 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeGrad-Ranker: Feature Ranking via $O(L)$-Time Gradients for Decision Trees
Feb 12, 2026We revisit the use of probabilistic values, which include the well-known Shapley and Banzhaf values, to rank features for explaining the local predicted values of decision trees. The quality of feature rankings is typically assessed with the insertion and deletion metrics. Empirically, we observe that co-optimizing these two metrics is closely related to a joint optimization that selects a subset of features to maximize the local predicted value while minimizing it for the complement. However, we theoretically show that probabilistic values are generally unreliable for solving this joint optimization. Therefore, we explore deriving feature rankings by directly optimizing the joint objective. As the backbone, we propose TreeGrad, which computes the gradients of the multilinear extension of the joint objective in $O(L)$ time for decision trees with $L$ leaves; these gradients include weighted Banzhaf values. Building upon TreeGrad, we introduce TreeGrad-Ranker, which aggregates the gradients while optimizing the joint objective to produce feature rankings, and TreeGrad-Shap, a numerically stable algorithm for computing Beta Shapley values with integral parameters. In particular, the feature scores computed by TreeGrad-Ranker satisfy all the axioms uniquely characterizing probabilistic values, except for linearity, which itself leads to the established unreliability. Empirically, we demonstrate that the numerical error of Linear TreeShap can be up to $10^{15}$ times larger than that of TreeGrad-Shap when computing the Shapley value. As a by-product, we also develop TreeProb, which generalizes Linear TreeShap to support all probabilistic values. In our experiments, TreeGrad-Ranker performs significantly better on both insertion and deletion metrics. Our code is available at https://github.com/watml/TreeGrad.
SFBD-OMNI: Bridge models for lossy measurement restoration with limited clean samples
Dec 18, 2025In many real-world scenarios, obtaining fully observed samples is prohibitively expensive or even infeasible, while partial and noisy observations are comparatively easy to collect. In this work, we study distribution restoration with abundant noisy samples, assuming the corruption process is available as a black-box generator. We show that this task can be framed as a one-sided entropic optimal transport problem and solved via an EM-like algorithm. We further provide a test criterion to determine whether the true underlying distribution is recoverable under per-sample information loss, and show that in otherwise unrecoverable cases, a small number of clean samples can render the distribution largely recoverable. Building on these insights, we introduce SFBD-OMNI, a bridge model-based framework that maps corrupted sample distributions to the ground-truth distribution. Our method generalizes Stochastic Forward-Backward Deconvolution (SFBD; Lu et al., 2025) to handle arbitrary measurement models beyond Gaussian corruption. Experiments across benchmark datasets and diverse measurement settings demonstrate significant improvements in both qualitative and quantitative performance.
Adaptive Context Length Optimization with Low-Frequency Truncation for Multi-Agent Reinforcement Learning
Oct 30, 2025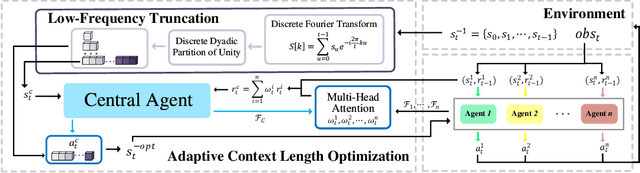
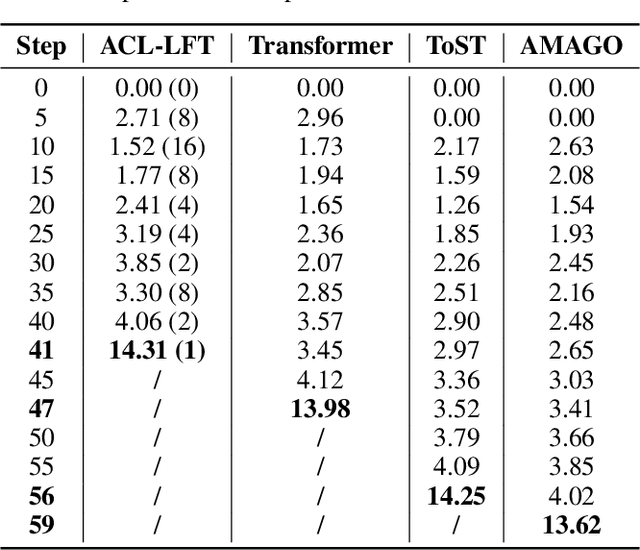
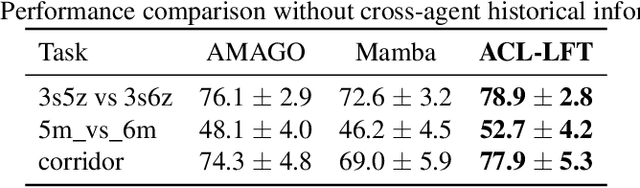
Recently, deep multi-agent reinforcement learning (MARL) has demonstrated promising performance for solving challenging tasks, such as long-term dependencies and non-Markovian environments. Its success is partly attributed to conditioning policies on large fixed context length. However, such large fixed context lengths may lead to limited exploration efficiency and redundant information. In this paper, we propose a novel MARL framework to obtain adaptive and effective contextual information. Specifically, we design a central agent that dynamically optimizes context length via temporal gradient analysis, enhancing exploration to facilitate convergence to global optima in MARL. Furthermore, to enhance the adaptive optimization capability of the context length, we present an efficient input representation for the central agent, which effectively filters redundant information. By leveraging a Fourier-based low-frequency truncation method, we extract global temporal trends across decentralized agents, providing an effective and efficient representation of the MARL environment. Extensive experiments demonstrate that the proposed method achieves state-of-the-art (SOTA) performance on long-term dependency tasks, including PettingZoo, MiniGrid, Google Research Football (GRF), and StarCraft Multi-Agent Challenge v2 (SMACv2).
Not All Samples Are Equal: Quantifying Instance-level Difficulty in Targeted Data Poisoning
Sep 08, 2025Targeted data poisoning attacks pose an increasingly serious threat due to their ease of deployment and high success rates. These attacks aim to manipulate the prediction for a single test sample in classification models. Unlike indiscriminate attacks that aim to decrease overall test performance, targeted attacks present a unique threat to individual test instances. This threat model raises a fundamental question: what factors make certain test samples more susceptible to successful poisoning than others? We investigate how attack difficulty varies across different test instances and identify key characteristics that influence vulnerability. This paper introduces three predictive criteria for targeted data poisoning difficulty: ergodic prediction accuracy (analyzed through clean training dynamics), poison distance, and poison budget. Our experimental results demonstrate that these metrics effectively predict the varying difficulty of real-world targeted poisoning attacks across diverse scenarios, offering practitioners valuable insights for vulnerability assessment and understanding data poisoning attacks.
Stochastic Forward-Backward Deconvolution: Training Diffusion Models with Finite Noisy Datasets
Feb 08, 2025



Recent diffusion-based generative models achieve remarkable results by training on massive datasets, yet this practice raises concerns about memorization and copyright infringement. A proposed remedy is to train exclusively on noisy data with potential copyright issues, ensuring the model never observes original content. However, through the lens of deconvolution theory, we show that although it is theoretically feasible to learn the data distribution from noisy samples, the practical challenge of collecting sufficient samples makes successful learning nearly unattainable. To overcome this limitation, we propose to pretrain the model with a small fraction of clean data to guide the deconvolution process. Combined with our Stochastic Forward--Backward Deconvolution (SFBD) method, we attain an FID of $6.31$ on CIFAR-10 with just $4\%$ clean images (and $3.58$ with $10\%$). Theoretically, we prove that SFBD guides the model to learn the true data distribution. The result also highlights the importance of pretraining on limited but clean data or the alternative from similar datasets. Empirical studies further support these findings and offer additional insights.
BridgePure: Revealing the Fragility of Black-box Data Protection
Dec 30, 2024Availability attacks, or unlearnable examples, are defensive techniques that allow data owners to modify their datasets in ways that prevent unauthorized machine learning models from learning effectively while maintaining the data's intended functionality. It has led to the release of popular black-box tools for users to upload personal data and receive protected counterparts. In this work, we show such black-box protections can be substantially bypassed if a small set of unprotected in-distribution data is available. Specifically, an adversary can (1) easily acquire (unprotected, protected) pairs by querying the black-box protections with the unprotected dataset; and (2) train a diffusion bridge model to build a mapping. This mapping, termed BridgePure, can effectively remove the protection from any previously unseen data within the same distribution. Under this threat model, our method demonstrates superior purification performance on classification and style mimicry tasks, exposing critical vulnerabilities in black-box data protection.
Unlocking The Potential of Adaptive Attacks on Diffusion-Based Purification
Nov 25, 2024



Diffusion-based purification (DBP) is a defense against adversarial examples (AEs), amassing popularity for its ability to protect classifiers in an attack-oblivious manner and resistance to strong adversaries with access to the defense. Its robustness has been claimed to ensue from the reliance on diffusion models (DMs) that project the AEs onto the natural distribution. We revisit this claim, focusing on gradient-based strategies that back-propagate the loss gradients through the defense, commonly referred to as ``adaptive attacks". Analytically, we show that such an optimization method invalidates DBP's core foundations, effectively targeting the DM rather than the classifier and restricting the purified outputs to a distribution over malicious samples instead. Thus, we reassess the reported empirical robustness, uncovering implementation flaws in the gradient back-propagation techniques used thus far for DBP. We fix these issues, providing the first reliable gradient library for DBP and demonstrating how adaptive attacks drastically degrade its robustness. We then study a less efficient yet stricter majority-vote setting where the classifier evaluates multiple purified copies of the input to make its decision. Here, DBP's stochasticity enables it to remain partially robust against traditional norm-bounded AEs. We propose a novel adaptation of a recent optimization method against deepfake watermarking that crafts systemic malicious perturbations while ensuring imperceptibility. When integrated with the adaptive attack, it completely defeats DBP, even in the majority-vote setup. Our findings prove that DBP, in its current state, is not a viable defense against AEs.
One Sample Fits All: Approximating All Probabilistic Values Simultaneously and Efficiently
Oct 31, 2024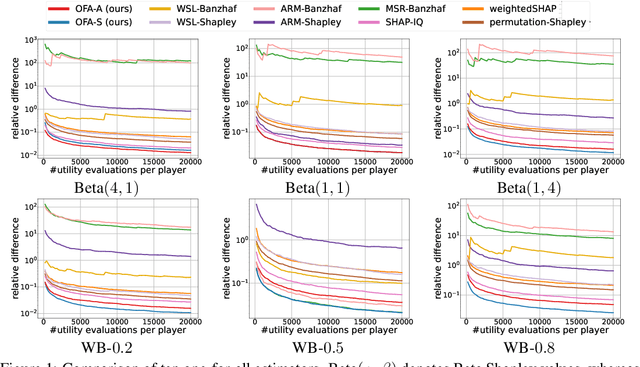

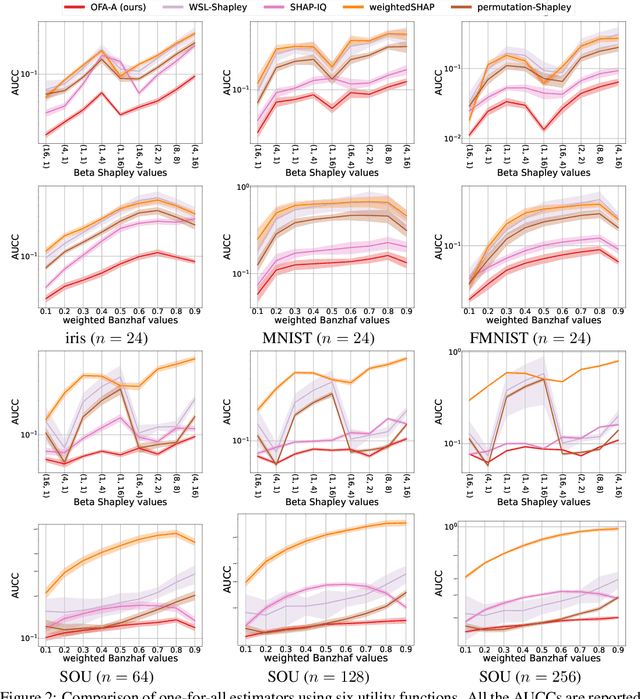
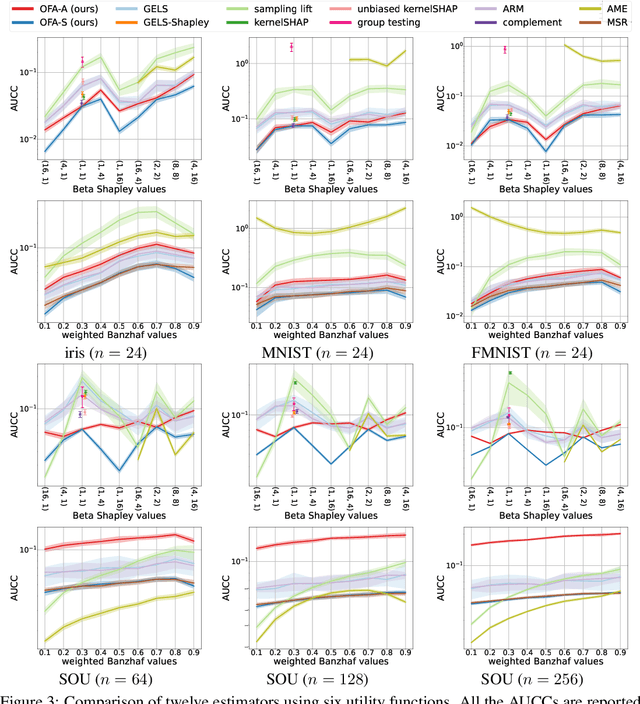
The concept of probabilistic values, such as Beta Shapley values and weighted Banzhaf values, has gained recent attention in applications like feature attribution and data valuation. However, exact computation of these values is often exponentially expensive, necessitating approximation techniques. Prior research has shown that the choice of probabilistic values significantly impacts downstream performance, with no universally superior option. Consequently, one may have to approximate multiple candidates and select the best-performing one. Although there have been many efforts to develop efficient estimators, none are intended to approximate all probabilistic values both simultaneously and efficiently. In this work, we embark on the first exploration of achieving this goal. Adhering to the principle of maximum sample reuse, we propose a one-sample-fits-all framework parameterized by a sampling vector to approximate intermediate terms that can be converted to any probabilistic value without amplifying scalars. Leveraging the concept of $ (\epsilon, \delta) $-approximation, we theoretically identify a key formula that effectively determines the convergence rate of our framework. By optimizing the sampling vector using this formula, we obtain i) a one-for-all estimator that achieves the currently best time complexity for all probabilistic values on average, and ii) a faster generic estimator with the sampling vector optimally tuned for each probabilistic value. Particularly, our one-for-all estimator achieves the fastest convergence rate on Beta Shapley values, including the well-known Shapley value, both theoretically and empirically. Finally, we establish a connection between probabilistic values and the least square regression used in (regularized) datamodels, showing that our one-for-all estimator can solve a family of datamodels simultaneously.
A Comprehensive Framework for Analyzing the Convergence of Adam: Bridging the Gap with SGD
Oct 06, 2024
Adaptive Moment Estimation (Adam) is a cornerstone optimization algorithm in deep learning, widely recognized for its flexibility with adaptive learning rates and efficiency in handling large-scale data. However, despite its practical success, the theoretical understanding of Adam's convergence has been constrained by stringent assumptions, such as almost surely bounded stochastic gradients or uniformly bounded gradients, which are more restrictive than those typically required for analyzing stochastic gradient descent (SGD). In this paper, we introduce a novel and comprehensive framework for analyzing the convergence properties of Adam. This framework offers a versatile approach to establishing Adam's convergence. Specifically, we prove that Adam achieves asymptotic (last iterate sense) convergence in both the almost sure sense and the \(L_1\) sense under the relaxed assumptions typically used for SGD, namely \(L\)-smoothness and the ABC inequality. Meanwhile, under the same assumptions, we show that Adam attains non-asymptotic sample complexity bounds similar to those of SGD.
Noise-Aware Algorithm for Heterogeneous Differentially Private Federated Learning
Jun 05, 2024High utility and rigorous data privacy are of the main goals of a federated learning (FL) system, which learns a model from the data distributed among some clients. The latter has been tried to achieve by using differential privacy in FL (DPFL). There is often heterogeneity in clients privacy requirements, and existing DPFL works either assume uniform privacy requirements for clients or are not applicable when server is not fully trusted (our setting). Furthermore, there is often heterogeneity in batch and/or dataset size of clients, which as shown, results in extra variation in the DP noise level across clients model updates. With these sources of heterogeneity, straightforward aggregation strategies, e.g., assigning clients aggregation weights proportional to their privacy parameters will lead to lower utility. We propose Robust-HDP, which efficiently estimates the true noise level in clients model updates and reduces the noise-level in the aggregated model updates considerably. Robust-HDP improves utility and convergence speed, while being safe to the clients that may maliciously send falsified privacy parameter to server. Extensive experimental results on multiple datasets and our theoretical analysis confirm the effectiveness of Robust-HDP. Our code can be found here.