 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning with Decorrelation
Paper and Code


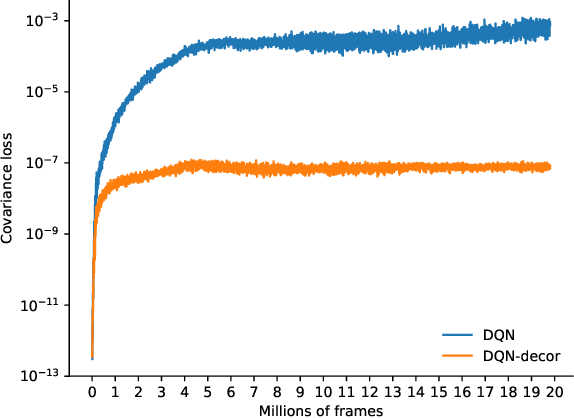
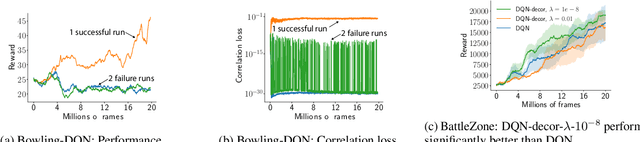
Learning an effective representation for high-dimensional data is a challenging problem in reinforcement learning (RL). Deep reinforcement learning (DRL) such as Deep Q networks (DQN) achieves remarkable success in computer games by learning deeply encoded representation from convolution networks. In this paper, we propose a simple yet very effective method for representation learning with DRL algorithms. Our key insight is that features learned by DRL algorithms are highly correlated, which interferes with learning. By adding a regularized loss that penalizes correlation in latent features (with only slight computation), we decorrelate features represented by deep neural networks incrementally. On 49 Atari games, with the same regularization factor, our decorrelation algorithms perform $70\%$ in terms of human-normalized scores, which is $40\%$ better than DQN. In particular, ours performs better than DQN on 39 games with 4 close ties and lost only slightly on $6$ games. Empirical results also show that the decorrelation method applies to Quantile Regression DQN (QR-DQN) and significantly boosts performance. Further experiments on the losing games show that our decorelation algorithms can win over DQN and QR-DQN with a fined tuned regularization factor.