 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn harmony with gpt-oss
Apr 01, 2026No one has independently reproduced OpenAI's published scores for gpt-oss-20b with tools, because the original paper discloses neither the tools nor the agent harness. We reverse-engineered the model's in-distribution tools: when prompted without tool definitions, gpt-oss still calls tools from its training distribution with high statistical confidence -- a strong prior, not a hallucination. We then built a native harmony agent harness (https://github.com/borislavmavrin/harmonyagent.git) that encodes messages in the model's native format, bypassing the lossy Chat Completions conversion. Together, these yield the first independent reproduction of OpenAI's published scores: 60.4% on SWE Verified HIGH (published 60.7%), 53.3% MEDIUM (53.2%), and 91.7% on AIME25 with tools (90.4%).
Self-Supervised Contrastive BERT Fine-tuning for Fusion-based Reviewed-Item Retrieval
Aug 01, 2023As natural language interfaces enable users to express increasingly complex natural language queries, there is a parallel explosion of user review content that can allow users to better find items such as restaurants, books, or movies that match these expressive queries. While Neural Information Retrieval (IR) methods have provided state-of-the-art results for matching queries to documents, they have not been extended to the task of Reviewed-Item Retrieval (RIR), where query-review scores must be aggregated (or fused) into item-level scores for ranking. In the absence of labeled RIR datasets, we extend Neural IR methodology to RIR by leveraging self-supervised methods for contrastive learning of BERT embeddings for both queries and reviews. Specifically, contrastive learning requires a choice of positive and negative samples, where the unique two-level structure of our item-review data combined with meta-data affords us a rich structure for the selection of these samples. For contrastive learning in a Late Fusion scenario, we investigate the use of positive review samples from the same item and/or with the same rating, selection of hard positive samples by choosing the least similar reviews from the same anchor item, and selection of hard negative samples by choosing the most similar reviews from different items. We also explore anchor sub-sampling and augmenting with meta-data. For a more end-to-end Early Fusion approach, we introduce contrastive item embedding learning to fuse reviews into single item embeddings. Experimental results show that Late Fusion contrastive learning for Neural RIR outperforms all other contrastive IR configurations, Neural IR, and sparse retrieval baselines, thus demonstrating the power of exploiting the two-level structure in Neural RIR approaches as well as the importance of preserving the nuance of individual review content via Late Fusion methods.
Efficient decorrelation of features using Gramian in Reinforcement Learning
Nov 19, 2019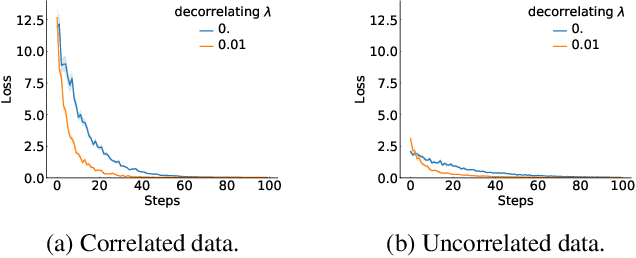

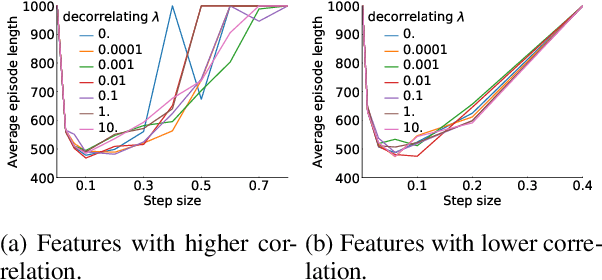
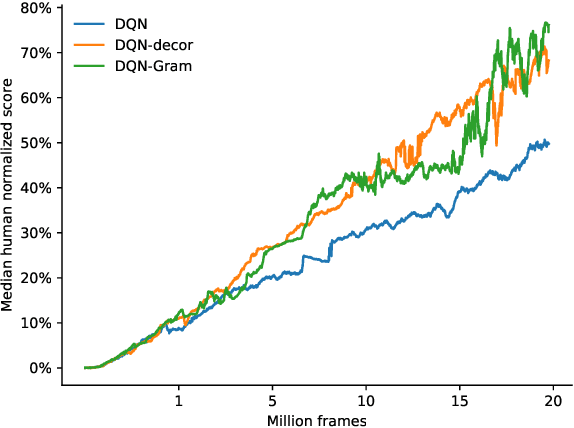
Learning good representations is a long standing problem in reinforcement learning (RL). One of the conventional ways to achieve this goal in the supervised setting is through regularization of the parameters. Extending some of these ideas to the RL setting has not yielded similar improvements in learning. In this paper, we develop an online regularization framework for decorrelating features in RL and demonstrate its utility in several test environments. We prove that the proposed algorithm converges in the linear function approximation setting and does not change the main objective of maximizing cumulative reward. We demonstrate how to scale the approach to deep RL using the Gramian of the features achieving linear computational complexity in the number of features and squared complexity in size of the batch. We conduct an extensive empirical study of the new approach on Atari 2600 games and show a significant improvement in sample efficiency in 40 out of 49 games.
Distributional Reinforcement Learning for Efficient Exploration
May 13, 2019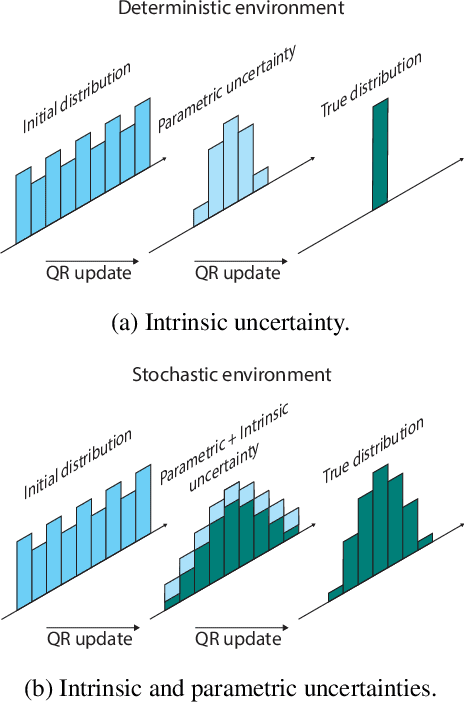
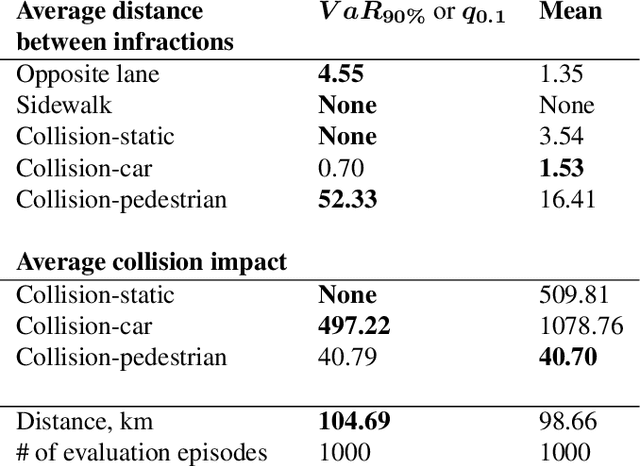
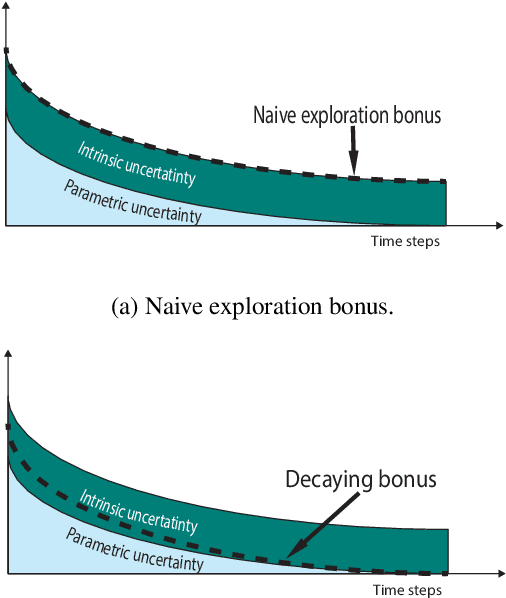
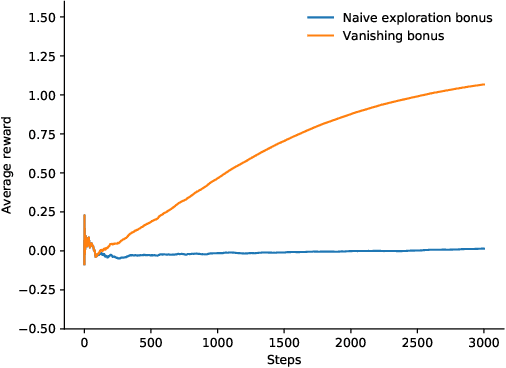
In distributional reinforcement learning (RL), the estimated distribution of value function models both the parametric and intrinsic uncertainties. We propose a novel and efficient exploration method for deep RL that has two components. The first is a decaying schedule to suppress the intrinsic uncertainty. The second is an exploration bonus calculated from the upper quantiles of the learned distribution. In Atari 2600 games, our method outperforms QR-DQN in 12 out of 14 hard games (achieving 483 \% average gain across 49 games in cumulative rewards over QR-DQN with a big win in Venture). We also compared our algorithm with QR-DQN in a challenging 3D driving simulator (CARLA). Results show that our algorithm achieves near-optimal safety rewards twice faster than QRDQN.
Deep Reinforcement Learning with Decorrelation
Mar 18, 2019

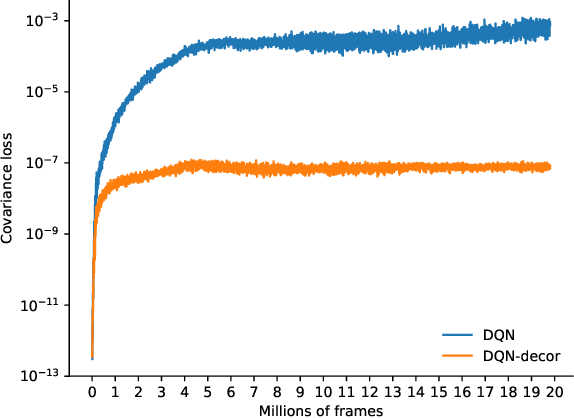
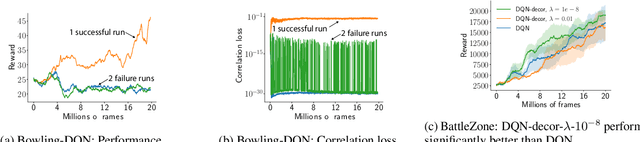
Learning an effective representation for high-dimensional data is a challenging problem in reinforcement learning (RL). Deep reinforcement learning (DRL) such as Deep Q networks (DQN) achieves remarkable success in computer games by learning deeply encoded representation from convolution networks. In this paper, we propose a simple yet very effective method for representation learning with DRL algorithms. Our key insight is that features learned by DRL algorithms are highly correlated, which interferes with learning. By adding a regularized loss that penalizes correlation in latent features (with only slight computation), we decorrelate features represented by deep neural networks incrementally. On 49 Atari games, with the same regularization factor, our decorrelation algorithms perform $70\%$ in terms of human-normalized scores, which is $40\%$ better than DQN. In particular, ours performs better than DQN on 39 games with 4 close ties and lost only slightly on $6$ games. Empirical results also show that the decorrelation method applies to Quantile Regression DQN (QR-DQN) and significantly boosts performance. Further experiments on the losing games show that our decorelation algorithms can win over DQN and QR-DQN with a fined tuned regularization factor.
QUOTA: The Quantile Option Architecture for Reinforcement Learning
Nov 07, 2018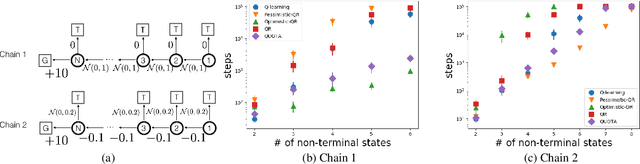
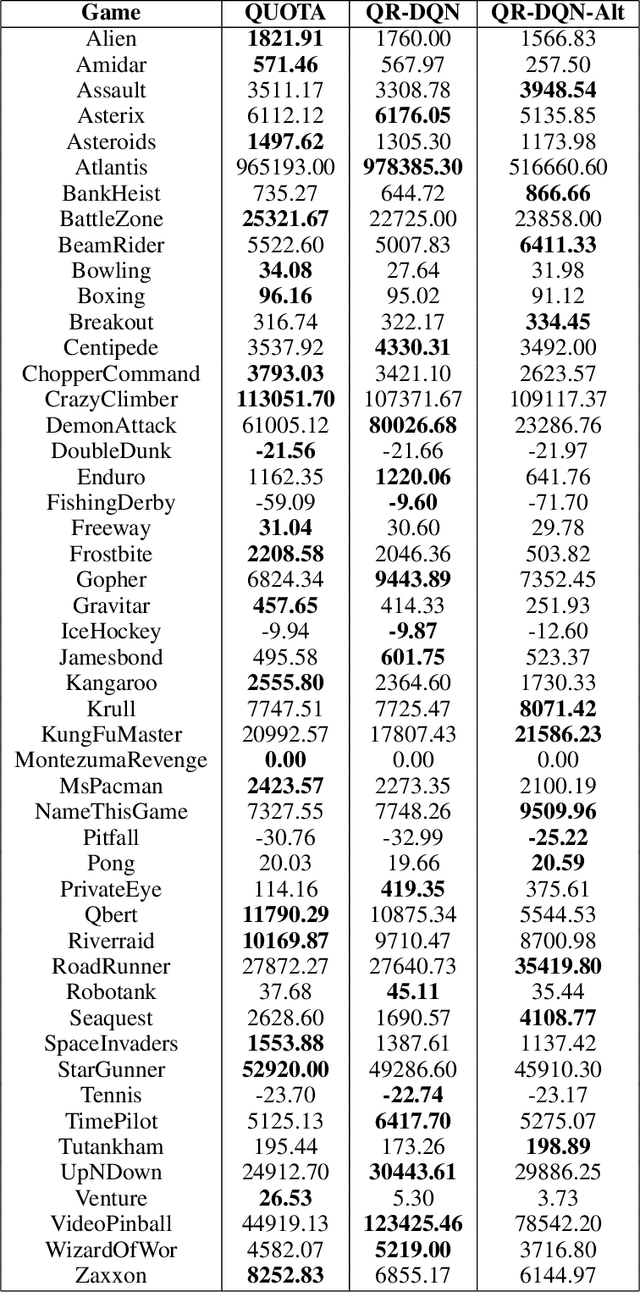


In this paper, we propose the Quantile Option Architecture (QUOTA) for exploration based on recent advances in distributional reinforcement learning (RL). In QUOTA, decision making is based on quantiles of a value distribution, not only the mean. QUOTA provides a new dimension for exploration via making use of both optimism and pessimism of a value distribution. We demonstrate the performance advantage of QUOTA in both challenging video games and physical robot simulators.