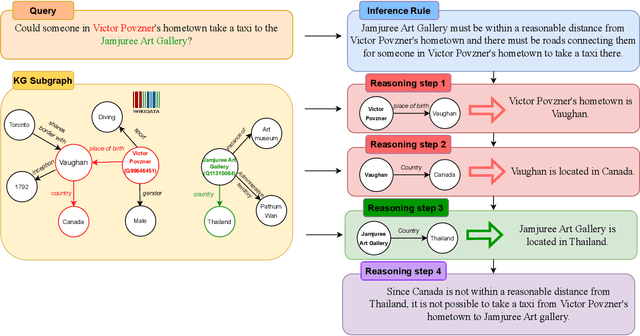

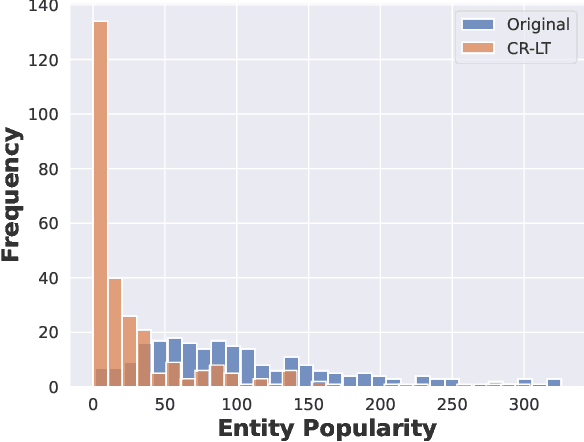

Knowledge graph question answering (KGQA) is a well-established field that seeks to provide factual answers to natural language (NL) questions by leveraging knowledge graphs (KGs). However, existing KGQA datasets suffer from two significant limitations: (1) no existing KGQA dataset requires commonsense reasoning to arrive at an answer and (2) existing KGQA datasets focus on popular entities for which large language models (LLMs) can directly answer without hallucinating and without leveraging the KG. In this work, we seek a novel KGQA dataset that supports commonsense reasoning and focuses on long-tail entities (e.g., non-mainstream and recent entities) where LLMs frequently hallucinate, and thus create the need for novel methodologies that leverage the KG for factual and attributable commonsense inference. We create a novel Commonsense Reasoning (CR) and Long-Tail (LT) KGQA dataset with two subtasks -- question answering and claim verification -- that address both limitations (1) and (2). We construct CR-LT-KGQA by building extensions to existing reasoning datasets StrategyQA and CREAK over Wikidata. While existing KGQA methods are not applicable due to their lack of commonsense inference support, baseline evaluation of LLMs on CR-LT KGQA demonstrate a high rate of hallucination. Thus, CR-LT KGQA poses significant challenges for hallucination-prone LLMs, hence paving the way for future commonsense KGQA research to provide accurate and factual answers for long-tail entities in the era of LLMs.
Right for Right Reasons: Large Language Models for Verifiable Commonsense Knowledge Graph Question Answering
Mar 03, 2024

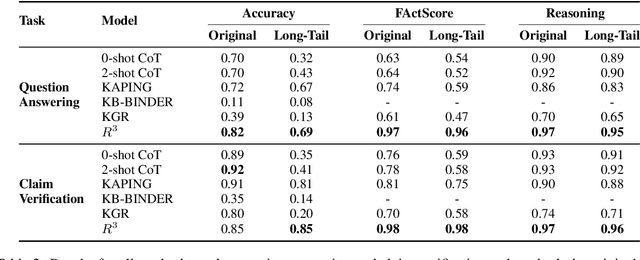

Knowledge Graph Question Answering (KGQA) methods seek to answer Natural Language questions using the relational information stored in Knowledge Graphs (KGs). With the recent advancements of Large Language Models (LLMs) and their remarkable reasoning abilities, there is a growing trend to leverage them for KGQA. However, existing methodologies have only focused on answering factual questions, e.g., "In which city was Silvio Berlusconi's first wife born?", leaving questions involving commonsense reasoning that real-world users may pose more often, e.g., "Do I need separate visas to see the Venus of Willendorf and attend the Olympics this summer?" unaddressed. In this work, we first observe that existing LLM-based methods for KGQA struggle with hallucination on such questions, especially on queries targeting long-tail entities (e.g., non-mainstream and recent entities), thus hindering their applicability in real-world applications especially since their reasoning processes are not easily verifiable. In response, we propose Right for Right Reasons (R3), a commonsense KGQA methodology that allows for a verifiable reasoning procedure by axiomatically surfacing intrinsic commonsense knowledge of LLMs and grounding every factual reasoning step on KG triples. Through experimental evaluations across three different tasks--question answering, claim verification, and preference matching--our findings showcase R3 as a superior approach, outperforming existing methodologies and notably reducing instances of hallucination and reasoning errors.
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.