 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatched Self-Consistency Improves LLM Relevance Assessment and Ranking
May 18, 2025Given some information need, Large Language Models (LLMs) are increasingly used for candidate text relevance assessment, typically using a one-by-one pointwise (PW) strategy where each LLM call evaluates one candidate at a time. Meanwhile, it has been shown that LLM performance can be improved through self-consistency: prompting the LLM to do the same task multiple times (possibly in perturbed ways) and then aggregating the responses. To take advantage of self-consistency, we hypothesize that batched PW strategies, where multiple passages are judged in one LLM call, are better suited than one-by-one PW methods since a larger input context can induce more diverse LLM sampling across self-consistency calls. We first propose several candidate batching strategies to create prompt diversity across self-consistency calls through subset reselection and permutation. We then test our batched PW methods on relevance assessment and ranking tasks against one-by-one PW and listwise LLM ranking baselines with and without self-consistency, using three passage retrieval datasets and GPT-4o, Claude Sonnet 3, and Amazon Nova Pro. We find that batched PW methods outperform all baselines, and show that batching can greatly amplify the positive effects of self-consistency. For instance, on our legal search dataset, GPT-4o one-by-one PW ranking NDCG@10 improves only from 44.9% to 46.8% without self-consistency vs. with 15 self consistency calls, while batched PW ranking improves from 43.8% to 51.3%, respectively.
Elaborative Subtopic Query Reformulation for Broad and Indirect Queries in Travel Destination Recommendation
Oct 02, 2024In Query-driven Travel Recommender Systems (RSs), it is crucial to understand the user intent behind challenging natural language(NL) destination queries such as the broadly worded "youth-friendly activities" or the indirect description "a high school graduation trip". Such queries are challenging due to the wide scope and subtlety of potential user intents that confound the ability of retrieval methods to infer relevant destinations from available textual descriptions such as WikiVoyage. While query reformulation (QR) has proven effective in enhancing retrieval by addressing user intent, existing QR methods tend to focus only on expanding the range of potentially matching query subtopics (breadth) or elaborating on the potential meaning of a query (depth), but not both. In this paper, we introduce Elaborative Subtopic Query Reformulation (EQR), a large language model-based QR method that combines both breadth and depth by generating potential query subtopics with information-rich elaborations. We also release TravelDest, a novel dataset for query-driven travel destination RSs. Experiments on TravelDest show that EQR achieves significant improvements in recall and precision over existing state-of-the-art QR methods.
Multi-modal Generative Models in Recommendation System
Sep 17, 2024



Many recommendation systems limit user inputs to text strings or behavior signals such as clicks and purchases, and system outputs to a list of products sorted by relevance. With the advent of generative AI, users have come to expect richer levels of interactions. In visual search, for example, a user may provide a picture of their desired product along with a natural language modification of the content of the picture (e.g., a dress like the one shown in the picture but in red color). Moreover, users may want to better understand the recommendations they receive by visualizing how the product fits their use case, e.g., with a representation of how a garment might look on them, or how a furniture item might look in their room. Such advanced levels of interaction require recommendation systems that are able to discover both shared and complementary information about the product across modalities, and visualize the product in a realistic and informative way. However, existing systems often treat multiple modalities independently: text search is usually done by comparing the user query to product titles and descriptions, while visual search is typically done by comparing an image provided by the customer to product images. We argue that future recommendation systems will benefit from a multi-modal understanding of the products that leverages the rich information retailers have about both customers and products to come up with the best recommendations. In this chapter we review recommendation systems that use multiple data modalities simultaneously.
Large Language Model Driven Recommendation
Aug 20, 2024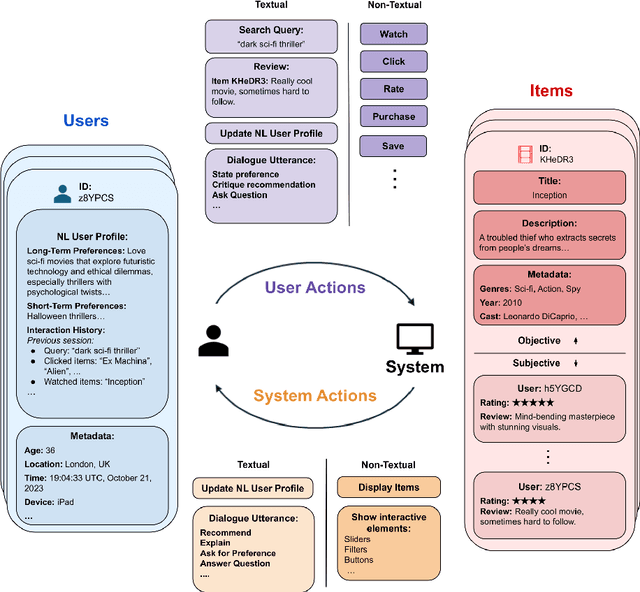
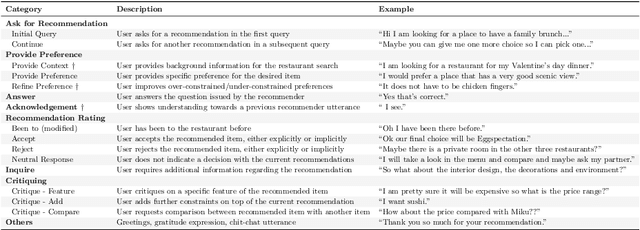
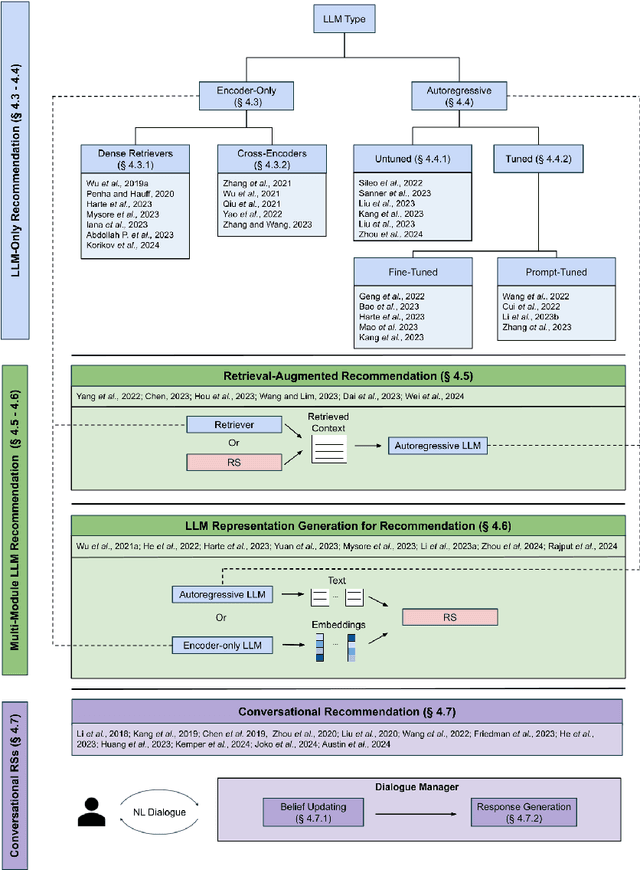

While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Multi-Aspect Reviewed-Item Retrieval via LLM Query Decomposition and Aspect Fusion
Aug 01, 2024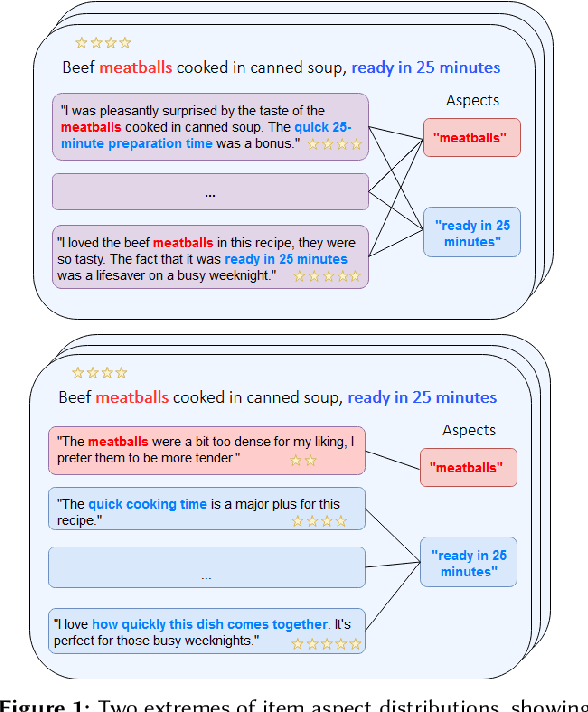
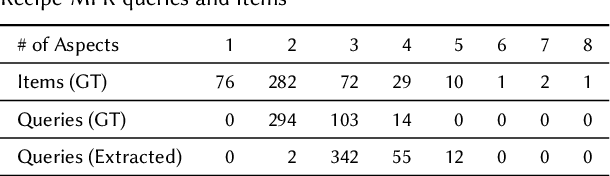
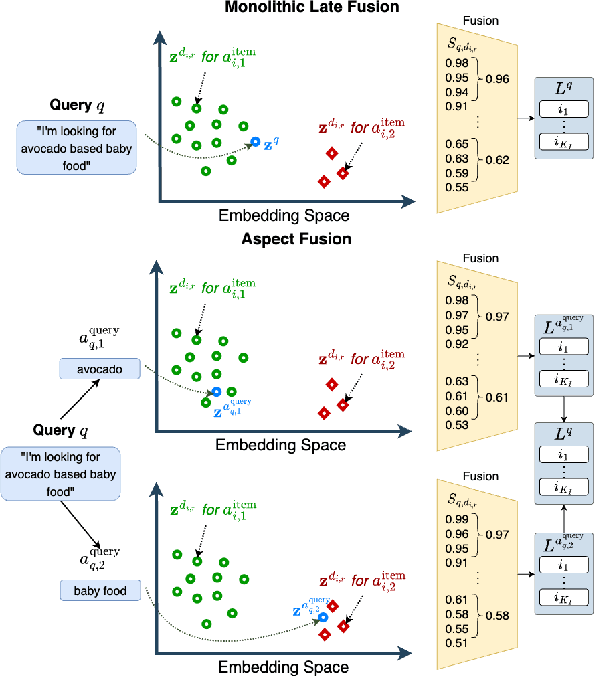
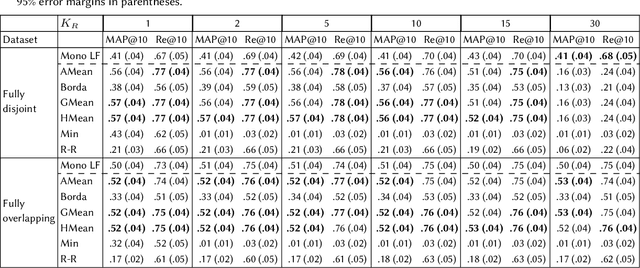
While user-generated product reviews often contain large quantities of information, their utility in addressing natural language product queries has been limited, with a key challenge being the need to aggregate information from multiple low-level sources (reviews) to a higher item level during retrieval. Existing methods for reviewed-item retrieval (RIR) typically take a late fusion (LF) approach which computes query-item scores by simply averaging the top-K query-review similarity scores for an item. However, we demonstrate that for multi-aspect queries and multi-aspect items, LF is highly sensitive to the distribution of aspects covered by reviews in terms of aspect frequency and the degree of aspect separation across reviews. To address these LF failures, we propose several novel aspect fusion (AF) strategies which include Large Language Model (LLM) query extraction and generative reranking. Our experiments show that for imbalanced review corpora, AF can improve over LF by a MAP@10 increase from 0.36 to 0.52, while achieving equivalent performance for balanced review corpora.
Retrieval-Augmented Conversational Recommendation with Prompt-based Semi-Structured Natural Language State Tracking
May 25, 2024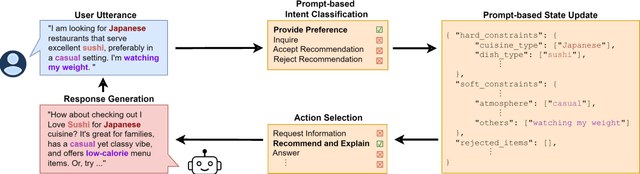
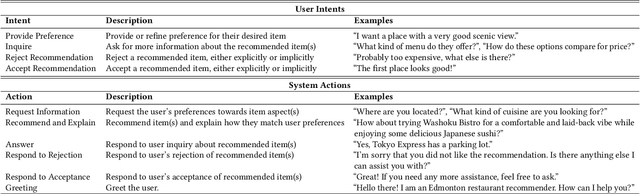
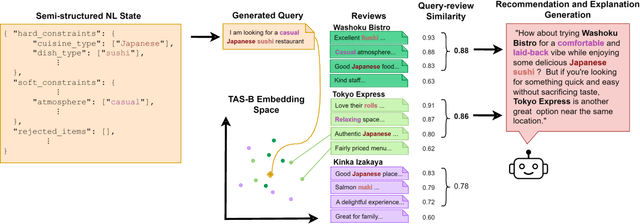

Conversational recommendation (ConvRec) systems must understand rich and diverse natural language (NL) expressions of user preferences and intents, often communicated in an indirect manner (e.g., "I'm watching my weight"). Such complex utterances make retrieving relevant items challenging, especially if only using often incomplete or out-of-date metadata. Fortunately, many domains feature rich item reviews that cover standard metadata categories and offer complex opinions that might match a user's interests (e.g., "classy joint for a date"). However, only recently have large language models (LLMs) let us unlock the commonsense connections between user preference utterances and complex language in user-generated reviews. Further, LLMs enable novel paradigms for semi-structured dialogue state tracking, complex intent and preference understanding, and generating recommendations, explanations, and question answers. We thus introduce a novel technology RA-Rec, a Retrieval-Augmented, LLM-driven dialogue state tracking system for ConvRec, showcased with a video, open source GitHub repository, and interactive Google Colab notebook.
Bayesian Optimization with LLM-Based Acquisition Functions for Natural Language Preference Elicitation
May 02, 2024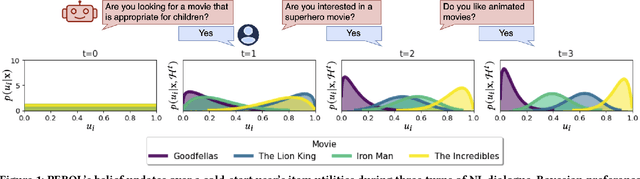
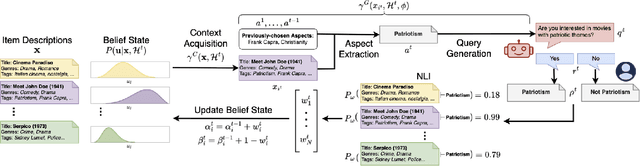
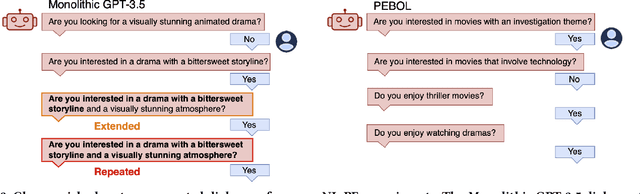

Designing preference elicitation (PE) methodologies that can quickly ascertain a user's top item preferences in a cold-start setting is a key challenge for building effective and personalized conversational recommendation (ConvRec) systems. While large language models (LLMs) constitute a novel technology that enables fully natural language (NL) PE dialogues, we hypothesize that monolithic LLM NL-PE approaches lack the multi-turn, decision-theoretic reasoning required to effectively balance the NL exploration and exploitation of user preferences towards an arbitrary item set. In contrast, traditional Bayesian optimization PE methods define theoretically optimal PE strategies, but fail to use NL item descriptions or generate NL queries, unrealistically assuming users can express preferences with direct item ratings and comparisons. To overcome the limitations of both approaches, we formulate NL-PE in a Bayesian Optimization (BO) framework that seeks to generate NL queries which actively elicit natural language feedback to reduce uncertainty over item utilities to identify the best recommendation. We demonstrate our framework in a novel NL-PE algorithm, PEBOL, which uses Natural Language Inference (NLI) between user preference utterances and NL item descriptions to maintain preference beliefs and BO strategies such as Thompson Sampling (TS) and Upper Confidence Bound (UCB) to guide LLM query generation. We numerically evaluate our methods in controlled experiments, finding that PEBOL achieves up to 131% improvement in MAP@10 after 10 turns of cold start NL-PE dialogue compared to monolithic GPT-3.5, despite relying on a much smaller 400M parameter NLI model for preference inference.
A Review of Modern Recommender Systems Using Generative Models
Mar 31, 2024

Traditional recommender systems (RS) have used user-item rating histories as their primary data source, with collaborative filtering being one of the principal methods. However, generative models have recently developed abilities to model and sample from complex data distributions, including not only user-item interaction histories but also text, images, and videos - unlocking this rich data for novel recommendation tasks. Through this comprehensive and multi-disciplinary survey, we aim to connect the key advancements in RS using Generative Models (Gen-RecSys), encompassing: a foundational overview of interaction-driven generative models; the application of large language models (LLM) for generative recommendation, retrieval, and conversational recommendation; and the integration of multimodal models for processing and generating image and video content in RS. Our holistic perspective allows us to highlight necessary paradigms for evaluating the impact and harm of Gen-RecSys and identify open challenges. A more up-to-date version of the papers is maintained at: https://github.com/yasdel/LLM-RecSys.
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.